大数据学习之路又之从csv文件到sql文件的操作过程
根据前几天的测试,简单的做个总结
csv文件的字段说明:

1.将csv文件上传到虚拟机中
在SecureCRT中点击 ,创建目录,直接把文件从本地拖拽进去
,创建目录,直接把文件从本地拖拽进去

我放在了/linmob/data的路径下,所以文件的位置是/linmob/data/sales_sample_20170310.csv
2.在hive命令行中建表,表名要与csv文件中的一一对应,人生建议字段类型都选择varchar
hive
create table sales_sample_20170310(day_id varchar(30),sale_nbr varchar(30),buy_nbr varchar(30),cnt varchar(30),round varchar(30)) row format delimited fields terminated by ',' ;

3.导入数据 其中的路径 '/linmob/data/sales_sample_20170310.csv'和表名 sales_sample_20170310要修改成自己的
load data local inpath '/linmob/data/sales_sample_20170310.csv' overwrite into table sales_sample_20170310;

4.select验证数据是否导入,因为数据量大,一定要limit
select * from sales_sample_20170310 limit 10;
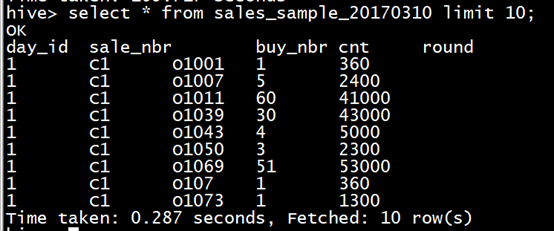
5.退出hive命令行,进入mysql,建表
exit;
mysql -uroot -proot
create table sales_sample_20170310(day_id varchar(30), sale_nbr varchar(30),buy_nbr varchar(30),cnt varchar(30),round varchar(30))charset utf8 collate utf8_general_ci;

6.退出mqsql,进入sqoop的bin目录下,到出数据到mysql数据库中,其中ip地址192.168.111.100、mysql数据库名tab、mysql用户名和密码root、mysql表名 sales_sample_20170310、hive路径名 /user/hive/warehouse/sales_sample_20170310都要换成自己的
hive路径名不清楚?到9870可以找到
./sqoop export --connect "jdbc:mysql://192.168.111.100:3306/tab?characterEncoding=UTF-8" --username root --password root --table sales_sample_20170310 --export-dir /user/hive/warehouse/sales_sample_20170310 --input-null-string "\\\\N" --input-null-non-string "\\\\N" --input-fields-terminated-by "," --input-lines-terminated-by "\\n" -m 1
7.数据导出
大数据学习之路又之从csv文件到sql文件的操作过程的更多相关文章
- 大数据学习之路又之从小白到用sqoop导出数据
写这篇文章的目的是总结自己学习大数据的经验,以为自己走了很多弯路,从迷茫到清晰,真的花费了很多时间,希望这篇文章能帮助到后面学习的人. 一.配置思路 安装linux虚拟机--->创建三台虚拟机- ...
- 大数据学习之路------借助HDP SANDBOX开始学习
一开始... 一开始知道大数据这个概念的时候,只是感觉很高大上,引起了我的兴趣.当时也不知道,这个东西是做什么的,有什么用,当然现在看来也是很模糊的样子,但是的确比一开始强了不少. 所以学习的过程可能 ...
- 大数据学习之路(1)Hadoop生态体系结构
Hadoop的核心是HDFS和MapReduce,hadoop2.0还包括YARN. Hadoop1.x的生态系统: Hadoop2.x引入YARN: HDFS(Hadoop分布式文件系统)源自于Go ...
- 大数据学习之路之HBASE
Hadoop之HBASE 一.HBASE简介 HBase是一个开源的.分布式的,多版本的,面向列的,半结构化的NoSql数据库,提供高性能的随机读写结构化数据的能力.它可以直接使用本地文件系统,也可以 ...
- 大数据学习之路之Hadoop
Hadoop介绍 一.简介 Hadoop是一个开源的分布式计算平台,用于存储大数据,并使用MapReduce来处理.Hadoop擅长于存储各种格式的庞大的数据,任意的格式甚至非结构化的处理.两个核心: ...
- 大数据学习之路-phoenix
1.phoenix安装 ------------------ 1.安装phoenix a)下载apache-phoenix-4.10.0-HBase-1.2-bin.tar.gz 下载网址:htt ...
- 大数据学习笔记——HDFS理论知识之编辑日志与镜像文件
HDFS文件系统——编辑日志和镜像文件详细介绍 我们知道,启动Hadoop之后,在主节点下会产生Namenode,即名称节点进程,该节点的目录下会保存一份元数据,用来记录文件的索引,而在从节点上即Da ...
- 大数据学习之路-hdfs
1.什么是hadoop hadoop中有3个核心组件: 分布式文件系统:HDFS —— 实现将文件分布式存储在很多的服务器上 分布式运算编程框架:MAPREDUCE —— 实现在很多机器上分布式并行运 ...
- 大数据学习之路——MySQL基础(一)——MySQL的基础知识与常见操作
一.存储引擎 1.含义 存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建.查询.更新和删除数据.不同的存储引擎提供不同的存储机制.索引技巧.锁定水平等功能,使用不同的存储引 ...
随机推荐
- while + else 使用,while死循环与while的嵌套,for循环基本使用,range关键字,for的循环补充(break、continue、else) ,for循环的嵌套,基本数据类型及内置方法
今日内容 内容概要 while + else 使用 while死循环与while的嵌套 for循环基本使用 range关键字 for的循环补充(break.continue.else) for循环的嵌 ...
- ws请求定时
heartChechInit() { const _this = this; // 设置统筹管理 let heartCheck = { timer: ...
- Hive数仓
分层设计 ODS(Operational Data Store):数据运营层 "面向主题的"数据运营层,也叫ODS层,是最接近数据源中数据的一层,数据源中的数据,经过抽取.洗净. ...
- java 中判断输入是否合法 if (变量名.hasNextInt())
//案例: Scanner sc = new Scanner(System.in); System.out.println("你选择了新修改商品功能!"); System.out. ...
- SoftwareTeacher直播自我感想
今天老师发布了一个链接直播是关于:同学们聊聊学习软件工程,CS 课程的问题下面是我的个人感悟和笔记 一.编程技术的提升 编程并不是一件很难的事情,就如开车一样,只有多加练习,自己的技术才能提升上去.拿 ...
- CF802O题解
太厉害啦,出题人究竟是怎么想到的. 首先这题很显然可以使用费用流:对于 \(i \leq j\),连接一条边 \((i,j+n)\),流量为 \(1\),费用为 \(a_i+b_j\).最后连接 \( ...
- Spring——自动装配的三种实现方式
依赖注入的本质是装配,装配是依赖注入的具体行为 spring会在上下文中自动寻找,并自动给bean装配属性 自动装配的三种方式 (1).在xml中显式的装配 (2).在java中显式的装配 (3).隐 ...
- 常用命令行指令 Windows & Linux
一.Linux linux常用命令详解:https://www.cnblogs.com/yuncong/p/10247583.html 挂载U盘到linux一个文件夹中 二.Windows 1.查看电 ...
- [源码解析] TensorFlow 分布式环境(4) --- WorkerCache
[源码解析] TensorFlow 分布式环境(4) --- WorkerCache 目录 [源码解析] TensorFlow 分布式环境(4) --- WorkerCache 1. WorkerCa ...
- 不想业务被中断?快来解锁华为云RDS for MySQL新特性
摘要:新特性上线!华为云RDS for MySQL又添新技能,实力保障业务连续性. 本文分享自华为云社区<不想业务被中断?快来解锁华为云RDS for MySQL新特性>,作者:Gauss ...