字符串匹配的 Boyer-Moore 算法
上一篇文章,我介绍了 字符串匹配的KMP算法
但是,它并不是效率最高的算法,实际采用并不多。各种文本编辑器的” 查找” 功能(Ctrl+F),大多采用 Boyer-Moore 算法。
下面,我根据 Moore 教授自己的例子来解释这种算法。
1.

假定字符串为”HERE IS A SIMPLE EXAMPLE”,搜索词为”EXAMPLE”。
2.

首先,” 字符串” 与” 搜索词” 头部对齐,从尾部开始比较。
这是一个很聪明的想法,因为如果尾部字符不匹配,那么只要一次比较,就可以知道前 7 个字符肯定不是要找的结果。
我们看到,”S” 与”E” 不匹配。这时,“S” 就被称为” 坏字符”(bad character),即不匹配的字符。我们还发现,”S” 不包含在搜索词”EXAMPLE” 之中,这意味着可以把搜索词直接移到”S” 的后一位。
3.

依然从尾部开始比较,发现”P” 与”E” 不匹配,所以”P” 是” 坏字符”。但是,”P” 包含在搜索词”EXAMPLE” 之中。所以,将搜索词后移两位,两个”P” 对齐。
4.
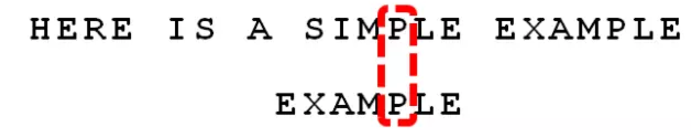
我们由此总结出 “坏字符规则”:
后移位数 = 坏字符的位置 – 搜索词中的上一次出现位置
如果” 坏字符” 不包含在搜索词之中,则上一次出现位置为 -1。
以”P” 为例,它作为” 坏字符”,出现在搜索词的第 6 位(从 0 开始编号),在搜索词中的上一次出现位置为 4,所以后移 6 – 4 = 2 位。再以前面第二步的”S” 为例,它出现在第 6 位,上一次出现位置是 -1(即未出现),则整个搜索词后移 6 – (-1) = 7 位。
5.

依然从尾部开始比较,”E” 与”E” 匹配。
6.

比较前面一位,”LE” 与”LE” 匹配。
7.
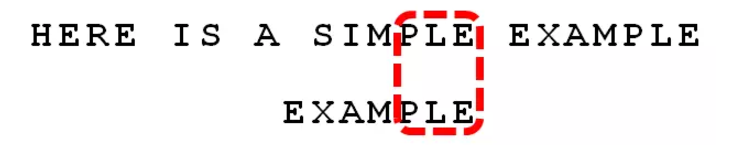
比较前面一位,”PLE” 与”PLE” 匹配。
8.

比较前面一位,”MPLE” 与”MPLE” 匹配。我们把这种情况称为” 好后缀”(good suffix),即所有尾部匹配的字符串。注意,”MPLE”、”PLE”、”LE”、”E” 都是好后缀。
9.
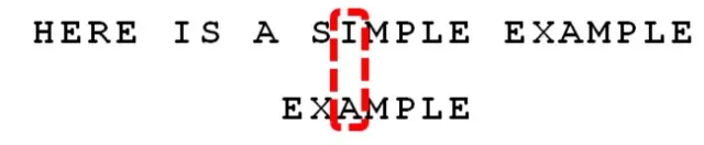
比较前一位,发现”I” 与”A” 不匹配。所以,”I” 是” 坏字符”。
10.
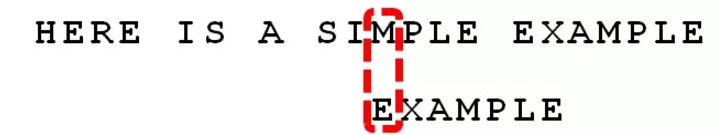
根据” 坏字符规则”,此时搜索词应该后移 2 – (-1)= 3 位。问题是,此时有没有更好的移法?
11.

我们知道,此时存在”好后缀”。所以,可以采用 “好后缀规则”:
后移位数 = 好后缀的位置 – 搜索词中的上一次出现位置
计算时,位置的取值以” 好后缀” 的最后一个字符为准。如果” 好后缀” 在搜索词中没有重复出现,则它的上一次出现位置为 -1。
所有的” 好后缀”(MPLE、PLE、LE、E)之中,只有”E” 在”EXAMPLE” 之中出现两次,所以后移 6 – 0 = 6 位。
12.
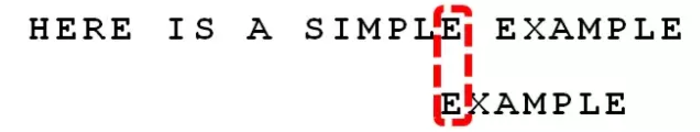
可以看到,” 坏字符规则” 只能移 3 位,” 好后缀规则” 可以移 6 位。所以,Boyer-Moore 算法的基本思想是,每次后移这两个规则之中的较大值。
更巧妙的是,这两个规则的移动位数,只与搜索词有关,与原字符串无关。因此,可以预先计算生成《坏字符规则表》和《好后缀规则表》。使用时,只要查表比较一下就可以了。
13.

继续从尾部开始比较,”P” 与”E” 不匹配,因此”P” 是” 坏字符”。根据” 坏字符规则”,后移 6 – 4 = 2 位。
14.
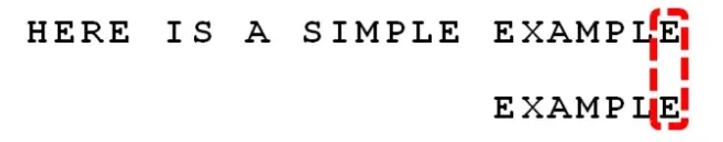
从尾部开始逐位比较,发现全部匹配,于是搜索结束。如果还要继续查找(即找出全部匹配),则根据” 好后缀规则”,后移 6 – 0 = 6 位,即头部的”E” 移到尾部的”E” 的位置。
字符串匹配的 Boyer-Moore 算法的更多相关文章
- [小专题]另一种字符串匹配的思路——Shift-And算法
吐槽:前两天打组队赛遇到一个字符串的题考了这个(见:http://acm.hdu.edu.cn/showproblem.php?pid=5972 ) 当时写了个KMP瞎搞然后TLE了(害),赛后去查了 ...
- 模式字符串匹配问题(KMP算法)
这两天又看了一遍<算法导论>上面的字符串匹配那一节,下面是实现的几个程序,可能有错误,仅供参考和交流. 关于详细的讲解,网上有很多,大多数算法及数据结构书中都应该有涉及,由于时间限制,在这 ...
- Boyer Moore算法(字符串匹配)
上一篇文章,我介绍了KMP算法. 但是,它并不是效率最高的算法,实际采用并不多.各种文本编辑器的"查找"功能(Ctrl+F),大多采用Boyer-Moore算法. Boyer-Mo ...
- 字符串匹配的Boyer-Moore(BM)算法
各种文本编辑器的"查找"功能(Ctrl+F),大多采用Boyer-Moore算法. Boyer-Moore算法不仅效率高,而且构思巧妙,容易理解.1977年,德克萨斯大学的Robe ...
- 神奇的字符串匹配:扩展KMP算法
引言 一个算是冷门的算法(在竞赛上),不过其算法思想值得深究. 前置知识 kmp的算法思想,具体可以参考 → Click here trie树(字典树). 正文 问题定义:给定两个字符串 S 和 T( ...
- 字符串匹配常见算法(BF,RK,KMP,BM,Sunday)
今日了解了一下字符串匹配的各种方法. 并对sundaysearch算法实现并且单元. 字符串匹配算法,是在实际工程中经常遇到的问题,也是各大公司笔试面试的常考题目.此算法通常输入为原字符串(strin ...
- 字符串匹配的KMP算法
~~~摘录 来源:阮一峰~~~ 字符串匹配是计算机的基本任务之一. 举例来说,有一个字符串”BBC ABCDAB ABCDABCDABDE”,我想知道,里面是否包含另一个字符串”ABCDABD”? 许 ...
- sdut 2125串结构练习--字符串匹配【两种KMP算法】
串结构练习——字符串匹配 Time Limit: 1000ms Memory limit: 65536K 有疑问?点这里^_^ 题目链接:http://acm.sdut.edu.cn/sduto ...
- 字符串匹配--Karp-Rabin算法
主要特征 1.使用hash函数 2.预处理阶段时间复杂度O(m),常量空间 3.查找阶段时间复杂度O(mn) 4.期望运行时间:O(n+m) 本文地址:http://www.cnblogs.com/a ...
随机推荐
- JS自学笔记05
JS自学笔记05 1.例题 产生随机的16进制颜色 function getColor(){ var str="#"; var arr=["0","1 ...
- YUV420、YUV422、RGB24转换
//平面YUV422转平面RGB24static void YUV422p_to_RGB24(unsigned char *yuv422[3], unsigned char *rgb24, int ...
- ReactNative如何在JS中引用原生自定义控件(rn变化太快,网上很多教程有坑,这个我研究后可用,特意分享)
直接写一个Demo例子,有相关功底的肯定明白,会对特别的地方进行提醒,本文基于https://blog.csdn.net/lintcgirl/article/details/53489490,但是按此 ...
- socket.io常用api
1. 服务端 io.on('connection',function(socket)); 监听客户端连接,回调函数会传递本次连接的socket io.sockets.emit('String',dat ...
- 通过命令“du–sk”, “du–Ask” 的区别,谈谈如何在有保护的文件系统中查看文件或文件夹的大小
我们都知道,在Windows中,右键单击一个文件或文件夹,选属性(Properties)可以看到这个文件或文件夹的大小.而这个大小是文件的原始大小,即逻辑大小(logical size).即一个1KB ...
- jQuery CSS 操作 - offset() 方法
今天在一个页面需要知道jquery版本号,来决定使用什么样的方法,有以下方式可以获取到 $.fn.jquery $.prototype.jquery 这两种方式都可以获取到jquery的版本号 --- ...
- instruments symbol name 不显示函数名!
那是因为instruments找不到编译好的dSYM 其它的什么修改配置都没什么用 最好的办法就是直接删除资源文件APP名. 资源库 -> Developer -> Xcode -> ...
- 【ASP.NET Core】浅说目录浏览
何谓“浅说”?就是一句话说不完,顶多两句话就介绍完毕,然后直接给上实例的解说方式.化繁为简,从七千年前到现在,从老祖宗到咱们,一直都在追求的理想目标,尽可能把复杂的东西变成简单的. 老周告诉你一个可以 ...
- SNF快速开发平台成长史V4.5-Spring.Net.Framework-SNF软件开发机器人
SNF快速开发平台成长史 SNF框架CS\BS 视频教程 https://pan.baidu.com/s/1dFegFKX SNF开发机器人教程:链接:https://pan.baidu.com/s/ ...
- VMVare 虚拟机使用桥接模式
VMVare 虚拟机使用桥接模式,和物理机使用同一个物理网卡,和物理主机使用同一个段的ip. 1.VMware 编辑 > 虚拟网络编辑器 2.更改配置 3.编辑名称为VMnet0 的网络(如果 ...