Java数据结构(十二)—— 霍夫曼树及霍夫曼编码
霍夫曼树
基本介绍和创建
基本介绍
又称哈夫曼树,赫夫曼树
给定n个权值作为n个叶子节点,构造一棵二叉树,若该树的带权路径长度(wpl)达到最小,称为最优二叉树
霍夫曼树是带权路径长度最短的树,权值较大的节点离根较近
几个重要的概念
路径和路径长度:一棵树中从一个节点往下可以达到的子节点之间的通路叫做路径,通路中分支的数目称为路径长度。如规定根节点的层数为1,则从根节点到L层节点的路径长度为L - 1
节点的权及带权路径长度:若将书中的节点赋值给一个有着某种含义的数值,则这个数值称为节点的权,带权路径长度为路径与权值的成绩
树的带权路径长度:所有叶子节点的带权路径长度之和,记为WPL,权值越大的节点离根节点越近的二叉树才是最优二叉树
WPL最小的就是霍夫曼树
举例说明:
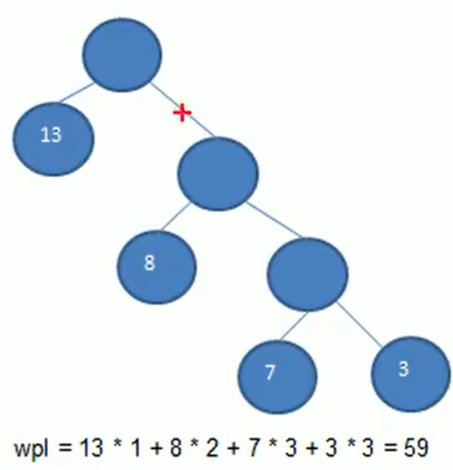
创建霍夫曼树
将数据从小到大排序,每个数据看成一个节点,每个节点是最简单的二叉树
取出根节点权值最小的两颗二叉树
组成一棵新的二叉树,该新的二叉树的根节点的权值是前面两颗二叉树根节点权值之和
再将这颗心的二叉树,以根节点的权值大小再次排序,不断重复上述步骤
直到数列中,所有的数据都被处理就得到一棵霍夫曼树
创建霍夫曼树的过程图解
数据为:{13,7,8,3,29,6,1}
排序:{1,3,6,7,8,13,29}
取出1,3创建,根节点权值为两节点权值之和,数据:{4,6,7,8,13,29}
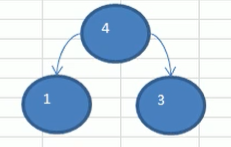
处理4,6,数据:{7,8,10,13,29}
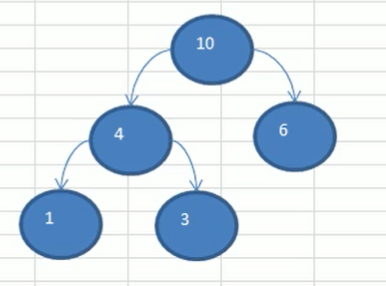
后面依次处理剩余数据……直到所有数据处理完毕
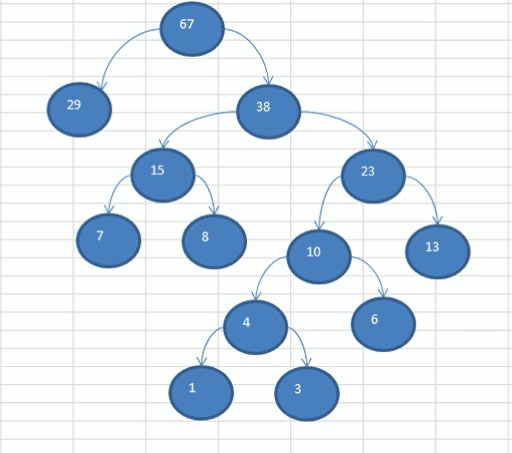
代码实现创建霍夫曼树
package com.why.tree;
import javax.swing.*;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* @Description TODO 创建霍夫曼树
* @Author why
* @Date 2020/11/28 13:23
* Version 1.0
**/
public class HuffmanTreeDemo {
public static void main(String[] args) {
int[] arr = {13,7,8,3,29,6,1};
HuffmanNode root = creatHuffmanTree(arr);
preOrder(root);
}
/**
* 创建霍夫曼树
* @param arr
* @return
*/
public static HuffmanNode creatHuffmanTree(int[] arr){
//构建Node,装入list
List<HuffmanNode> list = new ArrayList<>();
for (int i = 0; i < arr.length; i++) {
list.add(new HuffmanNode(arr[i]));
}
//从小到大排序
Collections.sort(list);
//循环处理
while (list.size() > 1){
//取出权值最小的两个二叉树
HuffmanNode left = list.get(0);
HuffmanNode right = list.get(1);
//构建新的二叉树
HuffmanNode root = new HuffmanNode(left.value+right.value);
root.left = left;
root.right = right;
//从list中删除处理过的二叉树
list.remove(left);
list.remove(right);
//将root加入list
list.add(root);
//重新排序
Collections.sort(list);
}
return list.get(0);
}
public static void preOrder(HuffmanNode root){
if (root != null){
root.preOrder();
}else {
System.out.println("空树");
}
}
}
/**
* 创建节点类
* 为了让Node对象支持Collections排序,让Node实现Comparable接口
*/
class HuffmanNode implements Comparable<HuffmanNode>{
int value;//节点权值
HuffmanNode left;//左指针
HuffmanNode right;//右指针
public HuffmanNode(int value) {
this.value = value;
}
@Override
public String toString() {
return "HuffmanNode{" +
"value=" + value +
'}';
}
/**
* 排序比较
* @param o
* @return
*/
@Override
public int compareTo(HuffmanNode o) {
//从小到大排序
int a = this.value - o.value;
return a;
}
/**
* 前序遍历
*/
public void preOrder(){
System.out.println(this);
if (this.left != null){
this.left.preOrder();
}
if (this.right != null){
this.right.preOrder();
}
}
}
霍夫曼编码
基本介绍
是霍夫曼树在电讯通信的一种经典应用
霍夫曼编码广泛应用于数据文件压缩,压缩率通常在20% ~ 80%之间
霍夫曼编码是可变字长编码(VLC)的一种
通信领域中处理方式
定长编码,利用其ASCII码值对应的二进制进行传输
变长编码:用特定的数字或数字组合对应不同的字符
前缀编码:字符的编码都不能是其他字符编码的前缀,即不能匹配到重复的编码,无二义性
霍夫曼编码的原理
基本步骤
拿到传输的字符串
统计各个字符串出现的个数
按照字符出现的次数构建一棵霍夫曼树,次数位权值(构建步骤参考上文)
根据霍夫曼树进行编码,向左的路径为0,向右的路径为1,如:
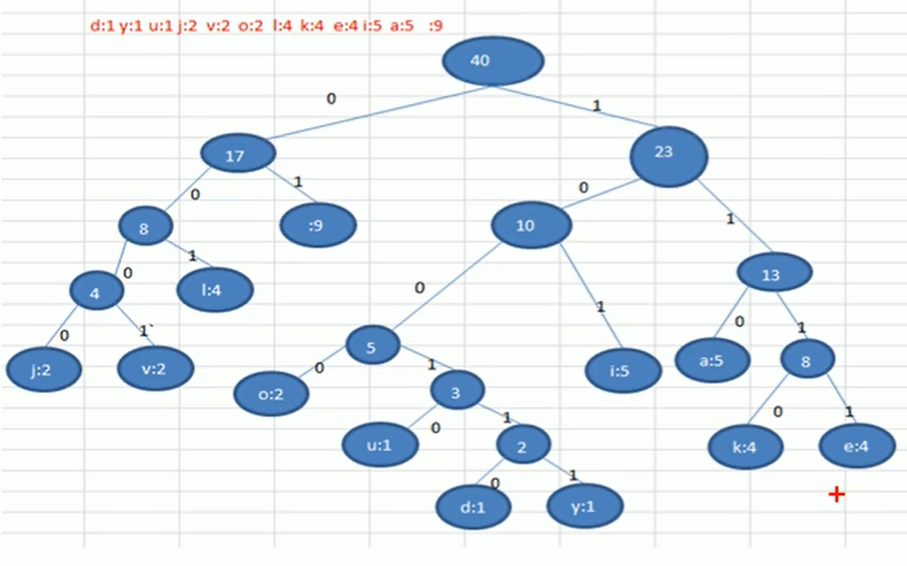
说明
霍夫曼编码是无损压缩
霍夫曼树根据排序方法不同,也可能不太一样,对应的霍夫曼编码不同,但树的权值(WPL)相同,编码的长度相同
数据压缩
字符串
“I like like like java do you like a java”
创建霍夫曼树
思路:
节点类
Node{data(存放数据),weight(权值),left和right}
得到字符串对应的byte数组
编写方法,准备构建霍夫曼树的Node节点放到list,形式{Node[data= , weight = ,],…}
通过list创建霍夫曼树
代码实现
节点类
/**
* 创建Node,数据和权值
* implements Comparable<HuffNode>,支持排序
*/
class HuffNode implements Comparable<HuffNode>{
Byte data;//存放数据
int weight;//权值
HuffNode left;
HuffNode right;
public HuffNode(Byte data, int weight) {
this.data = data;
this.weight = weight;
}
/**
* 支持比较
* @param o
* @return
*/
@Override
public int compareTo(HuffNode o) {
//从小到大排
return this.weight - o.weight;
}
@Override
public String toString() {
return "HuffNode{" +
"data=" + data +
", weight=" + weight +
'}';
}
/**
* 前序遍历
*/
public void preOrder(){
System.out.println(this);
if (this.left != null){
this.left.preOrder();
}
if (this.right != null){
this.right.preOrder();
}
}
}创建霍夫曼树
/**
* 用list存放Node
* @param bytes
* @return
*/
private static List<HuffNode> getNodes(byte[] bytes){
//创建list
List<HuffNode> nodes = new ArrayList<>();
//存储每隔byte出现的次数->map
Map<Byte,Integer> counts = new HashMap<>();
for (byte b: bytes
) {
Integer count = counts.get(b);
if (count == null){//map还没有这个byte
//存放
counts.put(b,1);
}else {//
counts.put(b,count + 1);
}
}
//把每个键值对转成Node对象,并加入到nodes集合
for (Map.Entry<Byte,Integer> entery: counts.entrySet()
) {
nodes.add(new HuffNode(entery.getKey(),entery.getValue()));
}
return nodes;
}
/**
* 建立霍夫曼树
* @param nodes
* @return
*/
private static HuffNode creatHuffTree(List<HuffNode> nodes){
while (nodes.size() > 1){
//排序
Collections.sort(nodes);
HuffNode left = nodes.get(0);
HuffNode right = nodes.get(1);
HuffNode parent = new HuffNode(null,left.weight + right.weight);
parent.left = left;
parent.right = right;
nodes.remove(left);
nodes.remove(right);
nodes.add(parent);
}
return nodes.get(0);//返回根节点
}
/**
* 前序遍历
* @param root
*/
private static void preOrder(HuffNode root){
if (root != null){
root.preOrder();
}else {
System.out.println("空树");
}
}测试
public static void main(String[] args) {
//字符串
String str = "I like like like java do you like a java";
//拿到字节数组
byte[] bytes = str.getBytes();
System.out.println("字符串原始长度:"+bytes.length);
List<HuffNode> nodes = getNodes(bytes);
System.out.println(nodes);
//测试创建的二叉树
System.out.println("霍夫曼树:" );
HuffNode huffNode = creatHuffTree(nodes);
preOrder(huffNode);
}
生成霍夫曼编码表
根据霍夫曼树进行编码,向左的路径为0,向右的路径为1
思路
将霍夫曼编码表存放在map中Map<Byte,String>
在生成霍夫曼编码表时,需要拼接路径,定义StringBulider,存储某个叶子节点的路径
代码实现
生成霍夫曼编码表
static Map<Byte,String> huffCodes = new HashMap<>();
static StringBuilder stringBuilder = new StringBuilder();
/**
* 功能:将传入的node节点的所有的叶子节点的霍夫曼编码得到,并放入到huffCodes
* @param node 传入的节点
* @param code 路径,左0,右1
* @param stringBuilder 用于拼接路径
*/
private static void getCodes(HuffNode node,String code,StringBuilder stringBuilder){
StringBuilder stringBuilder2 = new StringBuilder(stringBuilder);
//将传入的code加入到stringBulider2
stringBuilder2.append(code);
if (node != null){//node == null 不处理
//判断当前node,是叶子节点还是非叶子节点
if (node.data == null){//非叶子节点
//递归处理
//向左递归
getCodes(node.left,"0",stringBuilder2);
//向右递归
getCodes(node.right,"1",stringBuilder2);
}else {//叶子节点
//表示找到某个叶子节点的最后
huffCodes.put(node.data,stringBuilder2.toString());
}
}
}
/**
* 重载
* @param root
*/
private static Map<Byte,String> getCodes(HuffNode root){
if (root == null){
return null;
}else {
//处理root
//处理左子树
getCodes(root.left,"0",stringBuilder);
//处理右子树
getCodes(root.right,"1",stringBuilder);
}
return huffCodes;
}测试
//测试是否生成了霍夫曼编码表
getCodes(huffNode);
System.out.println("霍夫曼编码表:" + huffCodes);
生成霍夫曼编码后字符串的数据
编写方法,将字符串对应的byte数组,通过生成的霍夫曼编码表,返回一个霍夫曼编码压缩后的byte[]
生成霍夫曼编码后的字节数组
/**
* 编写方法,将字符串对应的byte数组,通过生成的霍夫曼编码表,返回一个霍夫曼编码压缩后的byte[]
* @param bytes 原始字符串 对应的byte[]
* @param huffCodes 生成的霍夫曼编码map
* @return 返回霍夫曼编码处理后的byte[]
* 补码 = 反码 + 1
* 源码 = 反码符号位不变,其余取反
*/
private static byte[] zip(byte[] bytes,Map<Byte,String> huffCodes){
//1.利用huffCodes将bytes转成霍夫曼编码后的字符串
StringBuilder stringBuilder = new StringBuilder();
//遍历byte【】
for (byte b: bytes
) {
stringBuilder.append(huffCodes.get(b));
}
// System.out.println(stringBuilder);
//将字符串转成byte数组
//统计返回huffCodesBytes长度
int len;
if (stringBuilder.length() % 8 == 0){
len = stringBuilder.length()/8;
}else {
len = stringBuilder.length()/8 + 1;
}
//创建存储压缩后的byte数组
byte[] huffCodeBytes = new byte[len];
int index = 0;//记录第几个byte
for (int i = 0; i < stringBuilder.length(); i += 8) {//每8位对应一个byte
String strByte;
if (i + 8 > stringBuilder.length()){//不够八位
strByte = stringBuilder.substring(i);
}else {
strByte = stringBuilder.substring(i,i+8);
}
//将strByte转成一个byte
huffCodeBytes[index] = (byte) Integer.parseInt(strByte,2);
index++ ;
}
//拿到霍夫曼编码对应的字节数组返回
return huffCodeBytes;
}测试
byte[] zip = zip(bytes, huffCodes);
System.out.println("霍夫曼编码后的bytes:" + Arrays.toString(zip));
封装测试方法得到霍夫曼编码后的字节数组
/**
* 封装得到霍夫阿曼编码对应的数组
* @param bytes
* @return
*/
private static byte[] huffmanZip(byte[] bytes) {
List<HuffNode> nodes = getNodes(bytes);
//测试创建的二叉树
HuffNode huffNode = creatHuffTree(nodes);
//测试是否生成了霍夫曼编码表
getCodes(huffNode);
byte[] zip = zip(bytes, huffCodes);
return zip;
}
数据解压
使用霍夫曼编码表进行解码
编码的逆过程
思路
将编码后的byte[] 转成二进制字符串
将霍夫曼编码对应的二进制字符串,对照霍夫曼编码表转成字符串对应的字节数组
将byte[]转为bitString
/**
* 将byte转成二进制字符串
* @param b
* @param flag 标志是否需要补高位
* @return 按补码返回
*/
private static String byteToBitString(byte b,boolean flag){
int temp = b;//将b转成int
String str = Integer.toBinaryString(temp);
//返回temp对应二进制的补码,正数的时候需要补位
if (flag){
temp |= 256;//按位与,256 1 0000 0000 | 0000 0001 ==> 1 0000 0001
return str.substring(str.length() - 8);//返回后8位
}else {//后面不满8位不需要补齐
return str;
}
}
数据解码
/**
* 数据解压缩
* @param huffCodes 霍夫曼编码表
* @param huffBytes 压缩后的byte[]
* @return //返回字符串byte[]
*/
private static byte[] decode(Map<Byte,String> huffCodes,byte[] huffBytes){
//1.得到huffBytes对应的二进制字符串
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < huffBytes.length; i++) {
if (i == huffBytes.length - 1){
String str = byteToBitString(huffBytes[i], false);
stringBuilder.append(str);
}else {
String str = byteToBitString(huffBytes[i], true);
stringBuilder.append(str);
}
}
//把字符串按照指定的霍夫曼编码表进行解码
Map<String,Byte> map = new HashMap<>();//将huffCodes键值对反转
for (Map.Entry<Byte,String> entry:huffCodes.entrySet()){
map.put(entry.getValue(),entry.getKey());
}
//创建list,存放byte
List<Byte> list = new ArrayList<>();
for (int i = 0; i < stringBuilder.length(); ) {
int count = 1;
boolean flag = true;
Byte b = null;
while (flag){
//取出一个二进制位
String key = stringBuilder.substring(i,i+count);
//count移动,直到匹配到一个字符
b = map.get(key);
if (b != null){//匹配到
flag = false;
}else {//未匹配到
count ++;
}
}
list.add(b);
i += count;//i移动到count
}
//list中存放了所有字符
byte[] bytes = new byte[list.size()];
for (int i = 0; i < list.size(); i++) {
bytes[i] = list.get(i);
}
return bytes;
}
文件压缩
思路
读取文件 —> 得到霍夫阿曼编码表 —-> 完成压缩
代码实现
/**
* 将文件进行压缩
* @param srcFile 传入希望压缩文件的全路径
* @param dstFile 压缩后文件目录
*/
public static void zipFile(String srcFile,String dstFile){
//创建文件输入流,读取文件
FileInputStream is = null;
//创建输出流,存放压缩文件
FileOutputStream os = null;
//创建一个和文件输出流关联的ObjectOutputStream
ObjectOutputStream oos = null;
try {
is = new FileInputStream(srcFile);
//创建和源文件大小 相同的byte[]
byte[] b = new byte[is.available()];
//读取文件
is.read(b);
//使用霍夫曼编码进行编码,获取霍夫曼编码表
//直接对源文件进行压缩
byte[] huffmanBytes = huffmanZip(b);
//存放压缩文件
os = new FileOutputStream(dstFile);
//new一个和文件输出流关联的ObjectOutputStream
oos = new ObjectOutputStream(os);
//把霍夫曼编码后的字节数组写入压缩文件
oos.write(huffmanBytes);
//这里以对象流的方式写入霍夫曼编码,目的是为了以后恢复原文件时使用
//一定要把霍夫曼编码写入压缩文件
oos.writeObject(huffCodes);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
is.close();
os.close();
oos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
文件解压
思路
读取压缩文件(数据和霍夫曼编码表) —->完成解压
代码实现
//编写一个方法,完成对压缩文件的解压
/**
*
* @param zipFile 准备解压的文件
* @param dstFile 将文件解压到哪个路径
*/
public static void unZipFile(String zipFile, String dstFile) {
//定义文件输入流
InputStream is = null;
//定义一个对象输入流
ObjectInputStream ois = null;
//定义文件的输出流
OutputStream os = null;
try {
//创建文件输入流
is = new FileInputStream(zipFile);
//创建一个和 is关联的对象输入流
ois = new ObjectInputStream(is);
//读取byte数组 huffmanBytes
byte[] huffmanBytes = (byte[])ois.readObject();
//读取赫夫曼编码表
Map<Byte,String> huffmanCodes = (Map<Byte,String>)ois.readObject();
//解码
byte[] bytes = decode(huffmanCodes, huffmanBytes);
//将bytes 数组写入到目标文件
os = new FileOutputStream(dstFile);
//写数据到 dstFile 文件
os.write(bytes);
} catch (Exception e) {
// TODO: handle exception
System.out.println(e.getMessage());
} finally {
try {
os.close();
ois.close();
is.close();
} catch (Exception e2) {
// TODO: handle exception
System.out.println(e2.getMessage());
}
}
}
霍夫曼编码注意事项
如果文件本身时经过压缩处理的,那么编码后效果不明显
霍夫曼编码是按字节来处理的,可以处理所有的文件
如果一个文件中的内容不多,重复的数据不多,压缩效果不明显
所有源码都可在gitee仓库中下载:https://gitee.com/vvwhyyy/java_algorithm
Java数据结构(十二)—— 霍夫曼树及霍夫曼编码的更多相关文章
- Java 树结构实际应用 二(哈夫曼树和哈夫曼编码)
赫夫曼树 1 基本介绍 1) 给定 n 个权值作为 n 个叶子结点,构造一棵二叉树,若该树的带权路径长度(wpl)达到最小,称这样的二叉树为 最优二叉树,也称为哈夫曼树(Huffman Tree), ...
- 数据结构图文解析之:哈夫曼树与哈夫曼编码详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 数据结构(二十七)Huffman树和Huffman编码
Huffman树是一种在编码技术方面得到广泛应用的二叉树,它也是一种最优二叉树. 一.霍夫曼树的基本概念 1.结点的路径和结点的路径长度:结点间的路径是指从一个结点到另一个结点所经历的结点和分支序列. ...
- Java数据结构和算法(一)树
Java数据结构和算法(一)树 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 前面讲到的链表.栈和队列都是一对一的线性结构, ...
- Java基础十二--多态是成员的特点
Java基础十二--多态是成员的特点 一.特点 1,成员变量. 编译和运行都参考等号的左边. 覆盖只发生在函数上,和变量没关系. Fu f = new Zi();System.out.println( ...
- “全栈2019”Java第九十二章:外部类与内部类成员覆盖详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- “全栈2019”Java第十二章:变量
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- “全栈2019”Java第二十二章:控制流程语句中的决策语句if-else
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- 10: java数据结构和算法: 构建哈夫曼树, 获取哈夫曼编码, 使用哈夫曼编码原理对文件压缩和解压
最终结果哈夫曼树,如图所示: 直接上代码: public class HuffmanCode { public static void main(String[] args) { //获取哈夫曼树并显 ...
随机推荐
- 【Flutter 1-5】运行Flutter的第一个项目——计数器
创建项目 创建Flutter项目有很多种方法,各个IDE工具也都集成了创建Flutter项目的快捷操作.我们这里列举三种方式:使用命令行创建.使用Android Studio创建和使用VSCode创建 ...
- 4G DTU数据传输终端的功能介绍
4G DTU是基于4G网络的自动化数据传输终端,是一种物联网无线数据传输设备,使用公用运营商的4G网络为用户提供无线远距离数据传输功能,使用工业级32位的高性能通信处理器和工业级无线模块,以嵌入式实时 ...
- SpringBoot第五集:整合监听器/过滤器和拦截器(2020最新最易懂)
SpringBoot第五集:整合监听器/过滤器和拦截器(2020最新最易懂) 在实际开发过程中,经常会碰见一些比如系统启动初始化信息.统计在线人数.在线用户数.过滤敏/高词汇.访问权限控制(URL级别 ...
- 阅读源码,通过LinkedList回顾基础
目录 前言 类签名 泛型 Serializable和Cloneable Deque List和AbstractList RandomAccess接口(没实现) 变量 构造函数 常用方法 List体系下 ...
- Python使用JsAPI发起微信支付 Demo
Python使用JsAPI发起微信支付 Demo 这个是基于Django框架. 了解更多,可以关注公众号"轻松学编程" 1.公众号设置.微信商户号设置 这些都可以在官网查得到, 公 ...
- LWJGL3的内存管理,第三篇,剩下的两种策略
LWJGL3的内存管理,第三篇,剩下的两种策略 上一篇讨论的基于 MemoryStack 类的栈上分配方式,是效率最高的,但是有些情况下无法使用.比如需要分配的内存较大,又或许生命周期较长.这时候就可 ...
- windows 查看内存
MEMORYSTATUSEX statex; statex.dwLength = sizeof (statex); GlobalMemoryStatusEx (&statex); _tprin ...
- Android网络性能监控方案
阿里云 云原生应用研发平台EMAS 刘宝文(木睿) 背景 移动互联网时代,移动端极大部分业务都需要通过App和Server之间的数据交互来实现,所以大部分App提供的业务功能都需要使用网络请求.如果因 ...
- 23longest-consecutive-sequence
题目描述 给定一个无序的整数类型数组,求最长的连续元素序列的长度. 例如: 给出的数组为[100, 4, 200, 1, 3, 2], 最长的连续元素序列为[1, 2, 3, 4]. 返回这个序列的长 ...
- python动态规划
动态规划: 动态规划表面上很难,其实存在很简单的套路:当求解的问题满足以下两个条件时, 就应该使用动态规划: 主问题的答案 包含了 可分解的子问题答案 (也就是说,问题可以被递归的思想求 ...