Kafka主题,分区,副本介绍

介绍
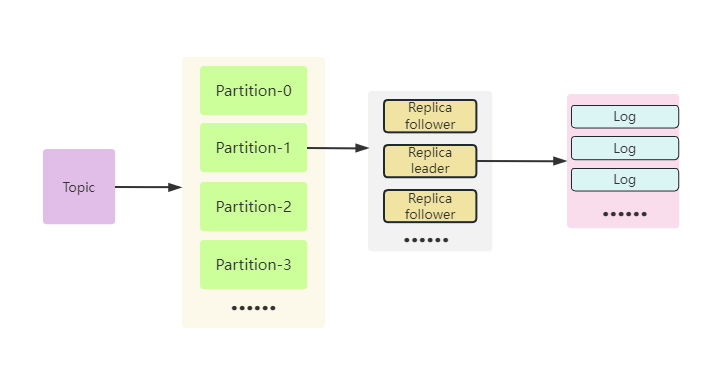
今天分享一下kafka的主题(topic),分区(partition)和副本(replication),主题是Kafka中很重要的部分,消息的生产和消费都要以主题为基础,一个主题可以对应多个分区,一个分区属于某个主题,一个分区又可以对应多个副本,副本分为leader和follower。
副本的作用是保证数据的高可用,一个副本在一个broker节点上,broker就是一个台机器或者一个kafka实例,当某个副本出现故障后,还可以使用其他副本的数据,如果只有一个副本,那么就无法保证高可用。
主题,分区实际上只是逻辑概念,真正消息存储的地方是副本的日志文件上,所以主题分区的作用是在逻辑上更加规范的管理日志文件。
主题,分区,副本关系如图所示:
创建主题分区
可以使用kafka-topics.sh创建topic,也可以使用Kafka AdminClient创建,当我们往Kafka发送消息的时候,如果指定的topic不存在,那么就会创建一个分区数为1的topic,不过这样做并不合适,我们应该规划好主题的分区,副本,然后在创建topic,这样对管理topic更加好。
kafka broker端默认设置了allow.auto.create.topics=true,所以会自动创建topic,为了更加规范和合理管理topic,我们可以将其设置为false,当然,一般情况下中我们肯定会进行手动创建topic,但是以防不确定因素,将其设置为false更保险一些。
使用kafka-topics.sh创建主题
bin/kafka-topics.sh --create --bootstrap-server 127.0.0.1:9092 --replication-factor 1 --partitions 2 --topic pig
使用Kafka AdminClient
创建topic名字为pig,分区数为1,副本数为1的分区。
Properties properties = new Properties();
properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
AdminClient adminClient = AdminClient.create(properties);
//创建topic
NewTopic newTopic = new NewTopic("pig", 4, (short) 2);
CreateTopicsResult result = adminClient.createTopics(Collections.singleton(newTopic));
需要注意的是,如果使用的是单机kafka,所以只有一个broker,如果副本设置大于1,那么就会抛出异常,因为一个副本对应一个broker。
创建了主题分区后,会在配置我们配置的日志目录(log.dirs)下生成对应的分区副本文件夹。
分区,副本详解
上面创建了分区数为4,副本为2的topic,使用命令 bin/kafka-topics.sh --describe --topic musk --bootstrap-server 127.0.0.1:9092查看分区情况。
如下名为musk的topic,分区数(PartitionCount)为4,副本数(ReplicationFactor)为2,有三个broker,kafka会将副本合理的划分到不同的机器上。

里面的数字0,1,2代表broker的唯一标识,因为在配置kafka集群的时候,三台机器的broker.id分别为0,1,2。
可知分区0的副本Leader在机器2上,副本follower在机器1上面,机器0上不存在分区0的副本,分区1的副本Leader在机器1上,副本follower在机器0上面,机器2上不存在分区1的副本,分区2和分区3以此类推。
从上面可以看出kafka要创建4个分区,每个分区对应两个副本,所以就存在8个副本,8个副本要平均分配到3台机器上上,所以就按照
3:3:2的比例分配副本,是按照平均分配的方式进行分配的。
下面我们创建分区数为4,副本为3的分区,如图所示。

可以看出,副本平均分配到了0,1,2三台机器上,每个分区有3个副本,所以4个分区有一共有12个副本。
可以看出是4个分区,每个分区3个副本,所以就有12个副本,12个副本分配到3台机器上面,所以比例是4:4:4。
AR,ISR,OSR
AR 集合(Assigned Replica set):AR 集合是指已经被分配到的分区副本集合。在 Kafka 集群中,每个分区都有若干个副本,其中一个是 leader 副本,负责处理读写请求,其他的是 follower 副本,用于备份数据和提高可用性。AR 集合就是所有被分配到的副本的集合,包括 leader 和 follower 副本。
ISR 集合(In-Sync Replica set):ISR 集合是指当前处于同步状态的副本集合。ISR 集合是 AR 集合的子集,即 ISR 集合中的副本与 leader 副本保持同步。如果一个 follower 副本与 leader 副本失去同步,那么它将从 ISR 集合中移除。
OSR 集合(Out-of-Sync Replica set):OSR 集合是指当前处于不同步状态的副本集合。OSR 集合是 AR 集合的另一个子集,即 OSR 集合中的副本与 leader 副本失去同步。这些副本可能正在追赶 leader,或者发生了某些错误导致与 leader 失去同步。在某些情况下,如果 ISR 集合缩小到了一个不可接受的程度,就需要将 OSR 集合中的副本加入 ISR 集合中,以保证可用性。
今天的分享就到这里,感谢你的观看,我们下期见!
Kafka主题,分区,副本介绍的更多相关文章
- Apache Kafka主题 - 架构和分区
1.卡夫卡话题 在这篇Kafka文章中,我们将学习Kafka主题与Kafka Architecture的整体概念.Kafka中的体系结构包括复制,故障转移以及并行处理.此外,我们还将看到创建Kafka ...
- Kafka主题体系架构-复制、故障转移和并行处理
本文讨论了Kafka主题的体系架构,讨论了如何将分区用于故障转移和并行处理. Kafka主题,日志和分区 Kafka将主题存储在日志中.主题日志分为多个分区.Kafka将日志的分区分布在多个服务器或磁 ...
- 入门大数据---Kafka深入理解分区副本机制
一.Kafka集群 Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息.每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文 ...
- Python 基于Python结合pykafka实现kafka生产及消费速率&主题分区偏移实时监控
基于Python结合pykafka实现kafka生产及消费速率&主题分区偏移实时监控 By: 授客 QQ:1033553122 1.测试环境 python 3.4 zookeeper- ...
- kafka 主题管理
对于 kafka 主题(topic)的管理(增删改查),使用最多的便是kafka自带的脚本. 创建主题 kafka提供了自带的 kafka-topics 脚本,用来帮助用户创建主题(topic). b ...
- 使用Kafka的一些简单介绍: 1集群 2原理 3 术语
目录 第一节 Kafka 集群 Kafka 集群搭建 Kafka 集群快速搭建 第二节 集群管理工具 集群管理工具 集群 Issues 第三节 使用命令操纵集群 第四节 Kafka 术语说明 第五节 ...
- kafka主题offset各种需求修改方法
简要:开发中,常常因为需要我们要认为修改消费者实例对kafka某个主题消费的偏移量.具体如何修改?为什么可行?其实很容易,有时候只要我们换一种方式思考,如果我自己实现kafka消费者,我该如何让我们的 ...
- kafka各个版本特点介绍和总结
kafka各个版本特点介绍和总结 1.1 kafka的功能特点: 分布式消息队列 消息队列的数据模型, 形成流式数据. 提供Pub/Sub方式的海量消息处理.以高容错的方式存储海量数据流.保证数据流的 ...
- kafka主题管理
若代理设置了 auto.create.topics.enable=true,这样还未创建topic就往kafka发送消息时, 会自动创建一个 ${num.partitions}个分区和{default ...
- Kafka 0.8 副本同步机制理解
Kafka的普及在很大程度上归功于它的设计和操作简单,如何自动调优Kafka副本的工作,挑战之一:如何避免follower进入和退出同步副本列表(即ISR).如果某些topic的部分partition ...
随机推荐
- 当我们的执行 java -jar xxx.jar 的时候底层到底做了什么?
大家都知道我们常用的 SpringBoot 项目最终在线上运行的时候都是通过启动 java -jar xxx.jar 命令来运行的. 那你有没有想过一个问题,那就是当我们执行 java -jar 命令 ...
- Docker进阶-Dockerfile建立一个自定义的镜像执行自定义进程
前言 docker对我来说是一个很方便的工具,,上一篇文章也写了docker基本的一些使用,这篇文章重点描述一下Dockerfile的使用,从零建立一个自己定制化的镜像,并可以执行我们需要的任务. 作 ...
- 快速入门JavaScript编程语言
目录 JS简介 JS基础 1.注释语法 2.引入js的多种方式 3.结束符号 变量与常量 let和var的区别 申明常量 const 严格模式 use strict 基本数据类型 1.数值类型(Num ...
- 《HTTP权威指南》– 6.代理
代理的概念: Web代理服务器是网络的中间实体.位于客户端和服务器之间,扮演"中间人"的角色,在各端点之间来回传送HTTP报文. 私有和共享代理: 代理服务器可以是某个客户端专用的 ...
- Java程序员除了做增删改查还能干嘛?
就以Java后端开发为例,说说不同级别程序员干的事情. 1 初级开发,大概是有3年Java开发经验. 22年底,上海,这批程序员如果学历是本科,薪资一般是8k到2w,当然如果能进好公司或互联网大厂,薪 ...
- 组策略编辑器(gpedit.msc)找不到文件解决方法
打开[此电脑]中的C盘,依次打开Windows-system32-gpedit.msc,或者输入:C:\Windows\System32\gpedit.msc,查看是否存在gpedit.msc文件(没 ...
- texlive安装与vscode环境配置
环境 系统:windows10 texlive下载 下载地址: 官网:http://tug.org/texlive/ 清华镜像源: https://mirrors.tuna.tsinghua.edu. ...
- ffmpeg第8篇:使用ffprobe采集文件信息
1. 前言 ffprobe是ffmpeg的其中一个模块,主要用于查看文件信息,咱们知道一个MP4文件其实不仅仅包含了音视频数据,还有如元数据等其它信息,但是实际上咱们关心的往往是音视频数据部分,今天来 ...
- 全志R528 系统繁忙时触摸屏I2C报错问题。
最近调试项目时遇到一个奇怪的问题. 当linux 系统繁忙时(开机,关机或APP繁忙等情况),此时按下触摸屏后, I2C总线就会报错,TP读数据失败,之后内存报错,重启. root@TinaLinux ...
- 从0开始学Java 第一期 开发前的准备
Java 学习(一) - 开发前的准备 前言 由于一些项目上的需要,我得学习一下 Java 这门语言(主要是想写Android),本人并非0基础,至少在上个学期学习了一门必修的程序设计(C语言),所以 ...