取出预训练模型中间层的输出(pytorch)
1 遍历子模块直接提取
对于简单的模型,可以采用直接遍历子模块的方法,取出相应name模块的输出,不对模型做任何改动。该方法的缺点在于,只能得到其子模块的输出,而对于使用nn.Sequensial()中包含很多层的模型,无法获得其指定层的输出。
示例 resnet18取出layer1的输出
from torchvision.models import resnet18
import torch model = resnet18(pretrained=True)
print("model:", model)
out = []
x = torch.randn(1, 3, 224, 224)
return_layer = "layer1"
for name, module in model.named_children():
x = module(x)
if name == return_layer:
out.append(x.data)
break
print(out[0].shape) # torch.Size([1, 64, 56, 56])
2 IntermediateLayerGetter类
torchvison中提供了IntermediateLayerGetter类,该方法同样只能得到其子模块的输出,而对于使用nn.Sequensial()中包含很多层的模型,无法获得其指定层的输出。
from torchvision.models._utils import IntermediateLayerGetter
IntermediateLayerGetter类的pytorch源码
class IntermediateLayerGetter(nn.ModuleDict):
"""
Module wrapper that returns intermediate layers from a model It has a strong assumption that the modules have been registered
into the model in the same order as they are used.
This means that one should **not** reuse the same nn.Module
twice in the forward if you want this to work. Additionally, it is only able to query submodules that are directly
assigned to the model. So if `model` is passed, `model.feature1` can
be returned, but not `model.feature1.layer2`. Args:
model (nn.Module): model on which we will extract the features
return_layers (Dict[name, new_name]): a dict containing the names
of the modules for which the activations will be returned as
the key of the dict, and the value of the dict is the name
of the returned activation (which the user can specify).
"""
_version = 2
__annotations__ = {
"return_layers": Dict[str, str],
} def __init__(self, model: nn.Module, return_layers: Dict[str, str]) -> None:
if not set(return_layers).issubset([name for name, _ in model.named_children()]):
raise ValueError("return_layers are not present in model")
orig_return_layers = return_layers
return_layers = {str(k): str(v) for k, v in return_layers.items()} # 重新构建backbone,将没有使用到的模块全部删掉
layers = OrderedDict()
for name, module in model.named_children():
layers[name] = module
if name in return_layers:
del return_layers[name]
if not return_layers:
break super(IntermediateLayerGetter, self).__init__(layers)
self.return_layers = orig_return_layers def forward(self, x: Tensor) -> Dict[str, Tensor]:
out = OrderedDict()
for name, module in self.items():
x = module(x)
if name in self.return_layers:
out_name = self.return_layers[name]
out[out_name] = x
return out
示例 使用IntermediateLayerGetter类 改 resnet34+unet 完整代码见gitee
import torch
from torchvision.models import resnet18, vgg16_bn, resnet34
from torchvision.models._utils import IntermediateLayerGetter model = resnet34()
stage_indices = ['relu', 'layer1', 'layer2', 'layer3', 'layer4']
return_layers = dict([(str(j), f"stage{i}") for i, j in enumerate(stage_indices)])
model= IntermediateLayerGetter(model, return_layers=return_layers)
input = torch.randn(1, 3, 224, 224)
output = model(input)
print([(k, v.shape) for k, v in output.items()])
3 create_feature_extractor函数
使用create_feature_extractor方法,创建一个新的模块,该模块将给定模型中的中间节点作为字典返回,用户指定的键作为字符串,请求的输出作为值。该方法比 IntermediateLayerGetter方法更通用, 不局限于获得模型第一层子模块的输出。比如下面的vgg,池化层都在子模块feature中,上面的方法无法取出,因此推荐使用create_feature_extractor方法。
示例 FCN论文中以vgg为backbone,分别取出三个池化层的输出
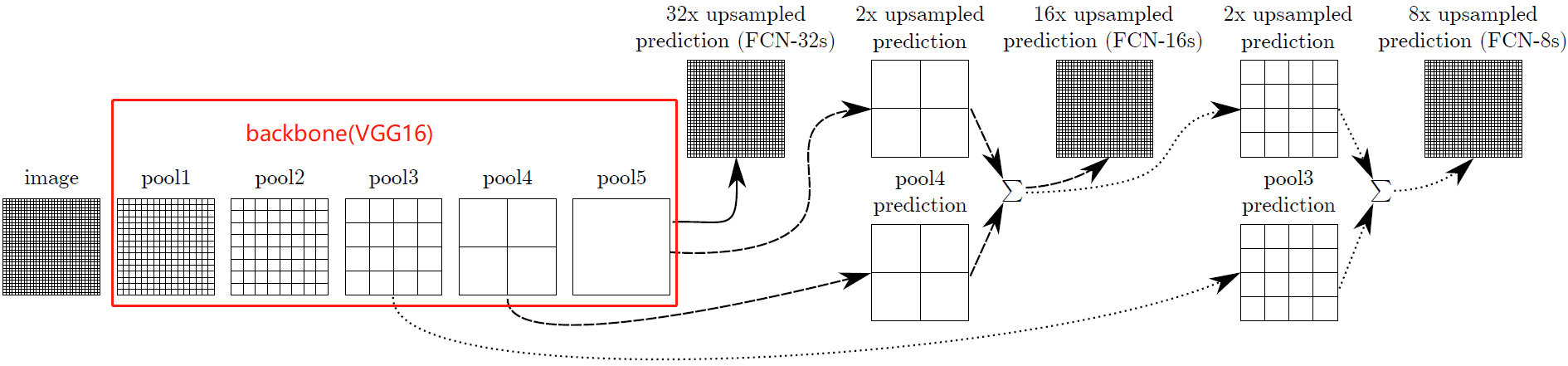
import torch
from torchvision.models import vgg16_bn
from torchvision.models.feature_extraction import create_feature_extractor model = vgg16_bn()
model = create_feature_extractor(model, {"features.43": "pool5", "features.33": "pool4", "features.23": "pool3"})
input = torch.randn(1, 3, 224, 224)
output = model(input)
print([(k, v.shape) for k, v in output.items()])
4 hook函数
hook函数是程序中预定义好的函数,这个函数处于原有程序流程当中(暴露一个钩子出来)。我们需要再在有流程中钩子定义的函数块中实现某个具体的细节,需要把我们的实现,挂接或者注册(register)到钩子里,使得hook函数对目标可用。hook 是一种编程机制,和具体的语言没有直接的关系。
Pytorch的hook编程可以在不改变网络结构的基础上有效获取、改变模型中间变量以及梯度等信息。在pytorch中,Module对象有register_forward_hook(hook) 和 register_backward_hook(hook) 两种方法,两个的操作对象都是nn.Module类,如神经网络中的卷积层(nn.Conv2d),全连接层(nn.Linear),池化层(nn.MaxPool2d, nn.AvgPool2d),激活层(nn.ReLU)或者nn.Sequential定义的小模块等。register_forward_hook是获取前向传播的输出的,即特征图或激活值; register_backward_hook是获取反向传播的输出的,即梯度值。(这边只讲register_forward_hook,其余见链接)
示例 获取resnet18的avgpool层的输入输出
import torch
from torchvision.models import resnet18 model = resnet18()
fmap_block = dict() # 装feature map
def forward_hook(module, input, output):
fmap_block['input'] = input
fmap_block['output'] = output layer_name = 'avgpool'
for (name, module) in model.named_modules():
if name == layer_name:
module.register_forward_hook(hook=forward_hook) input = torch.randn(64, 3, 224, 224)
output = model(input)
print(fmap_block['input'][0].shape)
print(fmap_block['output'].shape)
参考
2. Pytorch的hook技术——获取预训练/已训练好模型的特定中间层输出
取出预训练模型中间层的输出(pytorch)的更多相关文章
- 【tf.keras】tf.keras加载AlexNet预训练模型
目录 从 PyTorch 中导出模型参数 第 0 步:配置环境 第 1 步:安装 MMdnn 第 2 步:得到 PyTorch 保存完整结构和参数的模型(pth 文件) 第 3 步:导出 PyTorc ...
- Pytorch——BERT 预训练模型及文本分类
BERT 预训练模型及文本分类 介绍 如果你关注自然语言处理技术的发展,那你一定听说过 BERT,它的诞生对自然语言处理领域具有着里程碑式的意义.本次试验将介绍 BERT 的模型结构,以及将其应用于文 ...
- pytorch预训练模型的下载地址以及解决下载速度慢的方法
https://github.com/pytorch/vision/tree/master/torchvision/models 几乎所有的常用预训练模型都在这里面 总结下各种模型的下载地址: 1 R ...
- PyTorch保存模型与加载模型+Finetune预训练模型使用
Pytorch 保存模型与加载模型 PyTorch之保存加载模型 参数初始化参 数的初始化其实就是对参数赋值.而我们需要学习的参数其实都是Variable,它其实是对Tensor的封装,同时提供了da ...
- [Pytorch]Pytorch加载预训练模型(转)
转自:https://blog.csdn.net/Vivianyzw/article/details/81061765 东风的地方 1. 直接加载预训练模型 在训练的时候可能需要中断一下,然后继续训练 ...
- 【小白学PyTorch】5 torchvision预训练模型与数据集全览
文章来自:微信公众号[机器学习炼丹术].一个ai专业研究生的个人学习分享公众号 文章目录: 目录 torchvision 1 torchvision.datssets 2 torchvision.mo ...
- pytorch中修改后的模型如何加载预训练模型
问题描述 简单来说,比如你要加载一个vgg16模型,但是你自己需要的网络结构并不是原本的vgg16网络,可能你删掉某些层,可能你改掉某些层,这时你去加载预训练模型,就会报错,错误原因就是你的模型和原本 ...
- XLNet预训练模型,看这篇就够了!(代码实现)
1. 什么是XLNet XLNet 是一个类似 BERT 的模型,而不是完全不同的模型.总之,XLNet是一种通用的自回归预训练方法.它是CMU和Google Brain团队在2019年6月份发布的模 ...
- PyTorch-网络的创建,预训练模型的加载
本文是PyTorch使用过程中的的一些总结,有以下内容: 构建网络模型的方法 网络层的遍历 各层参数的遍历 模型的保存与加载 从预训练模型为网络参数赋值 主要涉及到以下函数的使用 add_module ...
- 最强 NLP 预训练模型库 PyTorch-Transformers 正式开源:支持 6 个预训练框架,27 个预训练模型
先上开源地址: https://github.com/huggingface/pytorch-transformers#quick-tour 官网: https://huggingface.co/py ...
随机推荐
- MindManager离线安装包官网下载
软件官网:https://www.mindjet.com/ 注意:不建议在思杰马克丁及其相关合作网站下载该软件,更不建议在其旗下站点购买该软件授权. 目前来说,官网正常下载的话它会要求你填写一些信息, ...
- 端口被占用 for mac
启用项目提示端口被占用 解决方案: lsof -i : 3010 杀死占用的进程 kill -9 4804 重新启动
- Miller-Rabin素性判定算法
Miller-Rabin素性判定算法是一种基于概率的判定算法,每次判定n是素数的正确性概率至少为75%,出错的概率小于25%. 如果对n进行k次素性检测,如果结果n为素数,那么n为合数的概率为1/(4 ...
- HFSS仿真疑问
P15针在0.5pitch下,GS结构相比GSG更接近50Ω,但是在某些频点会有明显的反射,该频点插损比较大. 从TDR上看,阻抗呈正弦形状变化,有些奇怪. 空气盒子只增加了2mm,试了一下将空气盒子 ...
- nkIO方法
import java.util.*; public class Main{ public static void main(String args[]){ Scanner sc = new Scan ...
- 随机生成不重复的几个数(Unity)
using System.Collections.Generic; using UnityEngine; /// <summary> /// 随机数管理类 /// </summary ...
- 【逆向】HWP文档 分析调试技巧
前言 HWP(Hangul Word Processor)文件是韩国主流文字处理软件Hangul Office(한글)专用的文档格式,Hangul 是一款由韩软公司(Hansoft)开发,在韩国人人皆 ...
- Django框架搭建web项目(二)
1.在路径XXXXX\mydjango\mydjango\mydjango下新建views.py(在浏览器中url请求后所展示的内容设置) from django.http import HttpRe ...
- Spring boot使用mybatis plus ,自己配置多数据源切换,不使用mybatis plus的自动切换数据源。如何配置?
网上有很多springboot + mabatis 配置多数据源的文字和方案,但是我经过配置后aop都执行了,但是AbstractRoutingDataSource没有执行.所以查询结果总是使用的第一 ...
- systick 理解
systick 中断的优先级往往设置为最低值,而不是最高值:如果设置为最低值不会发生上图标号[6]处的情况,设置为最低可能会被其他中断抢占,延长systick的响应时间,但是这个延迟不会累计,因为sy ...