组合总和 II
组合总和 II
题目介绍
给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用 一次 。
注意:解集不能包含重复的组合。
示例:
输入: candidates = [10,1,2,7,6,1,5], target = 8,
输出:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
示例:
输入: candidates = [2,5,2,1,2], target = 5,
输出:
[
[1,2,2],
[5]
]
问题分析
方法一
在这道问题当中我们仍然是从一组数据当中取出数据进行组合,然后得到指定的和,但是与前面的组合总和不同的是,在这个问题当中我们可能遇到重复的数字而且每个数字只能够使用一次。这就给我们增加了很大的困难,因为如果存在相同的数据的话我们就又可能产生数据相同的组合,比如在第二个例子当中我们产生的结果[1, 2, 2]其中的2就可能来自candidates当中不同位置的2,可以是第一个,可以是第三个,也可以是最后一个2。但是在我们的最终答案当中是不允许存在重复的组合的。当然我们可以按照正常的方式遍历,然后将得到的复合要求的结果加入到一个哈希表当中,对得到的结果进行去重处理。但是这样我们的时间和空间开销都会加大很多。
在这个问题当中为了避免产生重复的集合,我们可以首先将这些数据进行排序,然后进行遍历,我们拿一个数据来进行举例子:[1, 2 1],现在我们将这个数据进行排序得到的结果为:[1, 1, 2],那么遍历的树结构如下:
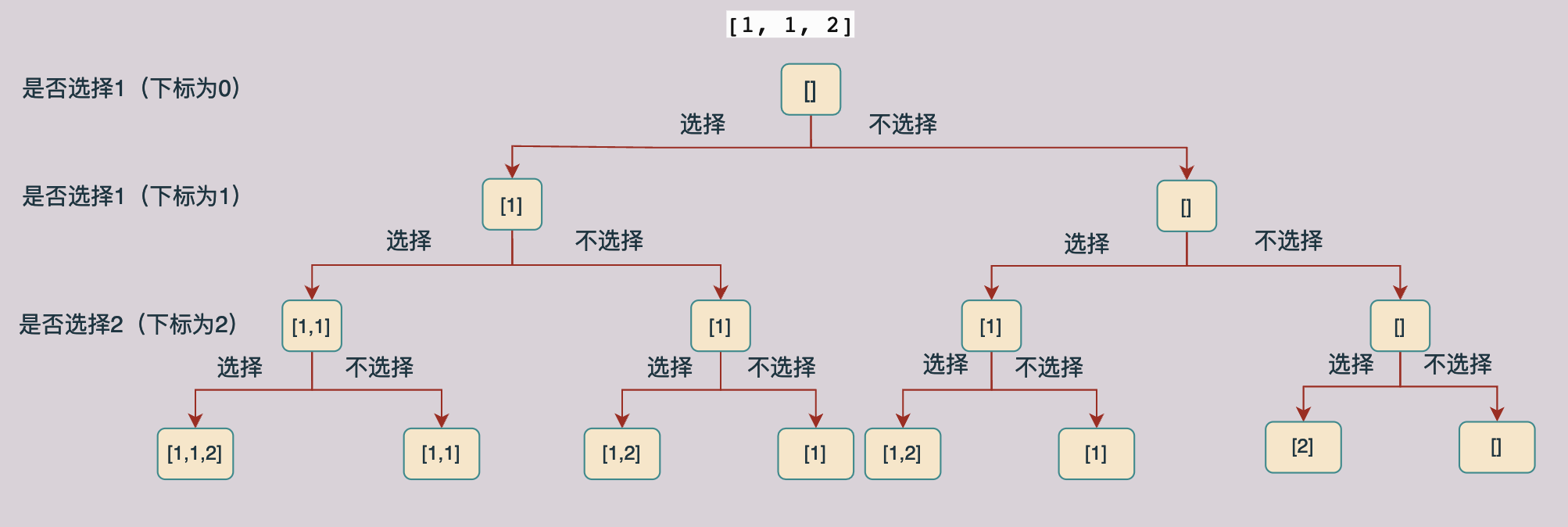
上图表示[1, 1, 2]的遍历树,每一个数据都有选和不选两种情况,根据这种分析方式可以构造上面的解树,我们对上面的树进行分析我们可以知道,在上面的树当中有一部分子树是有重复的(重复的子树那么我们就回产生重复的结果,因此我们要删除重复的分支,也就是不进行递归求解),如下图所示:
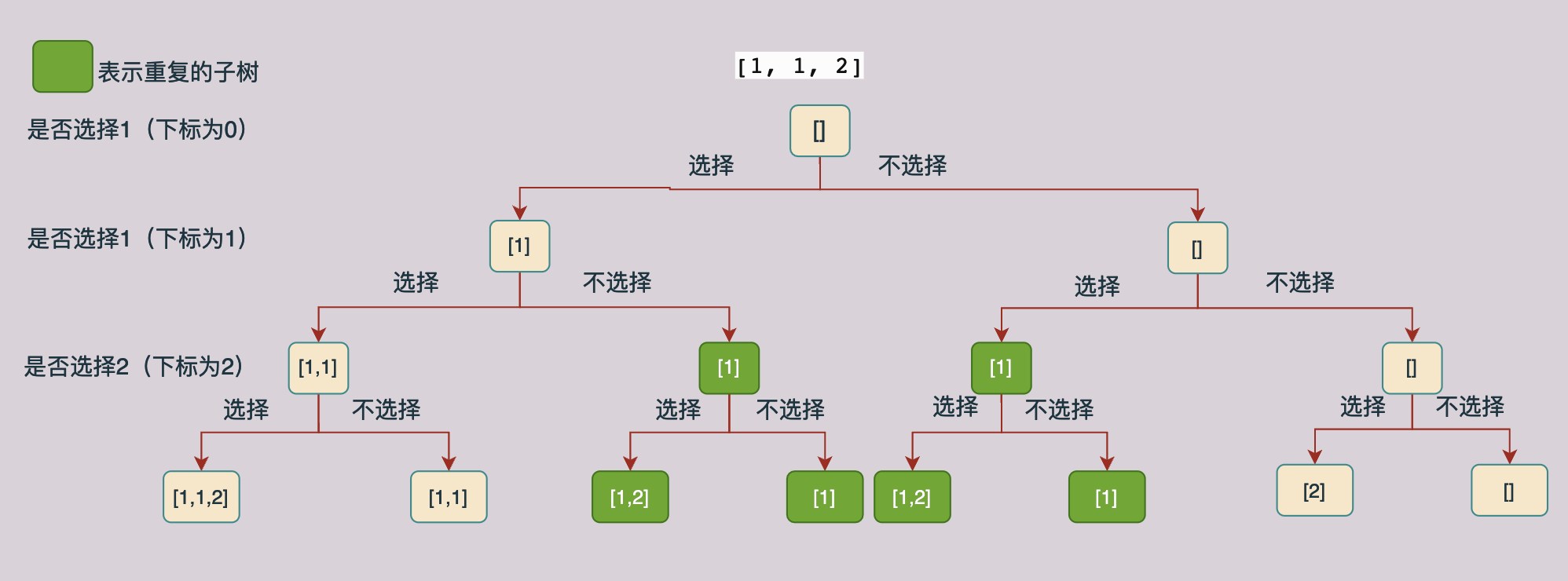
我们现在来分析一下上面图中产生重复子树的原因,在一层当中选1的到第二层不选1的子树和第一层不选1而第二层选1的树产生了重复,因此我们可以在第一层不选1第二层选1的子树当中停止递归。
根据上面的例子我们可以总结出来,在同一层当中,如果后面的值等于他前面一个值的话,我们就可以不去生成“选择”这个分支的子树,因为在他的前面已经生成了一颗一模一样的子树了。
现在我们的问题是如何确定和上一个遍历的节点是在同一层上面。我们可以使用一个used数组进行确定,当我们使用一个数据之后我们将对应下标的used数组的值设置为true,当递归完成进行回溯的时候在将对应位置的used值设置为false,因此当我们遍历一个数据的时候如果他前面的一个数据的used值是false的话,那么这个节点就和前面的一个节点在同一层上面。
根据上面的分析我们可以写出如下的代码:
class Solution {
vector<vector<int>> ans;
vector<int> path;
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(), candidates.end());
vector<bool> used(candidates.size(), false);
backtrace(candidates, target, 0, 0, used);
return ans;
}
void backtrace(vector<int>& candidates, int target, int curIdx,
int curSum, vector<bool>& used) {
if (curSum == target) { // 满足条件则保存结果然后返回
ans.push_back(path);
return;
} else if (curSum > target || curIdx >= candidates.size()) {
return;
}
if (curIdx == 0) {
// 选择分支
path.push_back(candidates[curIdx]);
used[curIdx] = true;
backtrace(candidates, target, curIdx + 1, curSum + candidates[curIdx], used);
// 在这里进行回溯
path.pop_back();
used[curIdx] = false;
// 不选择分支
backtrace(candidates, target, curIdx + 1, curSum, used);
}else {
if (used[curIdx - 1] == false && candidates[curIdx - 1] ==
candidates[curIdx]) { // 在这里进行判断是否在同一层,如果在同一层并且值相等的话 那就不需要进行选择了 只需要走不选择的分支及即可
backtrace(candidates, target, curIdx + 1, curSum, used);
}else{
// 选择分支
path.push_back(candidates[curIdx]);
used[curIdx] = true;
backtrace(candidates, target, curIdx + 1, curSum + candidates[curIdx], used);
// 在这里进行回溯
path.pop_back();
used[curIdx] = false;
// 不选择分支
backtrace(candidates, target, curIdx + 1, curSum, used);
}
}
}
};
方法二
在回溯算法当中我们一般有两种选择情况,这一点我们在前面组合问题当中已经介绍过了,一种方法是用选择和不选择去生成解树,这样我们将生成一颗二叉树的解树,另外一种是多叉树,下面我们来看一下后者的解树:
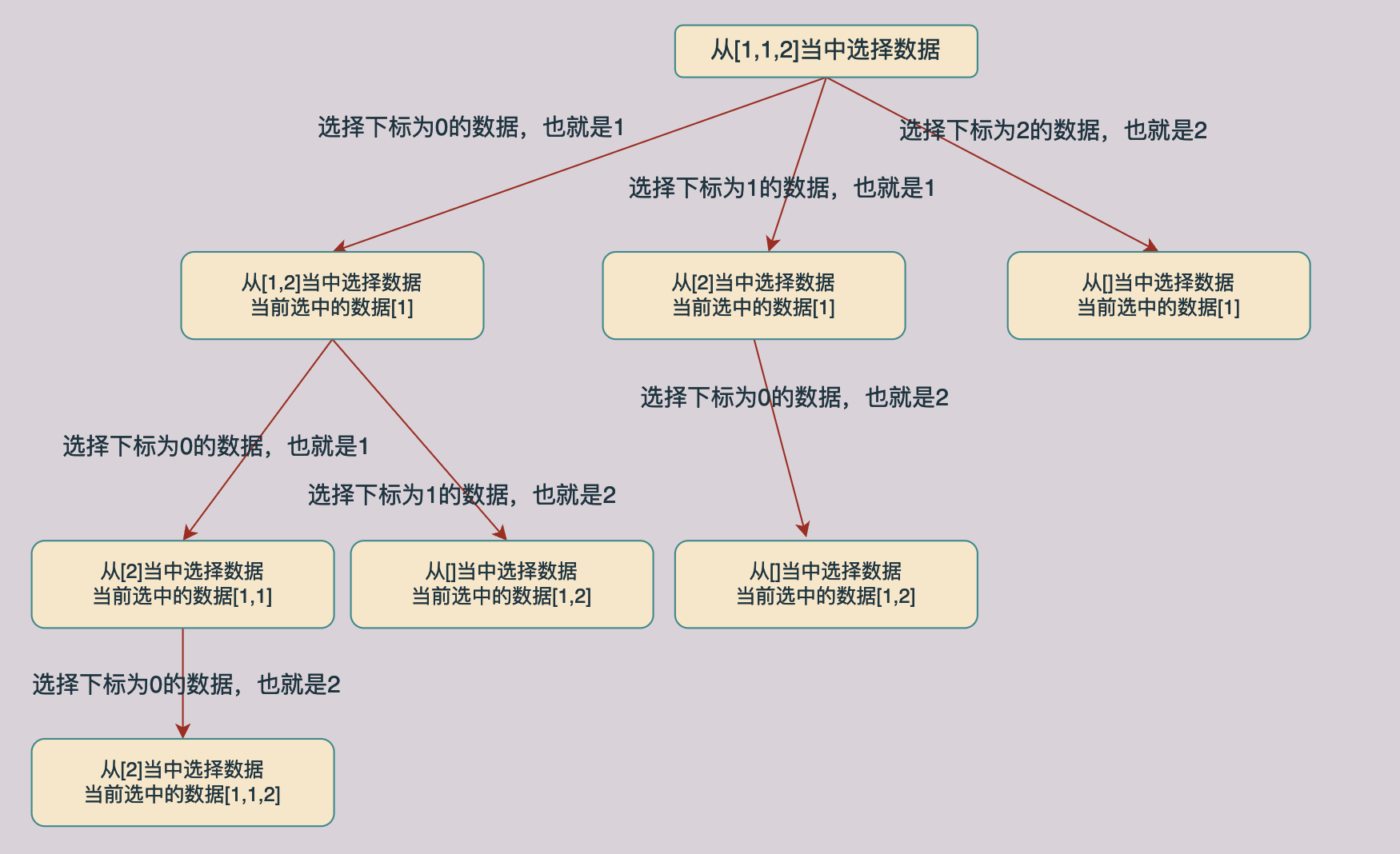
同样对上面的解树进行分析我们回发现同样的也存在相同子树的情况,如下图所示,途中绿色的节点就时相同的节点:
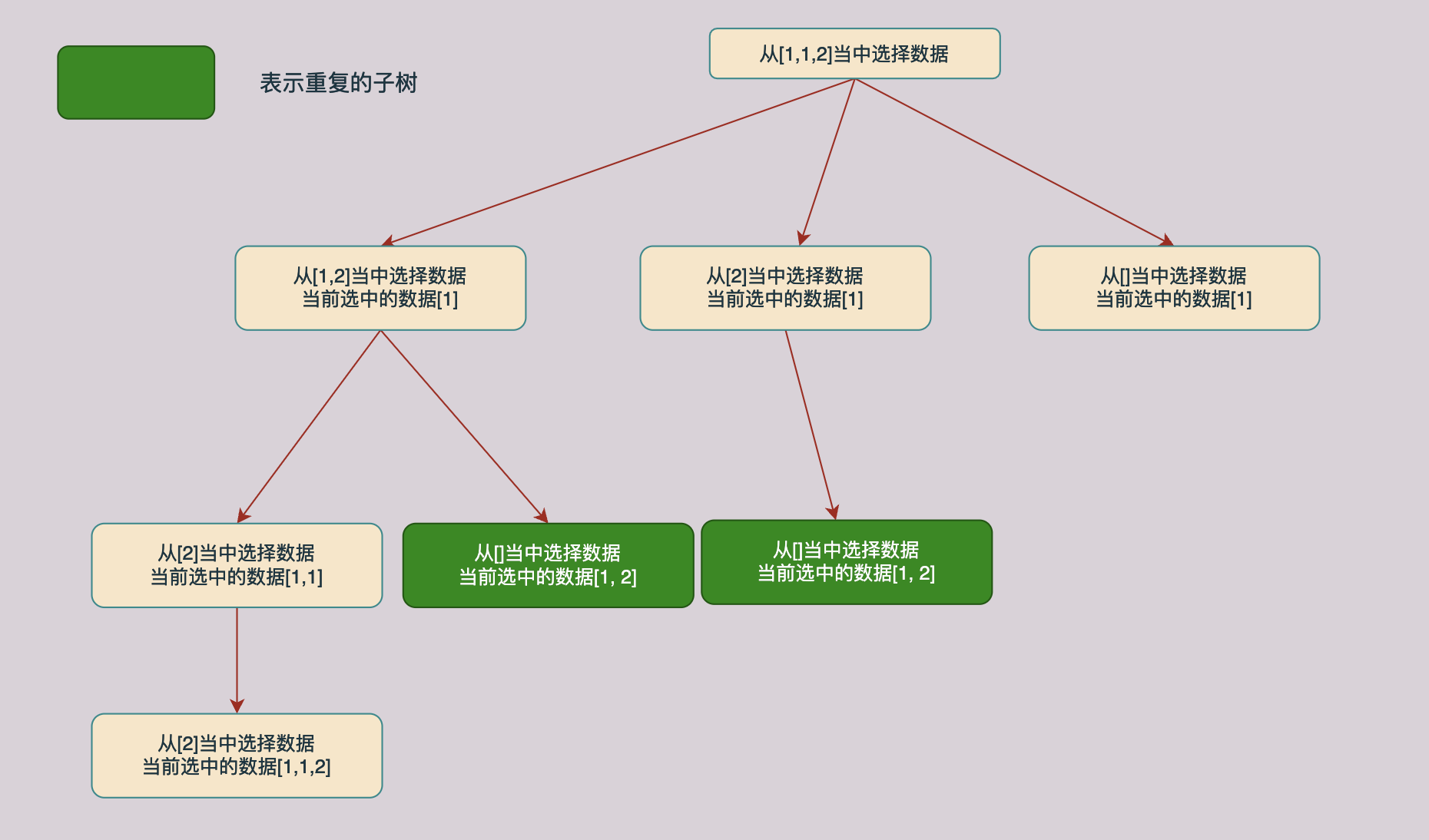
与前一种方法分析一样,当当前的数据和同一层上面的前一个数据相同的时候我们不需要进行求解了,可以直接返回跳过这个分支,因为这个分支已经在前面被求解过了。具体的分析过程如下图所示:
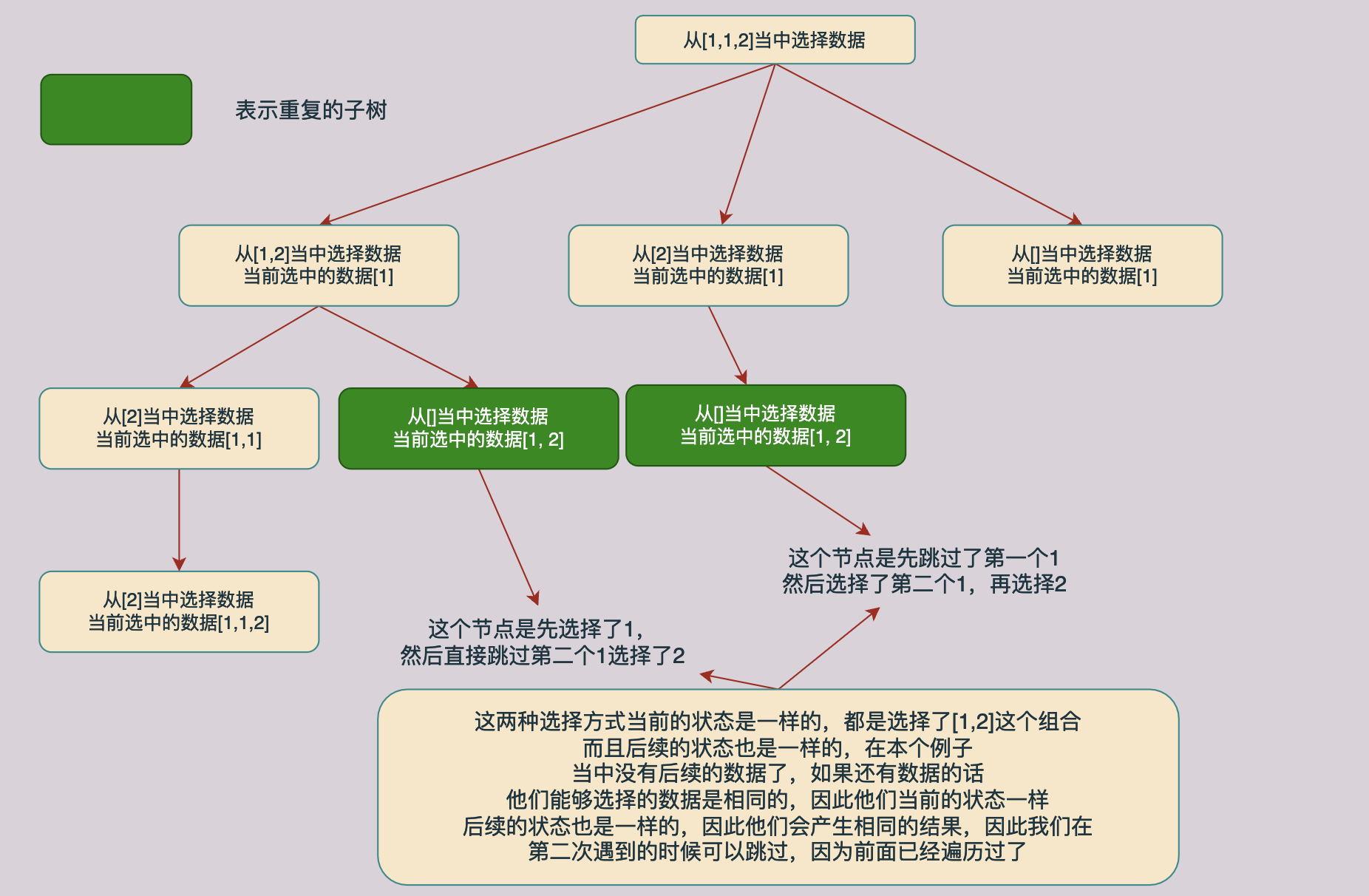
因此和第一种方法一样,我们也需要一个used数组去保存数据是否被访问过,但是在这个方法当中我们还可以根据遍历时候下标去实现这一点,因此不需要used数组了,代码如下所示:
Java代码
class Solution {
private List<List<Integer>> res = new ArrayList<>();
private ArrayList<Integer> path = new ArrayList<>();
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
Arrays.sort(candidates);
backtrace(candidates, target, 0, 0);
return res;
}
public void backtrace(int[] candidates, int target, int curSum,
int curPosition) {
if (curSum == target) // 达到条件则保存结果然后返回
res.add(new ArrayList<>(path));
for (int i = curPosition;
i < candidates.length && curSum + candidates[i] <= target;
i++) {
// 如果 i > curPosition 说明 i 对应的节点和 curPosition 对应的节点在同一层
// 如果 i == curPosition 说明 i 是某一层某个子树的第一个节点
if (i > curPosition && candidates[i] == candidates[i - 1])
continue;
path.add(candidates[i]);
curSum += candidates[i];
backtrace(candidates, target, curSum, i + 1);
// 进行回溯操作
path.remove(path.size() - 1);
curSum -= candidates[i];
}
}
}
C++代码
class Solution {
vector<vector<int>> ans;
vector<int> path;
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(), candidates.end());
backtrace(candidates, target, 0, 0);
return ans;
}
void backtrace(vector<int>& candidates, int target, int curIdx, int curSum) {
if (curSum == target) {
ans.push_back(path);
return;
} else if (curSum > target || curIdx >= candidates.size()) {
return;
}
for(int i = curIdx; i < candidates.size() && curSum + candidates[i] <= target; ++i) {
if (i > curIdx && candidates[i] == candidates[i - 1])
continue;
path.push_back(candidates[i]);
backtrace(candidates, target, i + 1, curSum + candidates[i]);
path.pop_back();
}
}
};
总结
在本篇文章当中主要给大家介绍了组合问题II,这个问题如果仔细进行分析的话会发现里面还是有很多很有意思的细节的,可能需要大家仔细进行思考才能够领悟其中的精妙之处,尤其是两种方法如何处理重复数据结果的情况。
以上就是本篇文章的所有内容了,我是LeHung,我们下期再见!!!更多精彩内容合集可访问项目:https://github.com/Chang-LeHung/CSCore
关注公众号:一无是处的研究僧,了解更多计算机(Java、Python、计算机系统基础、算法与数据结构)知识。
组合总和 II的更多相关文章
- Leetcode之回溯法专题-40. 组合总和 II(Combination Sum II)
Leetcode之回溯法专题-40. 组合总和 II(Combination Sum II) 给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使 ...
- Java实现 LeetCode 40 组合总和 II(二)
40. 组合总和 II 给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合. candidates 中的每个数字在 ...
- 40. 组合总和 II + 递归 + 回溯 + 记录路径
40. 组合总和 II LeetCode_40 题目描述 题解分析 此题和 39. 组合总和 + 递归 + 回溯 + 存储路径很像,只不过题目修改了一下. 题解的关键是首先将候选数组进行排序,然后记录 ...
- LeetCode 中级 - 组合总和II(105)
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合. candidates 中的每个数字在每个组合中只能使用一次. ...
- 40组合总和II
题目:给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合.candidates 中的每个数字在每个组合中只能使用一 ...
- 040 Combination Sum II 组合总和 II
给定候选号码数组 (C) 和目标总和数 (T),找出 C 中候选号码总和为 T 的所有唯一组合.C 中的每个数字只能在组合中使用一次.注意: 所有数字(包括目标)都是正整数. 解决方案集不 ...
- [Swift]LeetCode40. 组合总和 II | Combination Sum II
Given a collection of candidate numbers (candidates) and a target number (target), find all unique c ...
- LeetCode(40):组合总和 II
Medium! 题目描述: 给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合. candidates 中的每个数 ...
- leetcode第40题:组合总和II
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合. candidates 中的每个数字在每个组合中只能使用一次. ...
随机推荐
- day04 缓冲字符流__异常处理
缓冲字符流 缓冲字符输入流:java.io.BufferedReader 是一个高级的字符流,特点是块读文本数据,并且可以按行读取字符串. package io; import java.io.*; ...
- ooday07 Java_接口
笔记: 接口: 是一种引用数据类型 由interface定义 只能包含常量和抽象方法------默认权限是public 接口不能被实例化 接口是需要被实现/继承,实现/派生类:必须重写所有抽象方法 一 ...
- SpringBoot配置文件读取过程分析
整体流程分析 SpringBoot的配置文件有两种 ,一种是 properties文件,一种是yml文件.在SpringBoot启动过程中会对这些文件进行解析加载.在SpringBoot启动的过程中, ...
- 叫高二上一调?简要题解 (ACD)
A. 电压机制 题意转换为所有奇环的并排除掉所有偶环留下的边的个数 . 建出 DFS 树,然后只有返祖边可能构成环 . 于是类似树上差分,\(odd_u\) 统计奇环,\(even_u\) 统计偶环 ...
- 2522-Shiro系列--使用缓存对认证session和授权Cache进行存储
如何进行session的缓存? 原理: Shiro有1个类,AuthorizingRealm AuthenticatingRealm,里面有个获取认证信息的方法, AuthenticatingReal ...
- 6.13 NOI 模拟
\(T1\ first\) \(bitset\)字符串匹配 \(yyds\) \(O(\frac{n^2}{w})\)就是正解! #include<bits/stdc++.h> #defi ...
- Javaweb05-Ajax
1.基于jQuery的Ajax 1.1 基本Ajax 参数 说明 url 请求地址 type 请求类型 data 请求参数 dataType 返回参数 success 成功处理函数 error 错误处 ...
- 设置Windows Server 2022、Win10、Win11自动登录的简单方法-OK
这里介绍自己从使用 Windows Server 2003 到 Windows Server 2022 一直都在使用的自动登录系统的方法,屡试不爽.网上讨论的方法太繁琐,所以共享出来,供大家参考.该方 ...
- ahooks 是怎么解决用户多次提交问题?
本文是深入浅出 ahooks 源码系列文章的第四篇,该系列已整理成文档-地址.觉得还不错,给个 star 支持一下哈,Thanks. 本文来探索一下 ahooks 的 useLockFn.并由此讨论一 ...
- 大家都能看得懂的源码(一)ahooks 整体架构篇
本文是深入浅出 ahooks 源码系列文章的第一篇,该系列已整理成文档-地址.觉得还不错,给个 star 支持一下哈,Thanks. 第一篇主要介绍 ahooks 的背景以及整体架构. React h ...