Hadoop(二)Hdfs基本操作
HDFS
HDFS由大量服务器组成存储集群,将数据进行分片与副本,实现高容错。
而分片最小的单位就是块。默认块的大小是64M。
HDFS Cli操作
官网https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/FileSystemShell.html
启动命令
sbin/start-dfs.sh
停止命令
sbin/stop-dfs.sh
创建目录
hadoop fs -mkdir /chesterdata
查看是否创建成功
hadoop fs -ls /
上传文件
hadoop fs -put test.txt /chesterdata
查看文件
hadoop fs -ls /chesterdata
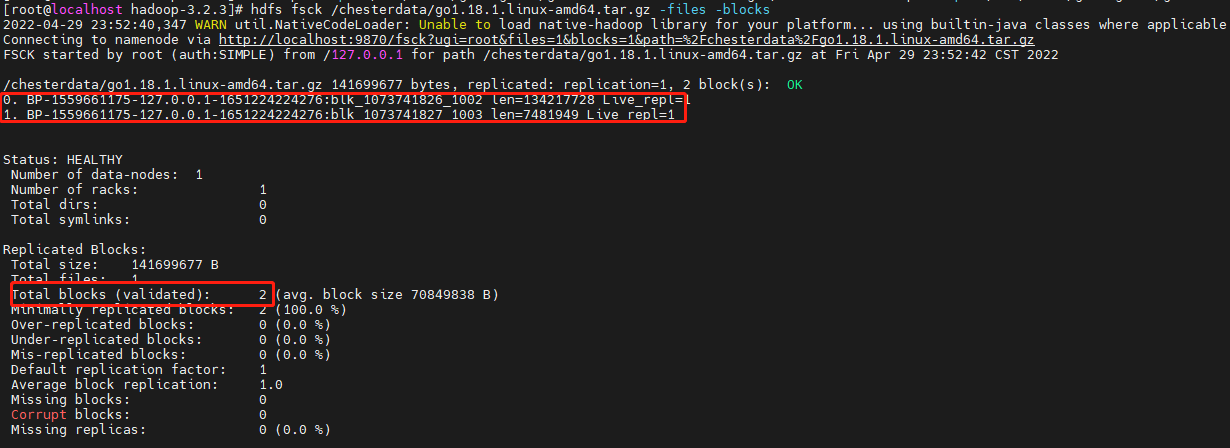
验证块是不是64M,上传一个130M的文件
hadoop fs -put /usr/local/golang1181/go1.18.1.linux-amd64.tar.gz /chesterdata
查看此文件的块信息,hdfs的命令https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html
hdfs fsck /chesterdata/go1.18.1.linux-amd64.tar.gz -files -blocks
编程语言操作HDFS
在Github上搜hdfs可以看到哪些语言支持hdfs的操作
我们选择golang来演示操作
引入github.com/colinmarc/hdfs,官网https://pkg.go.dev/github.com/colinmarc/hdfs#section-readme
package main import "github.com/colinmarc/hdfs"
通过go mod tidy安装
[root@localhost hdfsdemo]# go mod tidy
go: finding module for package github.com/colinmarc/hdfs
go: downloading github.com/colinmarc/hdfs v1.1.3
go: found github.com/colinmarc/hdfs in github.com/colinmarc/hdfs v1.1.3
go: finding module for package github.com/golang/protobuf/proto
创建hdfsclient,并尝试删除hdfs中的/chesterdata/go1.18.1.linux-amd64.tar.gz
package main import (
"fmt" "github.com/colinmarc/hdfs"
) func main() {
client, _ := hdfs.New("localhost:9000") err := client.Remove("/chesterdata/go1.18.1.linux-amd64.tar.gz")
fmt.Println(err)
}
通过go run .运行
[root@localhost hdfsdemo]# go run .
<nil>
通过cli检查是否真正删除
[root@localhost hadoop-3.2.3]# hadoop fs -ls /chesterdata
根据ui来查看文件

Hadoop(二)Hdfs基本操作的更多相关文章
- hadoop(二):hdfs HA原理及安装
早期的hadoop版本,NN是HDFS集群的单点故障点,每一个集群只有一个NN,如果这个机器或进程不可用,整个集群就无法使用.为了解决这个问题,出现了一堆针对HDFS HA的解决方案(如:Linux ...
- Hadoop集群(二) HDFS搭建
HDFS只是Hadoop最基本的一个服务,很多其他服务,都是基于HDFS展开的.所以部署一个HDFS集群,是很核心的一个动作,也是大数据平台的开始. 安装Hadoop集群,首先需要有Zookeeper ...
- Hadoop之HDFS文件操作常有两种方式(转载)
摘要:Hadoop之HDFS文件操作常有两种方式,命令行方式和JavaAPI方式.本文介绍如何利用这两种方式对HDFS文件进行操作. 关键词:HDFS文件 命令行 Java API HD ...
- Hadoop入门--HDFS(单节点)配置和部署 (一)
一 配置SSH 下载ssh服务端和客户端 sudo apt-get install openssh-server openssh-client 验证是否安装成功 ssh username@192.16 ...
- hdfs基本操作
hdfs基本操作 1.查询命令 hadoop dfs -ls / 查询/目录下的所有文件和文件夹 hadoop dfs -ls -R 以递归的方式查询/目录下的所有文件 2.创建文件夹 hadoo ...
- Hadoop基础-HDFS的API常见操作
Hadoop基础-HDFS的API常见操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习HDFS时的一些琐碎的学习笔记, 方便自己以后查看.在调用API ...
- Hadoop基础-HDFS安全管家之Kerberos实战篇
Hadoop基础-HDFS安全管家之Kerberos实战篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们都知道hadoop有很多不同的发行版,比如:Apache Hadoop ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop基础-HDFS的读取与写入过程剖析
Hadoop基础-HDFS的读取与写入过程剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客会简要介绍hadoop的写入过程,并不会设计到源码,我会用图和文字来描述hdf ...
- 深入理解Hadoop之HDFS架构
Hadoop分布式文件系统(HDFS)是一种分布式文件系统.它与现有的分布式文件系统有许多相似之处.但是,与其他分布式文件系统的差异是值得我们注意的: HDFS具有高度容错能力,旨在部署在低成本硬件上 ...
随机推荐
- 构造器(constructor)是否可被重写(override)?
构造器不能被继承,因此不能被重写,但可以被重载.
- dp求最长递增子序列并输出
1 import java.util.ArrayList; 2 import java.util.Arrays; 3 import java.util.List; 4 5 /** 6 * Create ...
- 使用Node.js版本管理器
使用Node.js版本管理器 完全卸载Node.js 清除Package缓存:npm cache clean --force 卸载Node.js:wmic product where caption= ...
- 关于css布局、居中的问题以及一些小技巧
CSS的两种经典布局 左右布局 一栏定宽,一栏自适应 <!-- html --> <div class="left">定宽</div> < ...
- 1kb 的 placeholder.js 增加 img 标签使用方式
预览 官方网站示例. 项目 github 地址 使用 引入 placeholder.js 到你的前段代码中: <script src="placeholder.js"> ...
- 菜鸟的谷歌浏览器devtools日志分析经验
1 别管什么性能,尽可能输出详细的必要日志.(除非你明显感觉到性能变低,而且性能变低的原因是由于日志输出太多而引起的) 2 不要总是使用console.log,试试console.info, cons ...
- div 底部固定方法(不用position定位)
方法一:全局增加一个负值下边距等于底部高度 <style> html, body { height: 100%; margin: 0; } .content { padding: 20px ...
- Web 开发中 Blob 与 FileAPI 使用简述
本文节选自 Awesome CheatSheet/DOM CheatSheet,主要是对 DOM 操作中常见的 Blob.File API 相关概念进行简要描述. Web 开发中 Blob 与 Fil ...
- 爬虫---scrapy架构和原理
scrapy是一个为了爬取网站数据, 提取结构性数据而编写的应用框架, 它是基于Twisted框架开发而来, 而Twisted框架是事件驱动的, 比较适合异步代码. 对会阻塞线程的操作, 包括访问数据 ...
- oracle 11g rac集群 asm磁盘组增加硬盘
创建asm磁盘的几种方式 创建asm磁盘方式很多主要有以下几种 1.Faking方式 2.裸设备方式 3.udev方式(它下面有两种方式) 3.1 uuid方式 3.2 raw方式(裸设备方式) 4. ...