多快好省地使用pandas分析大型数据集
1 简介
pandas虽然是个非常流行的数据分析利器,但很多朋友在使用pandas处理较大规模的数据集的时候经常会反映pandas运算“慢”,且内存开销“大”。
特别是很多学生党在使用自己性能一般的笔记本尝试处理大型数据集时,往往会被捉襟见肘的算力所劝退。但其实只要掌握一定的pandas使用技巧,配置一般的机器也有能力hold住大型数据集的分析。
 图1
图1
本文就将以真实数据集和运存16G的普通笔记本电脑为例,演示如何运用一系列策略实现多快好省地用pandas分析大型数据集。
2 pandas多快好省策略
我们使用到的数据集来自kaggle上的TalkingData AdTracking Fraud Detection Challenge竞赛( https://www.kaggle.com/c/talkingdata-adtracking-fraud-detection ),使用到其对应的训练集,这是一个大小有7.01G的csv文件。
下面我们将循序渐进地探索在内存开销和计算时间成本之间寻求平衡,首先我们不做任何优化,直接使用pandas的read_csv()来读取train.csv文件:
import pandas as pd
raw = pd.read_csv('train.csv')
# 查看数据框内存使用情况
raw.memory_usage(deep=True)
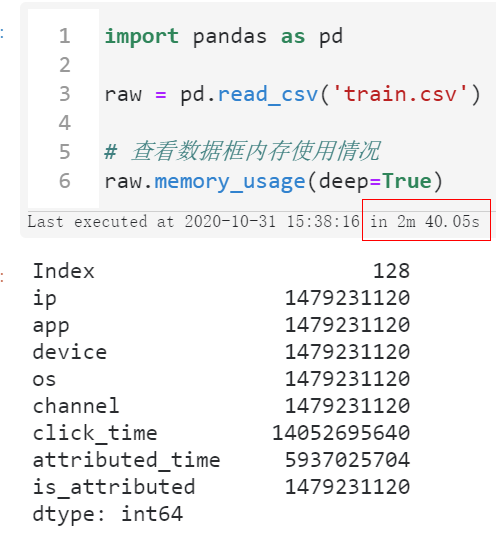 图2
图2
可以看到首先我们读入整个数据集所花费的时间达到了将近三分钟,且整个过程中因为中间各种临时变量的创建,一度快要撑爆我们16G的运行内存空间。
这样一来我们后续想要开展进一步的分析可是说是不可能的,因为随便一个小操作就有可能会因为中间过程大量的临时变量而撑爆内存,导致死机蓝屏,所以我们第一步要做的是降低数据框所占的内存:
- 指定数据类型以节省内存
因为pandas默认情况下读取数据集时各个字段确定数据类型时不会替你优化内存开销,比如我们下面利用参数nrows先读入数据集的前1000行试探着看看每个字段都是什么类型:
raw = pd.read_csv('train.csv', nrows=1000)
raw.info()
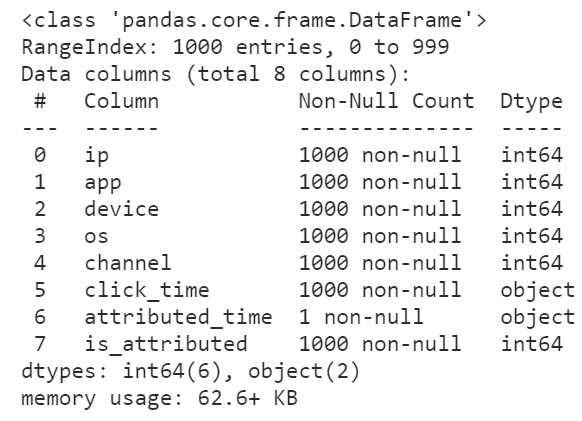 图3
图3
怪不得我们的数据集读进来会那么的大,原来所有的整数列都转换为了int64来存储,事实上我们原数据集中各个整数字段的取值范围根本不需要这么高的精度来存储,因此我们利用dtype参数来降低一些字段的数值精度:
raw = pd.read_csv('train.csv', nrows=1000,
dtype={
'ip': 'int32',
'app': 'int16',
'device': 'int16',
'os': 'int16',
'channel': 'int16',
'is_attributed': 'int8'
})
raw.info()
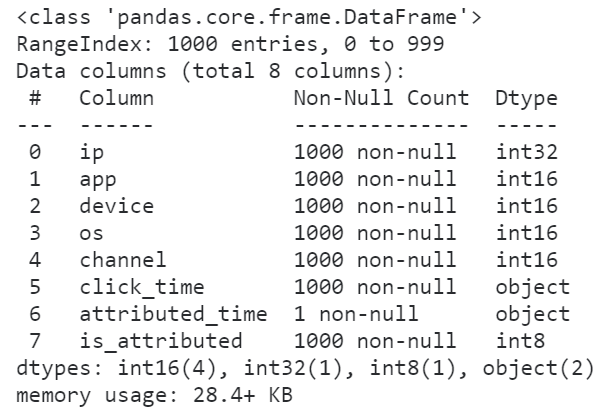 图4
图4
可以看到,在修改数据精度之后,前1000行数据集的内存大小被压缩了将近54.6%,这是个很大的进步,按照这个方法我们尝试着读入全量数据并查看其info()信息:
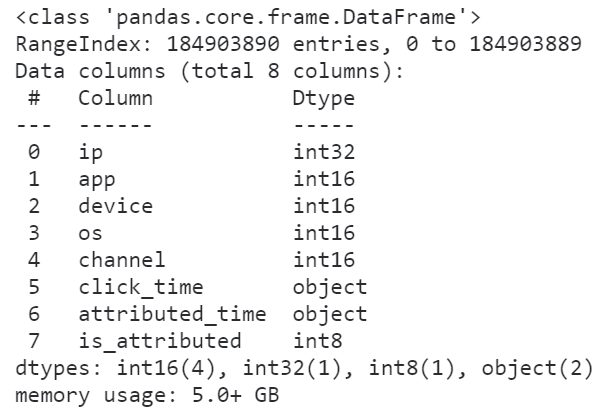 图5
图5
可以看到随着我们对数据精度的优化,数据集所占内存有了非常可观的降低,使得我们开展进一步的数据分析更加顺畅,比如分组计数:
(
raw
# 按照app和os分组计数
.groupby(['app', 'os'])
.agg({'ip': 'count'})
)
 图6
图6
那如果数据集的数据类型没办法优化,那还有什么办法在不撑爆内存的情况下完成计算分析任务呢?
- 只读取需要的列
如果我们的分析过程并不需要用到原数据集中的所有列,那么就没必要全读进来,利用usecols参数来指定需要读入的字段名称:
raw = pd.read_csv('train.csv', usecols=['ip', 'app', 'os'])
raw.info()
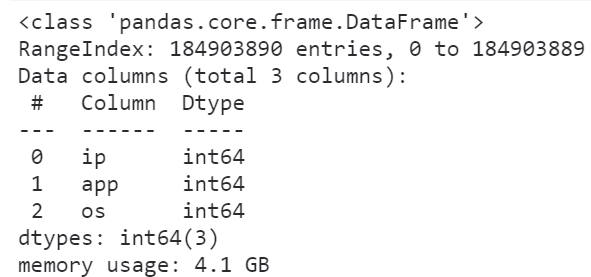 图7
图7
可以看到,即使我们没有对数据精度进行优化,读进来的数据框大小也只有4.1个G,如果配合上数据精度优化效果会更好:
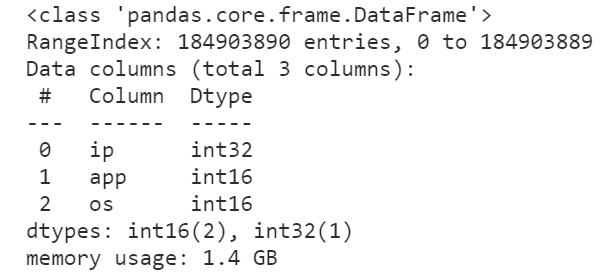 图8
图8
如果有的情况下我们即使优化了数据精度又筛选了要读入的列,数据量依然很大的话,我们还可以以分块读入的方式来处理数据:
- 分块读取分析数据
利用chunksize参数,我们可以为指定的数据集创建分块读取IO流,每次最多读取设定的chunksize行数据,这样我们就可以把针对整个数据集的任务拆分为一个一个小任务最后再汇总结果:
from tqdm.notebook import tqdm
# 在降低数据精度及筛选指定列的情况下,以1千万行为块大小
raw = pd.read_csv('train.csv',
dtype={
'ip': 'int32',
'app': 'int16',
'os': 'int16'
},
usecols=['ip', 'app', 'os'],
chunksize=10000000)
# 从raw中循环提取每个块并进行分组聚合,最后再汇总结果
result = \
(
pd
.concat([chunk
.groupby(['app', 'os'], as_index=False)
.agg({'ip': 'count'}) for chunk in tqdm(raw)])
.groupby(['app', 'os'])
.agg({'ip': 'sum'})
)
result
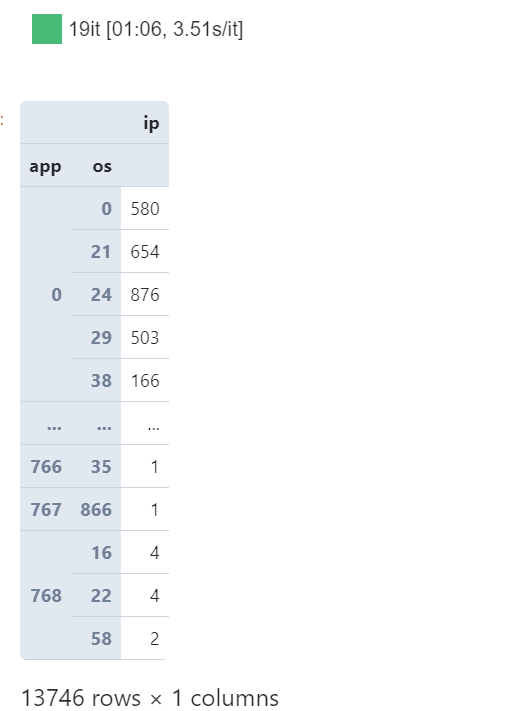 图9
图9
可以看到,利用分块读取处理的策略,从始至终我们都可以保持较低的内存负载压力,并且一样完成了所需的分析任务,同样的思想,如果你觉得上面分块处理的方式有些费事,那下面我们就来上大招:
- 利用dask替代pandas进行数据分析
dask相信很多朋友都有听说过,它的思想与上述的分块处理其实很接近,只不过更加简洁,且对系统资源的调度更加智能,从单机到集群,都可以轻松扩展伸缩。
 图10
图10
推荐使用conda install dask来安装dask相关组件,安装完成后,我们仅仅需要需要将import pandas as pd替换为import dask.dataframe as dd,其他的pandas主流API使用方式则完全兼容,帮助我们无缝地转换代码:
 图11
图11
可以看到整个读取过程只花费了313毫秒,这当然不是真的读进了内存,而是dask的延时加载技术,这样才有能力处理超过内存范围的数据集。
接下来我们只需要像操纵pandas的数据对象一样正常书写代码,最后加上.compute(),dask便会基于前面搭建好的计算图进行正式的结果运算:
(
raw
# 按照app和os分组计数
.groupby(['app', 'os'])
.agg({'ip': 'count'})
.compute() # 激活计算图
)
并且dask会非常智能地调度系统资源,使得我们可以轻松跑满所有CPU:
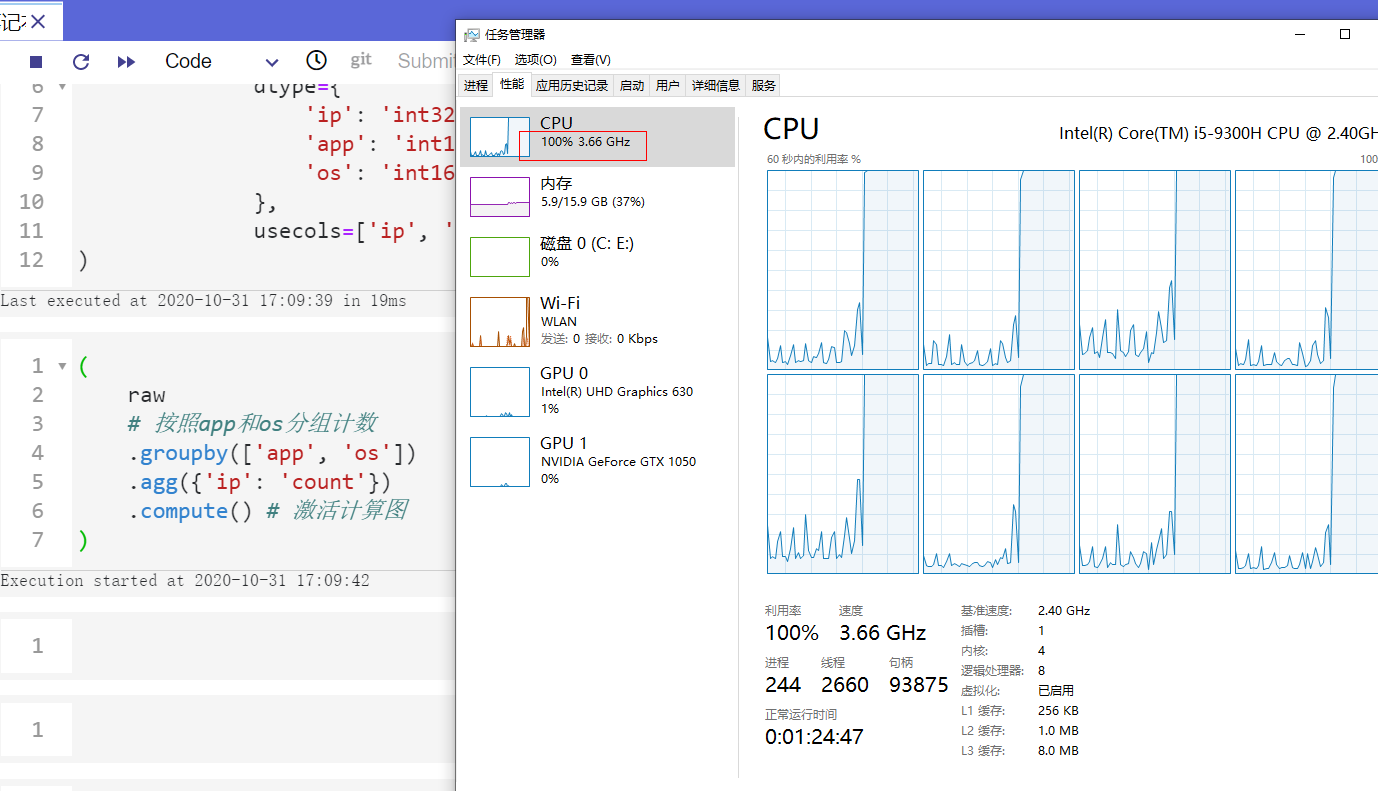 图12
图12
关于dask的更多知识可以移步官网自行学习( https://docs.dask.org/en/latest/ )。
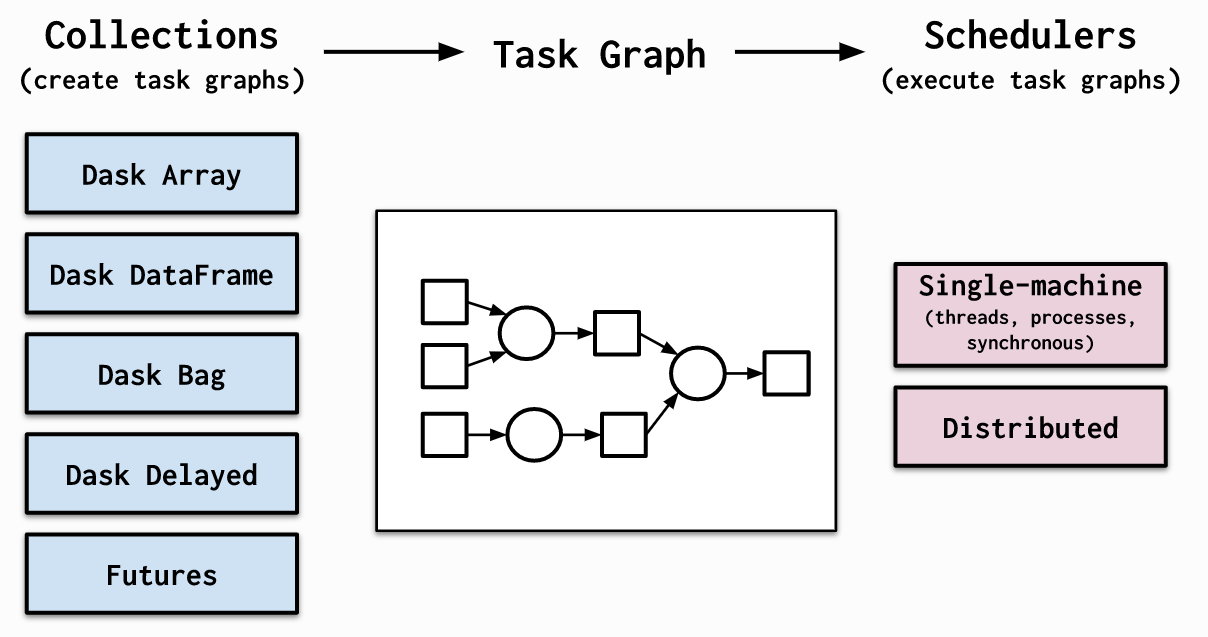 图13
图13
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
多快好省地使用pandas分析大型数据集的更多相关文章
- Microsoft Dynamics CRM 2011 当您在 大型数据集上执行 RetrieveMultiple 查询很慢的解决方法
症状 当您在 Microsoft Dynamics CRM 2011 年大型数据集上执行 RetrieveMultiple 查询时,您会比较慢. 原因 发生此问题是因为大型数据集缓存 Retrieve ...
- Pandas将中文数据集转换为数值类别型数据集
一个机器学习竞赛中,题目大意如下,本文主要记录数据处理过程,为了模型训练,第一步需要将中文数据集处理为数值类别数据集保存. 基于大数据的运营商投诉与故障关联分析 目标:原始数据集是含大量中文的xls格 ...
- 利用python分析泰坦尼克号数据集
1 引言 刚接触python与大数据不久,这个是学长给出的练习题目.知识积累太少,学习用了不少的时间.尽量详细的写,希望对各位的学习有所帮助. 2 背景 2.1 Kaggle 本次数据集来自于Kagg ...
- R语言重要数据集分析研究—— 数据集本身的分析技巧
数据集本身的分析技巧 作者:王立敏 文章来源:网络 1.数据集 数据集,又称为资料集.数据集合或资料集合,是一种由数据所组成的集合. Data set(或dat ...
- 数据规整化:pandas 求合并数据集(交集并集等)
数据集的合并或连接运算是通过一个或多个键将行链接起来的.这些运算是关系型数据库的核心.pandas的merge函数是对数据应用这些算法的这样切入点. 默认是交集, inner连接 列名不同可以分别指定 ...
- 建议42:使用pandas处理大型CSV文件
# -*- coding:utf-8 -*- ''' CSV 常用API 1)reader(csvfile[, dialect='excel'][, fmtparam]),主要用于CSV 文件的读取, ...
- 如何使用pandas分析金融数据
[摘要]pandas是数据分析师分析数据最常用的三方库之一,结合matplotlib,非常强大. 首先我们收集一些数据. 从东方财富客户端导出券商信托板块2018年11月1日的基础行情和财务数据.分别 ...
- [译]使用Pandas读取大型Excel文件
上周我参加了dataisbeautiful subreddit上的Dataviz Battle,我们不得不从TSA声明数据集创建可视化.我喜欢这种比赛,因为大多数时候你最终都会学习很多有用的东西. 这 ...
- pandas 模拟生成数据集的快速方法
快速生成一个DataFrame的方法: #模拟生成数据集的方法 import pandas as pd import numpy as np boolean=[True,False] gender=[ ...
随机推荐
- 基础篇:JVM运行时内存布局
目录 1 JVM的内存区域布局 2 JVM五大数据区域介绍 3 JVM运行时内存布局和JMM内存模型区别 4 JMM内存模型交互操作 欢迎指正文中错误 关注公众号,一起交流 参考文章 1 JVM的内存 ...
- 探讨JVM运行机制和执行流程
JVM是什么 概述 JVM是Java Virtual Machine的缩写.它是一种基于计算设备的规范,是一台虚拟机,即虚构的计算机. JVM屏蔽了具体操作系统平台的信息(显然,就像是我们在电脑上开了 ...
- 我们解决了如何将视频转换为HEVC / H.265和AVC / H.264
LEADTOOLS Recognition Imaging SDK是精选的LEADTOOLS SDK功能集,旨在在企业级文档自动化解决方案中构建端到端文档成像应用程序,这些解决方案需要OCR,MICR ...
- OpenCV图像处理学习笔记-Day03
OpenCV图像处理学习笔记-Day03 目录 OpenCV图像处理学习笔记-Day03 第31课:Canny边缘检测原理 第32课:Canny函数及使用 第33课:图像金字塔-理论基础 第34课:p ...
- OpeMp【schedule】
- 031 01 Android 零基础入门 01 Java基础语法 03 Java运算符 11 运算符的优先级
031 01 Android 零基础入门 01 Java基础语法 03 Java运算符 11 运算符的优先级 本文知识点:Java中运算符的优先级 运算符的优先级问题 前面学习了很多的运算符,如果这些 ...
- 记录编译JDK11源码时遇到的两个问题
执行make all报错信息: 错误一 /src/hotspot/share/runtime/arguments.cpp:1461:35: error: result of comparison ag ...
- try-finally的时候try里面带return
最近学习的JVM小册中老师提了个问题: 最开始我觉得是1,结果程序跑出来是0,感到很疑惑,于是查看了下字节码: 从字节码可以看出: 0:定义变量0 1:将0存入本地变量表slot-0 2:加载slot ...
- 发布MeteoInfo 1.2.3
提升了对GeoTiff格式数据的读取能力(多个tiles).当然还有MeteoInfoLab功能的提升.下载地址:http://yun.baidu.com/share/link?shareid=669 ...
- php 数组与URL相互转换
php为了数组与url参数相互转换提供了两个函数: 1,数组转换为带&的URL的字符串 例如: $arr =['title'=>'我是小白','name'=>'真的很白','tex ...