组合总和 II
组合总和 II
题目介绍
给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用 一次 。
注意:解集不能包含重复的组合。
示例:
输入: candidates = [10,1,2,7,6,1,5], target = 8,
输出:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
示例:
输入: candidates = [2,5,2,1,2], target = 5,
输出:
[
[1,2,2],
[5]
]
问题分析
方法一
在这道问题当中我们仍然是从一组数据当中取出数据进行组合,然后得到指定的和,但是与前面的组合总和不同的是,在这个问题当中我们可能遇到重复的数字而且每个数字只能够使用一次。这就给我们增加了很大的困难,因为如果存在相同的数据的话我们就又可能产生数据相同的组合,比如在第二个例子当中我们产生的结果[1, 2, 2]其中的2就可能来自candidates当中不同位置的2,可以是第一个,可以是第三个,也可以是最后一个2。但是在我们的最终答案当中是不允许存在重复的组合的。当然我们可以按照正常的方式遍历,然后将得到的复合要求的结果加入到一个哈希表当中,对得到的结果进行去重处理。但是这样我们的时间和空间开销都会加大很多。
在这个问题当中为了避免产生重复的集合,我们可以首先将这些数据进行排序,然后进行遍历,我们拿一个数据来进行举例子:[1, 2 1],现在我们将这个数据进行排序得到的结果为:[1, 1, 2],那么遍历的树结构如下:
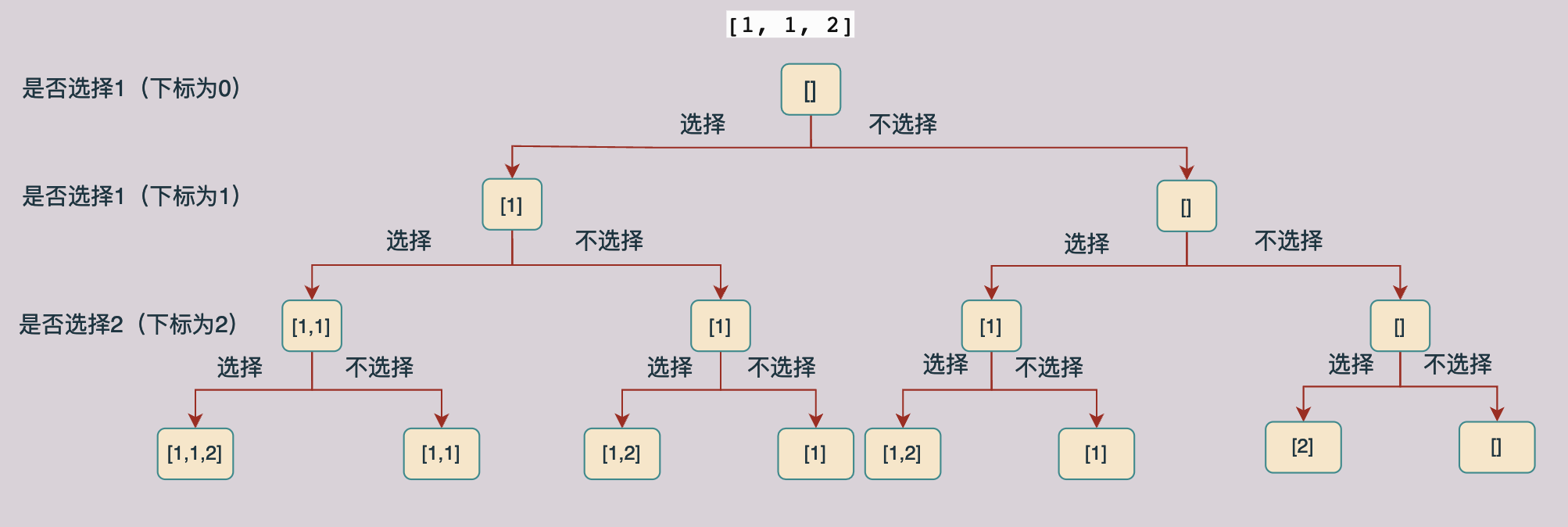
上图表示[1, 1, 2]的遍历树,每一个数据都有选和不选两种情况,根据这种分析方式可以构造上面的解树,我们对上面的树进行分析我们可以知道,在上面的树当中有一部分子树是有重复的(重复的子树那么我们就回产生重复的结果,因此我们要删除重复的分支,也就是不进行递归求解),如下图所示:
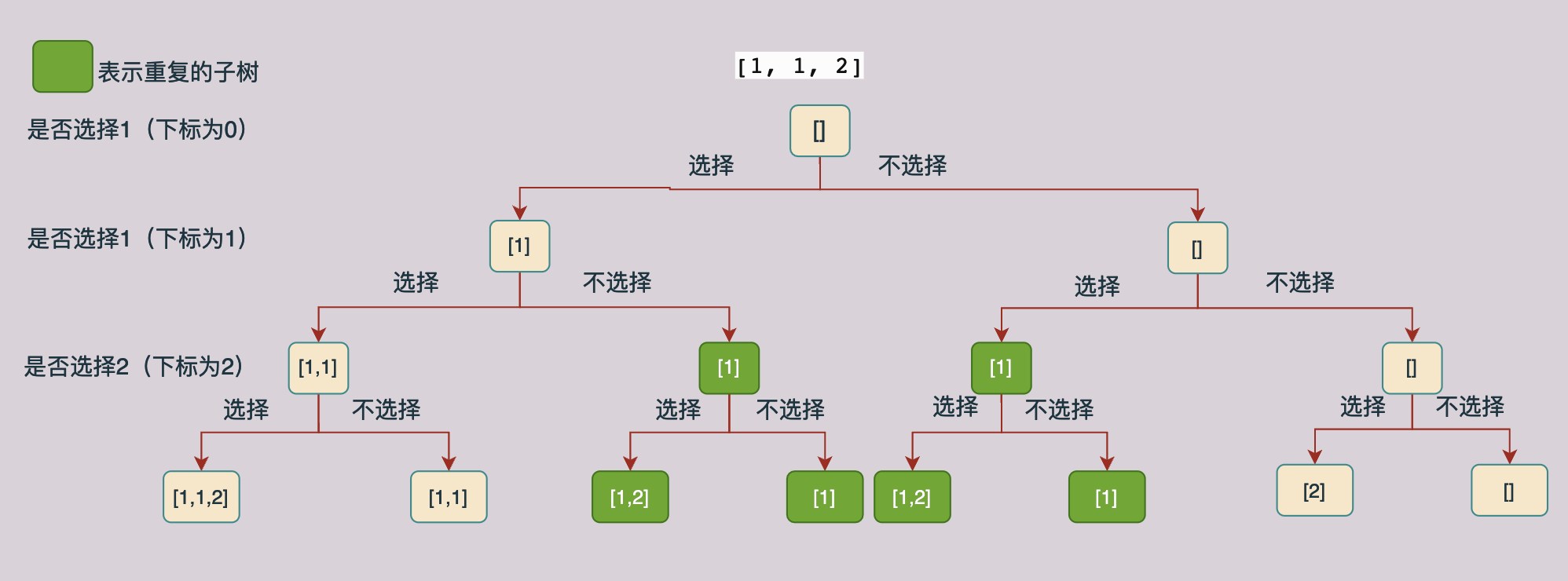
我们现在来分析一下上面图中产生重复子树的原因,在一层当中选1的到第二层不选1的子树和第一层不选1而第二层选1的树产生了重复,因此我们可以在第一层不选1第二层选1的子树当中停止递归。
根据上面的例子我们可以总结出来,在同一层当中,如果后面的值等于他前面一个值的话,我们就可以不去生成“选择”这个分支的子树,因为在他的前面已经生成了一颗一模一样的子树了。
现在我们的问题是如何确定和上一个遍历的节点是在同一层上面。我们可以使用一个used数组进行确定,当我们使用一个数据之后我们将对应下标的used数组的值设置为true,当递归完成进行回溯的时候在将对应位置的used值设置为false,因此当我们遍历一个数据的时候如果他前面的一个数据的used值是false的话,那么这个节点就和前面的一个节点在同一层上面。
根据上面的分析我们可以写出如下的代码:
class Solution {
vector<vector<int>> ans;
vector<int> path;
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(), candidates.end());
vector<bool> used(candidates.size(), false);
backtrace(candidates, target, 0, 0, used);
return ans;
}
void backtrace(vector<int>& candidates, int target, int curIdx,
int curSum, vector<bool>& used) {
if (curSum == target) { // 满足条件则保存结果然后返回
ans.push_back(path);
return;
} else if (curSum > target || curIdx >= candidates.size()) {
return;
}
if (curIdx == 0) {
// 选择分支
path.push_back(candidates[curIdx]);
used[curIdx] = true;
backtrace(candidates, target, curIdx + 1, curSum + candidates[curIdx], used);
// 在这里进行回溯
path.pop_back();
used[curIdx] = false;
// 不选择分支
backtrace(candidates, target, curIdx + 1, curSum, used);
}else {
if (used[curIdx - 1] == false && candidates[curIdx - 1] ==
candidates[curIdx]) { // 在这里进行判断是否在同一层,如果在同一层并且值相等的话 那就不需要进行选择了 只需要走不选择的分支及即可
backtrace(candidates, target, curIdx + 1, curSum, used);
}else{
// 选择分支
path.push_back(candidates[curIdx]);
used[curIdx] = true;
backtrace(candidates, target, curIdx + 1, curSum + candidates[curIdx], used);
// 在这里进行回溯
path.pop_back();
used[curIdx] = false;
// 不选择分支
backtrace(candidates, target, curIdx + 1, curSum, used);
}
}
}
};
方法二
在回溯算法当中我们一般有两种选择情况,这一点我们在前面组合问题当中已经介绍过了,一种方法是用选择和不选择去生成解树,这样我们将生成一颗二叉树的解树,另外一种是多叉树,下面我们来看一下后者的解树:
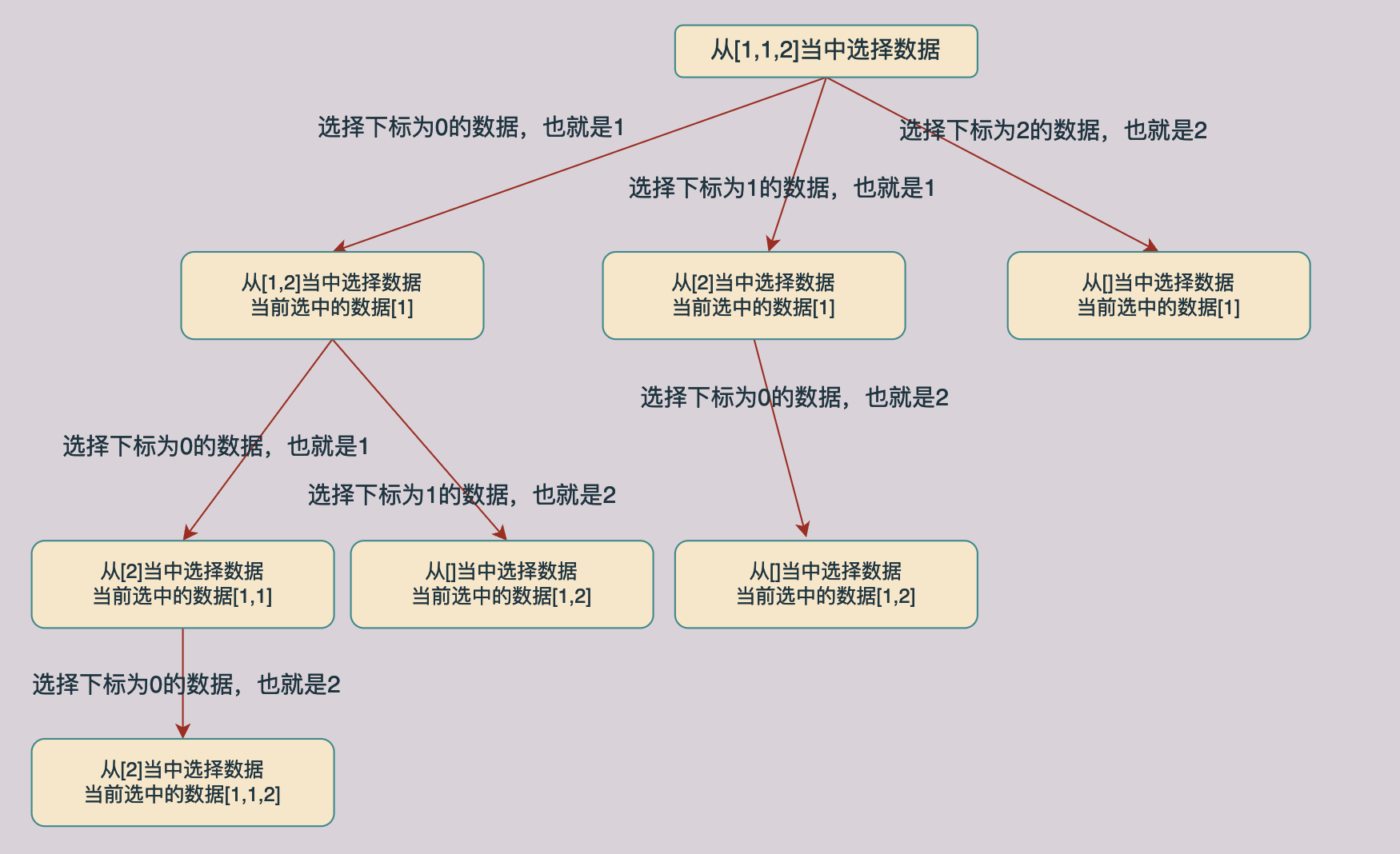
同样对上面的解树进行分析我们回发现同样的也存在相同子树的情况,如下图所示,途中绿色的节点就时相同的节点:
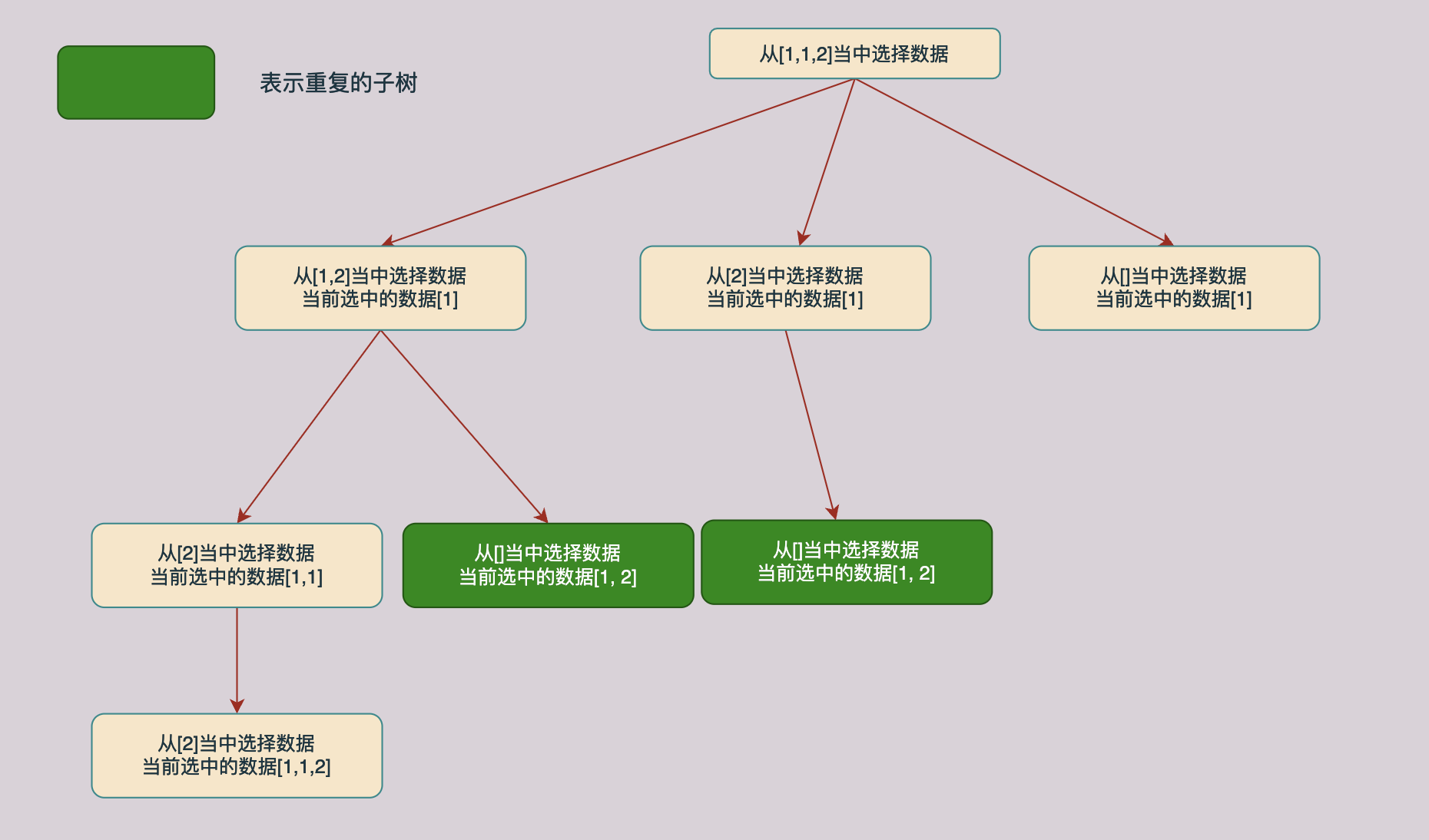
与前一种方法分析一样,当当前的数据和同一层上面的前一个数据相同的时候我们不需要进行求解了,可以直接返回跳过这个分支,因为这个分支已经在前面被求解过了。具体的分析过程如下图所示:
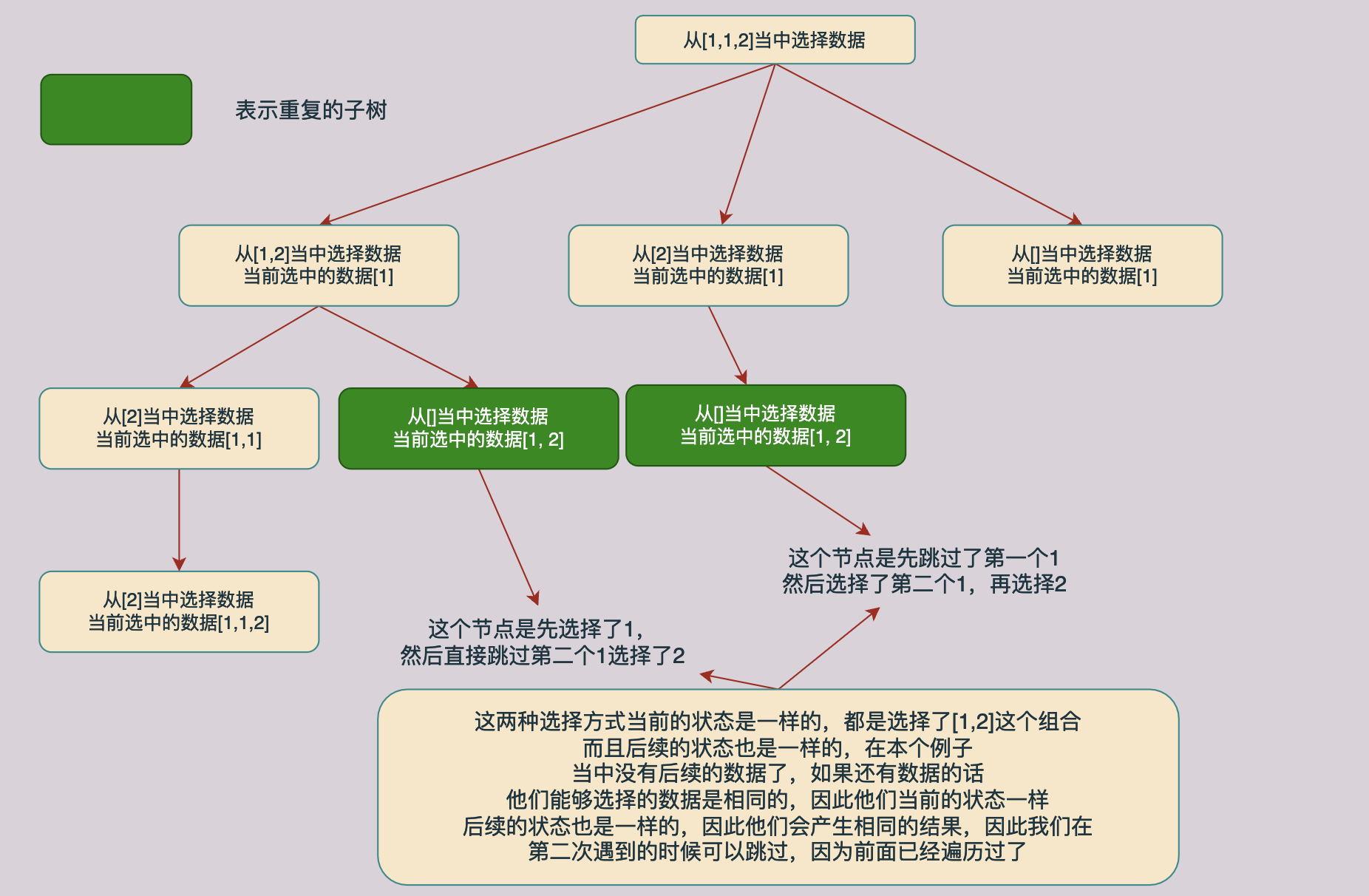
因此和第一种方法一样,我们也需要一个used数组去保存数据是否被访问过,但是在这个方法当中我们还可以根据遍历时候下标去实现这一点,因此不需要used数组了,代码如下所示:
Java代码
class Solution {
private List<List<Integer>> res = new ArrayList<>();
private ArrayList<Integer> path = new ArrayList<>();
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
Arrays.sort(candidates);
backtrace(candidates, target, 0, 0);
return res;
}
public void backtrace(int[] candidates, int target, int curSum,
int curPosition) {
if (curSum == target) // 达到条件则保存结果然后返回
res.add(new ArrayList<>(path));
for (int i = curPosition;
i < candidates.length && curSum + candidates[i] <= target;
i++) {
// 如果 i > curPosition 说明 i 对应的节点和 curPosition 对应的节点在同一层
// 如果 i == curPosition 说明 i 是某一层某个子树的第一个节点
if (i > curPosition && candidates[i] == candidates[i - 1])
continue;
path.add(candidates[i]);
curSum += candidates[i];
backtrace(candidates, target, curSum, i + 1);
// 进行回溯操作
path.remove(path.size() - 1);
curSum -= candidates[i];
}
}
}
C++代码
class Solution {
vector<vector<int>> ans;
vector<int> path;
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(), candidates.end());
backtrace(candidates, target, 0, 0);
return ans;
}
void backtrace(vector<int>& candidates, int target, int curIdx, int curSum) {
if (curSum == target) {
ans.push_back(path);
return;
} else if (curSum > target || curIdx >= candidates.size()) {
return;
}
for(int i = curIdx; i < candidates.size() && curSum + candidates[i] <= target; ++i) {
if (i > curIdx && candidates[i] == candidates[i - 1])
continue;
path.push_back(candidates[i]);
backtrace(candidates, target, i + 1, curSum + candidates[i]);
path.pop_back();
}
}
};
总结
在本篇文章当中主要给大家介绍了组合问题II,这个问题如果仔细进行分析的话会发现里面还是有很多很有意思的细节的,可能需要大家仔细进行思考才能够领悟其中的精妙之处,尤其是两种方法如何处理重复数据结果的情况。
以上就是本篇文章的所有内容了,我是LeHung,我们下期再见!!!更多精彩内容合集可访问项目:https://github.com/Chang-LeHung/CSCore
关注公众号:一无是处的研究僧,了解更多计算机(Java、Python、计算机系统基础、算法与数据结构)知识。
组合总和 II的更多相关文章
- Leetcode之回溯法专题-40. 组合总和 II(Combination Sum II)
Leetcode之回溯法专题-40. 组合总和 II(Combination Sum II) 给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使 ...
- Java实现 LeetCode 40 组合总和 II(二)
40. 组合总和 II 给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合. candidates 中的每个数字在 ...
- 40. 组合总和 II + 递归 + 回溯 + 记录路径
40. 组合总和 II LeetCode_40 题目描述 题解分析 此题和 39. 组合总和 + 递归 + 回溯 + 存储路径很像,只不过题目修改了一下. 题解的关键是首先将候选数组进行排序,然后记录 ...
- LeetCode 中级 - 组合总和II(105)
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合. candidates 中的每个数字在每个组合中只能使用一次. ...
- 40组合总和II
题目:给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合.candidates 中的每个数字在每个组合中只能使用一 ...
- 040 Combination Sum II 组合总和 II
给定候选号码数组 (C) 和目标总和数 (T),找出 C 中候选号码总和为 T 的所有唯一组合.C 中的每个数字只能在组合中使用一次.注意: 所有数字(包括目标)都是正整数. 解决方案集不 ...
- [Swift]LeetCode40. 组合总和 II | Combination Sum II
Given a collection of candidate numbers (candidates) and a target number (target), find all unique c ...
- LeetCode(40):组合总和 II
Medium! 题目描述: 给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合. candidates 中的每个数 ...
- leetcode第40题:组合总和II
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合. candidates 中的每个数字在每个组合中只能使用一次. ...
随机推荐
- SQLZOO练习四--SUM and COUNT(聚合函数)
World Country Profile: Aggregate functions This tutorial is about aggregate functions such as COUNT, ...
- IP核的使用(Vivado中的调用,product guide的查询阅读 ,引脚的设置(位宽,个数,算法等),coe文件的初始化 )
IP核:Intellectual Property core ,即知识产权核.每个IP核可以实现特定功能,我们在设计一个东西时可以直接调用某个IP核来辅助实现功能. 存在形式:HDL语言形式,网表形式 ...
- C#通过完整的例子,Get常用的2个套路,理解抽象方法,虚方法,接口,事件
一.理解:抽象方法,虚方法,接口,事件 描述: 1.定义一个抽象父类"People": 要求: 1>3个属性:名字,性别,年龄: 2>一个普通方法"说话&qu ...
- linux history命令优化
主要功能: 1, 可以记录哪个ip和时间(精确到秒)以及哪个用户,作了哪些命令 2,最大日志记录增加到4096条 把下面的代码直接粘贴到/etc/profile后面就可以了 #history modi ...
- Redis常见数据类型
String 常用命令: get.set.incr.decr mget等操作,普通的key/value存储都可以归为此类 Hash 常用命令: hget,hset,hgetall 等. List(队列 ...
- SkiaSharp 之 WPF 自绘 五环弹动球(案例版)
此案例基于拖曳和弹动球两个技术功能实现,如有不懂的可以参考之前的相关文章,属于递进式教程. 五环弹动球 好吧,名字是我起的,其实,你可以任意个球进行联动弹动,效果还是很不错的,有很多前端都是基于这个特 ...
- uniapp中用canvas实现小球碰撞的小动画
uniapp 我就不想喷了,踩了很多坑,把代码贡献出来让大家少踩些坑. 实现的功能: 生成n个球在canvas中运动,相互碰撞后会反弹,反弹后的速度计算我研究过了,可以参考代码直接用 防止球出边框 防 ...
- MySQL源码解析之执行计划
MySQL源码解析之执行计划 MySQL执行计划介绍 MySQL执行计划代码概览 MySQL执行计划总结 一.MySQL执行计划介绍 在MySQL中,执行计划的实现是基于JOIN和QEP_TAB这两个 ...
- Luogu2251 质量检测 (ST表)
我怎么开始划水了... #include <iostream> #include <cstdio> #include <cstring> #include < ...
- C++ 虚拟桌面
C++ 打开一个虚拟桌面的代码 看不明白的地方 请查看demo: http://download.csdn.net/detail/allh45601/7224205 QQ群:103197177 C++ ...