使用tkinter打造一个小说下载器,想看什么小说,就下什么
前言
今天教大家用户Python GUI编程——tkinter 打造一个小说下载器,想看什么小说,就下载什么小说
先看下效果图
Tkinter 是使用 python 进行窗口视窗设计的模块。Tkinter模块("Tk 接口")是Python的标准Tk GUI工具包的接口。
作为 python 特定的GUI界面,是一个图像的窗口,tkinter是python 自带的,可以编辑的GUI界面,我们可以用GUI 实现很多直观的功能,比如想开发一个计算器,如果只是一个程序输入,输出窗口的话,是没用用户体验的。所有开发一个图像化的小窗口,就是必要的。

开发环境
- 版 本:anaconda5.2.0(python3.6.5)
- 编辑器:pycharm
本次目标
爬取笔趣阁小说,使用 tkinter 打造一个小说下载器
http://www.xbiquge.la/
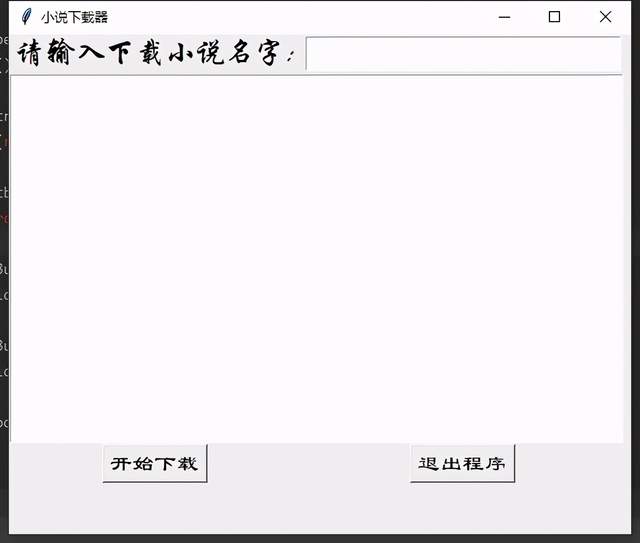
先设计一个图像化的界面
代码
from tkinter import * root = Tk()
root.title('小说下载器')
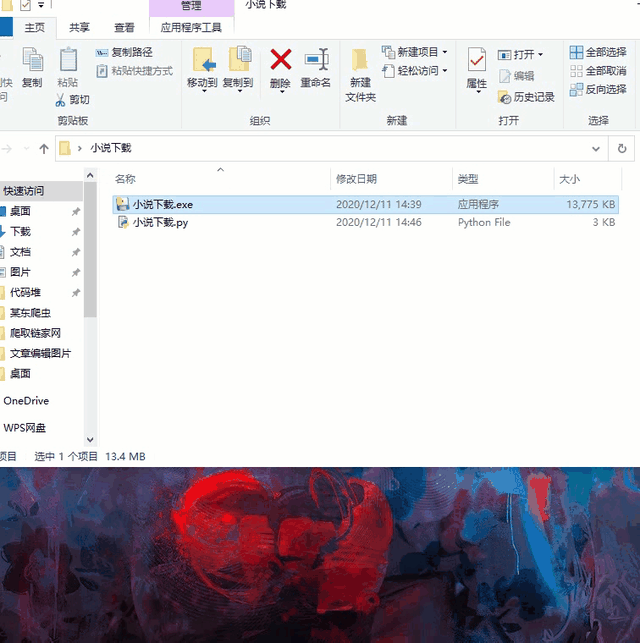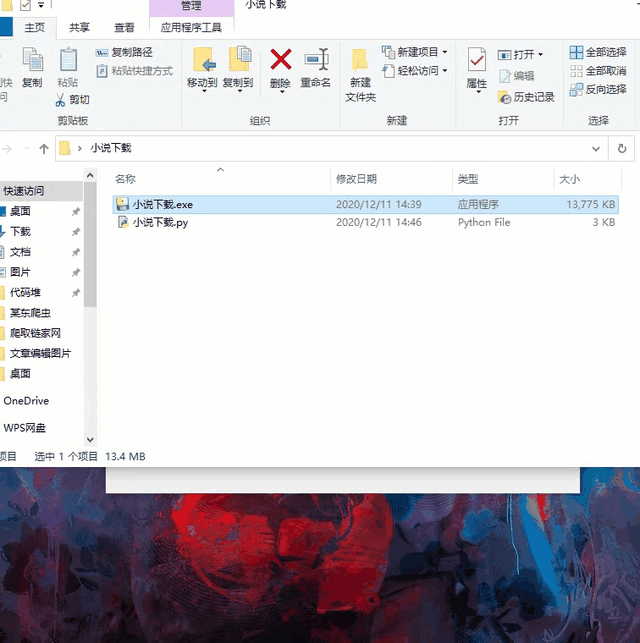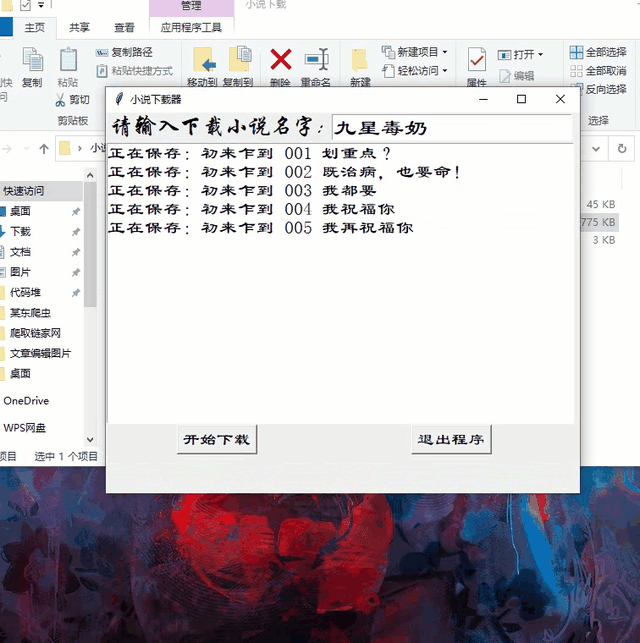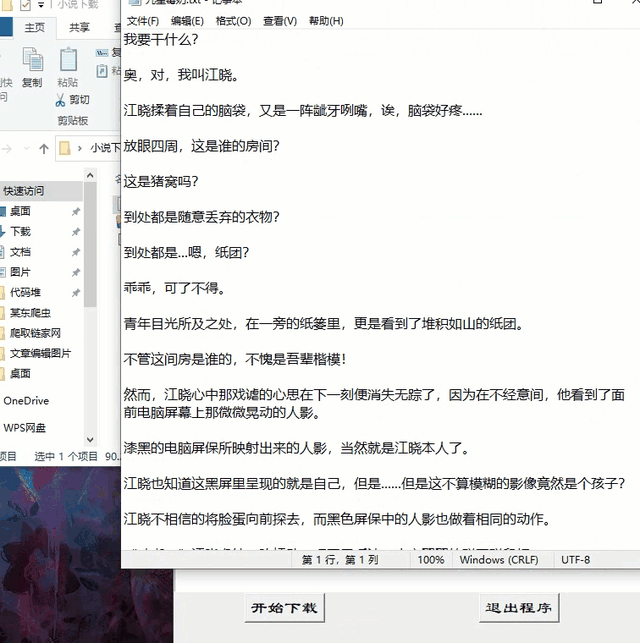
root.geometry('560x450+400+200') label = Label(root, text='请输入下载小说名字:', font=('华文行楷', 20))
label.grid() entry = Entry(root, font=('隶书', 20))
entry.grid(row=0, column=1) text = Listbox(root, font=('隶书', 16), width=50, heigh=15)
text.grid(row=2, columnspan=2) button1 = Button(root, text='开始下载', font=('隶书', 15), command=search)
button1.grid(row=3, column=0) button2 = Button(root, text='退出程序', font=('隶书', 15), command=root.quit)
button2.grid(row=3, column=1) root.mainloop()
效果如下图
开始小说网站的爬虫代码
网页数据是静态网页,但是要搜索,是post请求,需要提交数据参数,如下图所示:

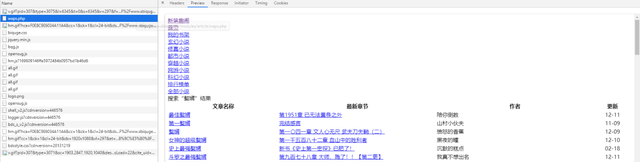
然后通过解析网站数据,获取第一个小说的详情页URL即可。
静态网页的爬取,缺点是不大的。
def search():
search_url = 'http://www.xbiquge.la/modules/article/waps.php'
data = {
'searchkey': name
}
response = requests.post(url=search_url, data=data, headers=headers)
selector = get_parsing(response.text)
novel_url = selector.css('.even a::attr(href)').extract_first()
获取每本小说的章节网址以及小说名字
1,所有的章节名称以及url地址都包含在dd标签里面。
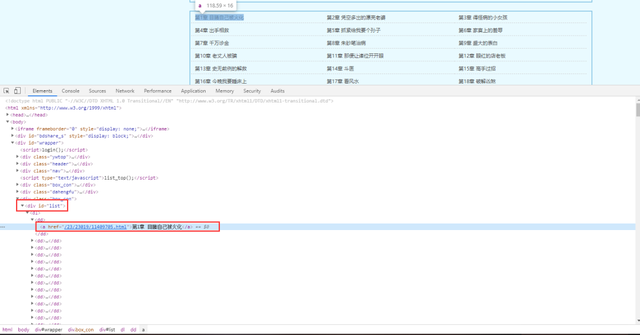
2,获取url后,需要拼接
'/23/23019/11409705.html' # 这是网页获取到的url
'http://www.xbiquge.la/23/23019/11409705.html' # 这是真实的小说章节内容url地址
3,小说名字,直接获取即可。
def download_one_book(index_url):
response = get_response(index_url)
response.encoding = response.apparent_encoding
sel = get_parsing(response.text)
book_name = sel.css('#info h1::text').get()
# 提取了所有章节的下载地址
urls = sel.css('#list dd a::attr(href)').getall()
# 不要最新的 12 章放在最前main
for url in urls:
chapter_url = 'http://www.xbiquge.la' + url
print(chapter_url)
保存下载每章小说内容
def download_one_chapter(chapter_url, book_name):
response = get_response(chapter_url)
response.encoding = response.apparent_encoding
html = response.text
selector = get_parsing(html)
h1 = selector.css('.bookname h1::text').get()
content = selector.css('#content::text').getall()
lines = [] for c in content:
lines.append(c.strip())
print(h1)
text = '\n'.join(lines)
file = open(book_name + '.txt', mode='a', encoding='utf-8')
file.write(h1)
file.write('\n')
file.write(text)
file.write('\n')
file.close()
再来个显示下载内容
def novel_load(title):
text.insert(END, '正在保存:{}'.format(title))
# 文本框滚动
text.see(END)
# 更新
text.update()
最后你还可以把代码给打包成exe文件,分享给你的朋友们用
如果有想要这个程序的小伙伴记得私信我
这个是本篇文章的视频版,详细讲解本次案例步骤,大家可以学习下
https://www.bilibili.com/video/BV13a4y1E7Tb
使用tkinter打造一个小说下载器,想看什么小说,就下什么的更多相关文章
- 从零开发一款txt小说下载器
在日常开发中,列表是一个非常常用的一个东西,可以用listview和recyclerview实现.当然,由于recyclerview更为实用且强大,它也是更好的方案. 而我以前为了方便,习惯直接拿网上 ...
- 星之小说下载器Android版
原本是想在酷安上架的,然而审核不通过..只能通过网页方式宣传了 一款使用Jsoup开源库网络爬虫的APP,将在线阅读的小说解析,把小说全本下载为txt文件 由于使用爬虫技术,所以下载的速度不是很理想, ...
- JavaFx应用 星之小说下载器
星之小说下载器 说明: 需要jdk环境 目前只支持铅笔小说网,后续添加更多书源,还有安卓版,敬请期待. 喜欢的话,不妨打赏一波! 软件交流QQ群:690380139 断点下载暂未实现,小说下载途中,一 ...
- stars-one的原创工具——星之小说下载器(JavaFx应用 )
星之小说下载器Kotlin版 基于星之小说下载器Java版重构的Kotlin版本 github地址 使用说明 确保电脑有jdk8+以上的环境,双击即可运行(win10系统),win7则需要输入命令ja ...
- 从零开始编写一个BitTorrent下载器
从零开始编写一个BitTorrent下载器 BT协议 简介 BT协议Bit Torrent(BT)是一种通信协议,又是一种应用程序,广泛用于对等网络通信(P2P).曾经风靡一时,由于它引起了巨大的流量 ...
- 用tkinter写出you-get下载器界面,并用pyinstaller打包成exe文件
本文为原创文章,转载请标明出处 一.you-get介绍 you-get是一个基于 python 3 的下载工具,使用 you-get 可以很轻松的下载到网络上的视频.图片及音乐.目前支持网易云音乐.A ...
- 使用Python开发小说下载器,不再为下载小说而发愁 #华为云·寻找黑马程序员#
需求分析 免费的小说网比较多,我看的比较多的是笔趣阁.这个网站基本收费的章节刚更新,它就能同步更新,简直不要太叼.既然要批量下载小说,肯定要分析这个网站了- 在搜索栏输入地址后,发送post请求获取数 ...
- 使用C#+XPath+HtmlAgilityPack轻松搞一个资源下载器
HtmlAgilityPack简介 HtmlAgilityPack是一个开源的解析HTML元素的类库,最大的特点是可以通过XPath来解析HMTL,如果您以前用C#操作过XML,那么使用起HtmlAg ...
- 第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器 编写spiders爬虫文件循环 ...
随机推荐
- 设计模式(一)--工厂模式(Go实现)
package Factory import "fmt" type Restaurant interface { GetFood() } type Donglaishun stru ...
- Boost命令行解释器的简单使用:Boost.Program_options
简介 如果使用比较多的命令行程序的话,对于命令行参数的输入肯定不会陌生,大部分的程序都是通过类似下面的形式进行输入的,比如熟悉的ls ls --all -l --color=auto 这里面包含了三种 ...
- Hadoop框架:MapReduce基本原理和入门案例
本文源码:GitHub·点这里 || GitEE·点这里 一.MapReduce概述 1.基本概念 Hadoop核心组件之一:分布式计算的方案MapReduce,是一种编程模型,用于大规模数据集的并行 ...
- 面试官:你说你精通SpringBoot,你给我说一下类的自动装配吧
## 剖析@SpringBootApplication注解 创建一个SpringBoot工程后,SpringBoot会为用户提供一个Application类,该类负责项目的启动: ```@Spring ...
- 去年去阿里面试,被问到java 多线程,我是这样手撕面试官的
1.多线程的基本概念 1.1进程与线程 程序:是为完成特定任务,用某种语言编写的一组指令的集合,即一段静态代码,静态对象. 进程:是程序的一次执行过程,或是正在运行的一个程序,是一个动态的过程,每个程 ...
- 02python开发之基本运算符
02 python开发之基本运算符 目录 02 python开发之基本运算符 2 基本运算符 2.1 算数运算符 2.1.1 种类 2.1.2 用法 2.2 比较运算符 2.2.1 种类 2.2.2 ...
- python中操作excel数据
python操作excel,python有提供库 本文介绍openpyxl,他只支持新型的excell( xlsx)格式,读取速度还可以 1.安装 pip install openpyxl 2.使用 ...
- H3CNE认证(题库)
H3CNE考试的题库,均为发烧友收集的,拥有将近认证考试的百分之八十五的题,但答案不具备官方性,但是题库具有解析. https://huxiaoyao.lanzous.com/b01tr2skd 密码 ...
- Istio 之ServiceEntry
使用服务条目资源(ServiceEntry)可以将条目添加到 Istio 内部维护的服务注册表中.添加服务条目后,Envoy 代理可以将流量发送到该服务,就好像该服务条目是网格中的服务一样.通过配置服 ...
- SQL注入步骤
1.判断是否存在注入,注入是字符型还是数字型2.猜解SQL查询语句中的字段数3.确定回显的字段数4.获取当前数据库5.获取表中字段名6.下载数据