使用requests爬取梨视频、bilibili视频、汽车之家,bs4遍历文档树、搜索文档树,css选择器
今日内容概要
- 使用requests爬取梨视频
- requests+bs4爬取汽车之家
- bs4遍历文档树
- bs4搜索文档树
- css选择器
内容详细
1、使用requests爬取梨视频
# 模拟发送http请求的库:requests---》只能发送http请求----》没有解析库--》re、bs4、lxml
# requests-html:发送请求+解析xml
# 视频m3u8格式,分段---》会员试看6分钟---》只加载了6分钟
# 收费视频:视频解析
### 完整的视频文件保存到本地
# re 解析想要的数据
# import requests
# res=requests.get("https://www.pearvideo.com/")
# print(res.text)
### 爬取到的视频文件放到本地 video 目录下
# https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=24
import requests
import re
res = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=24')
# print(res.text)
# 解析出页面中所有的视频地址
video_list = re.findall('<a href="(.*?)" class="vervideo-lilink actplay">', res.text)
# print(video_list)
for video in video_list:
video_url = 'https://www.pearvideo.com/' + video
video_id = video_url.split('_')[-1]
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36',
'Referer': video_url
}
# 第一层反扒是加refer
res_video = requests.get('https://www.pearvideo.com/videoStatus.jsp?contId=%s&mrd=0.7113776105084832' % video_id,
headers=header)
mp4_url = res_video.json()['videoInfo']['videos']['srcUrl']
# 第二层反扒是把不能播放地址变成能播放地址
mp4_url = mp4_url.replace(mp4_url.split('/')[-1].split('-')[0], 'cont-%s' % video_id)
print(mp4_url)
# 下载到本地
res_video_detail = requests.get(mp4_url)
with open('./video/%s.mp4' % video_id, 'wb') as f:
for line in res_video_detail.iter_content(1024):
f.write(line)
# 单线程下载,速度不快,全是io操作,开启多线程能够显著提高速度---》使用多线程全站下载视频
# 线程池整站爬取
# 不能播放的地址
# https://video.pearvideo.com/mp4/third/20220314/ 1652060493892 -10097838-231626-hd.mp4 # 不正常地址
# https://video.pearvideo.com/mp4/third/20220314/ cont-1754713 -10097838-231626-hd.mp4 # 正常地址
# mp4_url='https://video.pearvideo.com/mp4/third/20220314/ 1652060493892 -10097838-231626-hd.mp4'
# mp4_url=mp4_url.replace(mp4_url.split('/')[-1].split('-')[0],'cont-%s'%video_id)
2、爬取bilibili视频
# 爬取的b站视频保存到本地 是分为两个文件:
视频文件
音频文件
# 通过第三方软件做了整合之后才是完整的视频
# 视频去水印--》fmmpeg--》加水印,拼接裁剪,抠图,转码。。。
# 装上使用python来调用处理
# 导入requests模块,模拟发送请求
import requests
# 导入json
import json
# 导入re
import re
# 定义请求头
headers = {
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.5',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
}
# 正则表达式,根据条件匹配出值
def my_match(text, pattern):
match = re.search(pattern, text)
print(match.group(1))
print()
return json.loads(match.group(1))
def download_video(old_video_url, video_url, audio_url, video_name):
headers.update({"Referer": old_video_url})
print("开始下载视频:%s" % video_name)
video_content = requests.get(video_url, headers=headers)
print('%s视频大小:' % video_name, video_content.headers['content-length'])
audio_content = requests.get(audio_url, headers=headers)
print('%s音频大小:' % video_name, audio_content.headers['content-length'])
# 下载视频开始
received_video = 0
with open('%s_video.mp4' % video_name, 'ab') as output:
while int(video_content.headers['content-length']) > received_video:
headers['Range'] = 'bytes=' + str(received_video) + '-'
response = requests.get(video_url, headers=headers)
output.write(response.content)
received_video += len(response.content)
# 下载视频结束
# 下载音频开始
audio_content = requests.get(audio_url, headers=headers)
received_audio = 0
with open('%s_audio.mp4' % video_name, 'ab') as output:
while int(audio_content.headers['content-length']) > received_audio:
# 视频分片下载
headers['Range'] = 'bytes=' + str(received_audio) + '-'
response = requests.get(audio_url, headers=headers)
output.write(response.content)
received_audio += len(response.content)
# 下载音频结束
return video_name
if __name__ == '__main__':
# 换成你要爬取的视频地址
url = 'https://www.bilibili.com/video/BV17F411M7pQ'
# 发送请求,拿回数据
res = requests.get(url, headers=headers)
# 视频详情json
playinfo = my_match(res.text, '__playinfo__=(.*?)</script><script>')
# 视频内容json
initial_state = my_match(res.text, r'__INITIAL_STATE__=(.*?);\(function\(\)')
# 视频分多种格式,直接取分辨率最高的视频 1080p
video_url = playinfo['data']['dash']['video'][0]['baseUrl']
# 取出音频地址
audio_url = playinfo['data']['dash']['audio'][0]['baseUrl']
video_name = initial_state['videoData']['title']
print('视频名字为:video_name')
print('视频地址为:', video_url)
print('音频地址为:', audio_url)
download_video(url, video_url, audio_url, video_name)
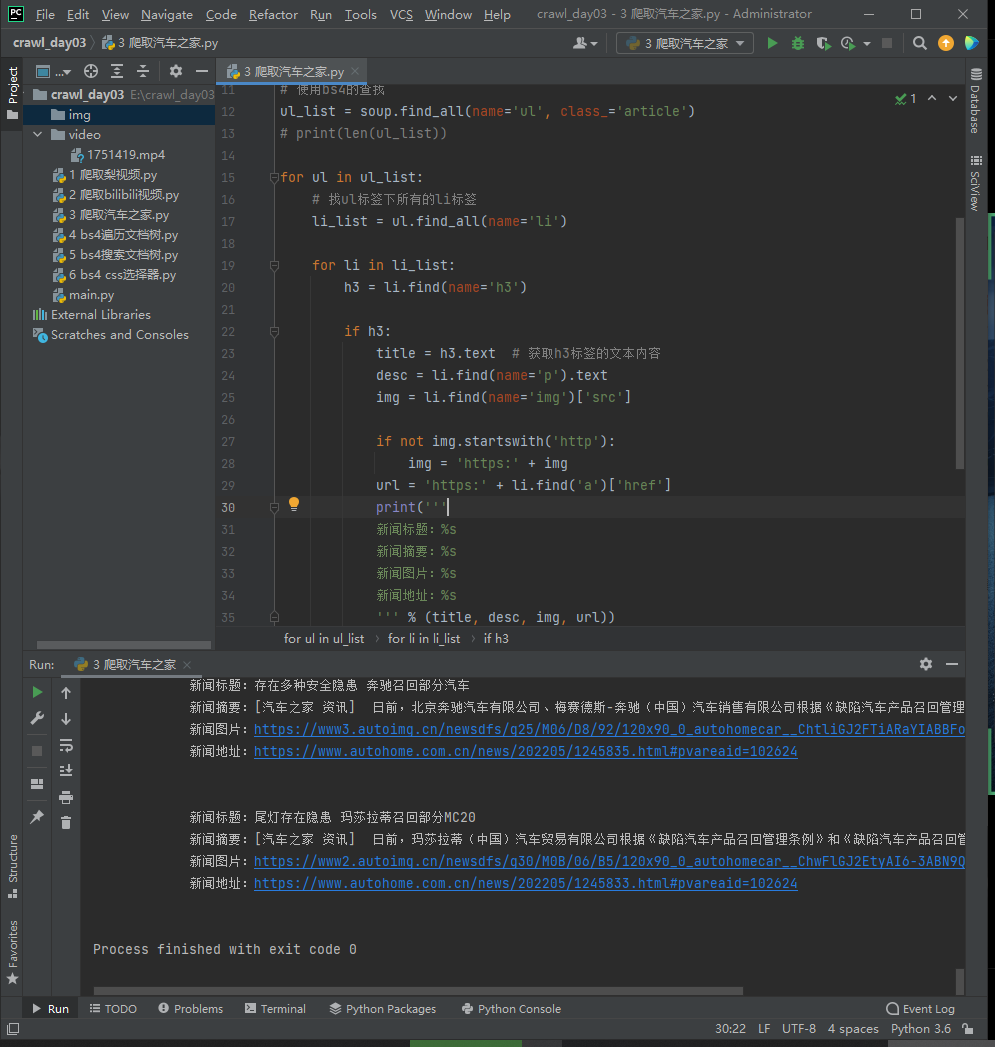
3、requests+bs4爬取汽车之家
### 爬取到的图片都会保存到本地
### 也可以在pycharm直接打印出 新闻地址 和 图片地址 单独访问
import requests
# pip3 install beautifulsoup4
from bs4 import BeautifulSoup
res = requests.get('https://www.autohome.com.cn/news/1/#liststart')
# print(res.text)
# html.parser bs4默认的解析库
soup = BeautifulSoup(res.text, 'html.parser')
# 使用bs4的查找
ul_list = soup.find_all(name='ul', class_='article')
# print(len(ul_list))
for ul in ul_list:
# 找ul标签下所有的li标签
li_list = ul.find_all(name='li')
for li in li_list:
h3 = li.find(name='h3')
if h3:
title = h3.text # 获取h3标签的文本内容
desc = li.find(name='p').text
img = li.find(name='img')['src']
if not img.startswith('http'):
img = 'https:' + img
url = 'https:' + li.find('a')['href']
print('''
新闻标题:%s
新闻摘要:%s
新闻图片:%s
新闻地址:%s
''' % (title, desc, img, url))
# 把图片保存到本地
res_img = requests.get(img)
img_name = img.split('/')[-1]
with open('./img/%s' % img_name, 'wb') as f:
for line in res_img.iter_content(1024):
f.write(line)
# 把数据存到数据库 pymysql写入数据库--》建库建表--》cursor.exec(insert ..)-->commit
4、bs4遍历文档树(快速定位查找)
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" id="id_p">lqz<b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
### html.parser 内置的,速度一般,容错能力强
# lxml 第三方的,速度快,容错能力强
# soup = BeautifulSoup(html_doc, 'html.parser')
# pip3 install lxml
soup = BeautifulSoup(html_doc, 'lxml')
# print(soup.prettify()) # 对html进行美化 美化成完整的书写格式
# 1 遍历文档树之 . 遍历 速度快
print(soup.title)
print(soup.body.p)
print(soup.body.p.b)
# 2、获取标签的名称
print(soup.title.name) # title
print(soup.body.name) # body
# 3、获取标签的属性
print(soup.body.p) # 找 p标签 速度快些
print(soup.p['class']) # ['title'] 因为class可能有多个,所以是列表
print(soup.p['id']) # id_p
print(soup.p.attrs) # {'class': ['title'], 'id': 'id_p'} 所有属性放到字典中
# 4、获取标签的内容--文本内容
print(soup.p.text) # lqzThe Dormouse's story 当前标签和子子孙的文本内容拼到一起
print(soup.p.string) # None 当前标签只有文本或只有一个子有文本才拿出来,如果有多个子子孙孙,返回None
print(list(soup.p.strings)) # ['lqz', "The Dormouse's story"] 把子子孙孙的文本内容放到generator
# 5、嵌套选择
# 可以连续点嵌套选择
print(soup.head.title.string) # The Dormouse's story
# 6、子节点、子孙节点
print(soup.p.contents) # p下所有子节点,放到列表中
print(list(soup.p.children)) # 得到一个迭代器,包含p下所有子节点,跟contents本质一样,只是节约内存
print(list(soup.p.descendants)) # 获取子孙节点,p下所有的标签都会选择出来 子子孙孙
for i, child in enumerate(soup.p.children):
print(i, child)
for i, child in enumerate(soup.p.descendants):
print(i, child)
# 7、父节点、祖先节点
print(soup.a.parent) # 获取a标签的父节点
print(list(soup.a.parents)) # 找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲...
# 8、兄弟节点
print(soup.a.next_sibling) # 下一个兄弟
print(soup.a.previous_sibling) # 上一个兄弟
print(list(soup.a.next_siblings)) # 下面的兄弟们=>生成器对象
print(soup.a.previous_siblings) # 上面的兄弟们=>生成器对象
### 重点记忆:
. 遍历
取属性 [] attrrs.get()
取文本 text string strings
5、bs4搜索文档树
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" id="id_p">lqz<b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
##### 五种过滤器: 字符串、正则表达式、列表、True、方法
# find:找到第一个 find_all:找所有
# 1、字符串 --->value值是字符串
res = soup.find_all(name='p')
# res = soup.find(id='id_p')
# res = soup.find_all(class_='story')
# res = soup.find_all(name='p', class_='story') # and条件
# res = soup.find(name='a', id='link2').text
# res = soup.find(name='a', id='link2').attrs.get('href')
# res = soup.find(attrs={'id': 'link2', 'class': 'sister'}).attrs.get('href')
print(res)
# 2、正则表达式--->value是正则表达式
import re
# res = soup.find_all(name=re.compile('^b'))
# res = soup.find_all(href=re.compile('^http'))
res = soup.find_all(class_=re.compile('^s'))
print(res)
# 3、列表 value值是列表
# res = soup.find_all(name=['body', 'a'])
# res = soup.find_all(class_=['sister', 'story'])
res = soup.find_all(id=['link2', 'link3'])
print(res)
# 4、True value值是True
# res = soup.find_all(name=True)
# res = soup.find_all(id=True)
res = soup.find_all(href=True)
print(res)
# 5、方法
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
print(soup.find_all(name=has_class_but_no_id)) # 有class但是没有id的标签
### 补充总结:
# 1 html页面中,只要有的东西,通过bs4都可以解析出来
# 2 遍历文档树+搜索文档树混用
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
print(soup.find(name=has_class_but_no_id).a.text)
# 3 find_all的其他参数limit:限制取几条 recursive:是否递归查找
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
res = soup.find_all(name=has_class_but_no_id, limit=1)
print(res)
res = soup.find_all(name='a', recursive=False) # 不递归查找,速度快,只找一层
print(res)
6、css选择器
### css,xpath选择器是通用的---》基本所有的解析库(bs4,lxml,pyquery,selenium的解析库)--->都支持css选择器-->css在前端通用
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" id="id_p">lqz<b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc, 'lxml')
# soup.select() # 找所有
# soup.select_one() # 找一个
'''
div 找div标签
div>a 找div下的紧邻的a
div a 找div下的子子孙孙的a
.sister 找类名为sister的标签
#id_p 找id为id_p的标签
'''
# res = soup.select('#id_p')
# res = soup.select('.sister')
res = soup.select_one('.story>a').attrs.get('href')
print(res)
# 终极大招
import requests
response = requests.get('https://www.runoob.com/cssref/css-selectors.html')
soup = BeautifulSoup(response.text, 'lxml')
res = soup.select_one('#content > table > tbody > tr:nth-child(2) > td:nth-child(3)').text # 找到标签 右键 copy--selector
print(res)
# 只要页面中有的通过bs4都能解析出来
使用requests爬取梨视频、bilibili视频、汽车之家,bs4遍历文档树、搜索文档树,css选择器的更多相关文章
- requests爬取梨视频主页所有视频
爬取梨视频步骤: 1.爬取梨视频主页,获取主页所有的详情页链接 - url: https://www.pearvideo.com/ - 1) 往url发送请求,获取主页的html文本 - 2) 解析并 ...
- Python3 多线程爬取梨视频
多线程爬取梨视频 from threading import Thread import requests import re # 访问链接 def access_page(url): respons ...
- python爬虫实践——爬取“梨视频”
一.爬虫的基本过程: 1.发送请求(请求库:request,selenium) 2.获取响应数据()服务器返回 3.解析并提取数据(解析库:re,BeautifulSoup,Xpath) 4.保存数据 ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 爬虫---爬取b站小视频
前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~ 分析b站小视频 1.进入 ...
- Python爬虫训练:爬取酷燃网视频数据
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 项目目标 爬取酷燃网视频数据 https://krcom.cn/ 环境 Py ...
- 教你用python爬取抖音app视频
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思 ...
- requests爬取百度音乐
使用requests爬取百度音乐,我想把当前热门歌手的音乐信息爬下来. 首先进行url分析,可以看到: 歌手网页: 薛之谦网页: 可以看到,似乎这些路劲的获取一切都很顺利,然后可以写代码: # -*- ...
- Requests爬取网页的编码问题
Requests爬取网页的编码问题 import requests from requests import exceptions def getHtml(): try: r=requests.get ...
随机推荐
- MyBatis 实现一对一有几种方式?具体怎么操作的?
有联合查询和嵌套查询,联合查询是几个表联合查询,只查询一次, 通过在 resultMap 里面配置 association 节点配置一对一的类就可以完成: 嵌套查询是先查一个表,根据这个表里面的结果的 ...
- 区分 BeanFactory 和 ApplicationContext?
BeanFactory ApplicationContext 它使用懒加载 它使用即时加载 它使用语法显式提供资源对象 它自己创建和管理资源对象 不支持国际化 支持国际化 不支持基于依赖的注解 支持基 ...
- 深入 x64
本篇原文为 X64 Deep Dive,如果有良好的英文基础的能力,可以点击该链接进行阅读.本文为我个人:寂静的羽夏(wingsummer) 中文翻译,非机翻,著作权归原作者所有. 由于原文十 ...
- (stm32学习总结)—对寄存器的理解 _
芯片里面有什么 我们看到的 STM32 芯片是已经封装好的成品,主要由内核和片上外设组成.若与电脑类比,内核与外设就如同电脑上的 CPU 与主板.内存.显卡.硬盘的关系.STM32F103 采用的是 ...
- 编译器如何处理C++不同类中同名函数(参数类型个数都相同)
转载请注明出处,版权归作者所有 lyzaily@126.com yanzhong.lee 作者按: 从这篇文章中,我们主要会认识到一下几点: 一.不类中的特征标相同的同名函数,它们是不同的函数,原因就 ...
- Androd点击一个选框取消其他选框
说明: 我做的体温填报系统需要在填报体温时勾选有无特殊情况 当勾选'无'时需要将用户勾选的其他选框取消 当勾选其他选框时需要将'无'这个选框取消 效果: 代码: addTem.xml <Line ...
- 项目中常用到的布局 flex
1. 没header,footer固定 html<div class="page"> <div class="top"> <div ...
- (动态模型类,我的独创)Django的原生ORM框架如何支持MongoDB,同时应对客户使用时随时变动字段
1.背景知识 需要开发一个系统,处理大量EXCEL表格信息,各种类别.表格标题多变,因此使用不需要预先设计数据表结构的MongoDB,即NoSQL.一是字段不固定,二是同名字段可以存储不同的字段类型. ...
- SpringBoot-总结
SpringBoot一站式开发 官网:https://spring.io/projects/spring-boot Spring Boot可以轻松创建独立的.基于Spring的生产级应用程序,它可以让 ...
- 某空间下的令牌访问产生过程--Kubernetes Dashboard(k8s-Dashboard)
在面试中发现,有些运维人员基本的令牌访问方式都不知道,下面介绍下令牌的产生过程 某个空间下的令牌访问产生过程(空间名称为cc) ###创建命名空间[root@vms61 ccadmin]# kubec ...