在Python里,用股票案例讲描述性统计分析方法(内容来自我的书)
描述性统计是数学统计分析里的一种方法,通过这种统计方法,能分析出数据整体状况以及数据间的关联。在这部分里,将用股票数据为样本,以matplotlib类为可视化工具,讲述描述性统计里常用指标的计算方法和含义。
1 平均数、中位数和百分位数
平均数比较好理解,是样本的和除以样本的个数。
中位数也叫中值,假设样本个数是奇数,那么数据按顺序排列后处于居中位置的数则是中位数,如果样本个数是偶数,那么排序后,中间两个数据的均值则是中位数。通俗地讲,在样本数据里,有一半的样本比中位数大,有一半比它小。
把中位数的概念扩展一下,即可得到百分位数。比如第25百分位数则表示,样本数据里,有25%的数据小于等于它,而75%的数据大于它。在实际项目里,还会把第25百分位数、中位数和第75百分位数组合起来形成四分位数,因为通过这些数,能把样本一分为四。其中第25百分位数也叫下四分位数,第75百分位数也叫上四分位数。
理解概念后,在如下的CalAvgMore.py范例中,将以股票收盘价为例,演示平均数、中位数和四分位数的求法。
1 #coding=utf-8
2 import pandas as pd
3 filename='D:\\work\\data\\ch9\\6007852019-06-012020-01-31.csv'
4 df = pd.read_csv(filename,encoding='gbk') #读取数据到DataFrame
5 print(df['Close'].mean()) #输出收盘价的平均值
6 print(df['Close'].median()) #输出收盘价的中位数
7 print(df['Close'].quantile(0.5)) #输出收盘价第50百分位数
8 print(df['Close'].quantile(0.25)) #输出收盘价第25百分位数
9 print(df['Close'].quantile(0.75)) #输出收盘价第75百分位数![]()
在进行数据分析时,一般会先从csv文件等数据源里获取样本,获取后用表格类型的DataFrame对象来存储,所以在第3行和第4行里,演示从指定csv文件里得到数据并通过read_csv导入到DataFrame类型对象的做法,这里用到csv是由9.1.4部分的StoreStockToMySQL范例生成的。
Pandas库的DataFrame对象已经封装了求各种统计数据的方法,具体而言,能通过第5行的mean方法求平均值,在调用时,还可以用诸如df['Close']的样式,指定针对哪列数据计算。通过第6行的median方法,能计算指定列的中位数。
在第7行到第9行的代码里,是通过 quantile方法求百分位数,比如第7行的参数是0.5,则求第50的百分位数。运行本范例,能看到如下的输出结果,其中第2行输出的中位数和第3行输出的第50百分位数是一个结果。
2 用箱状图展示分位数
箱状图能以可视化的方式,形象地展示平均数和诸多分位数。在如下的BoxPlotDemo.py范例中,将还是以股票收盘价为例,展示箱状图的绘制技巧,从中大家能进一步了解分位数的概念。
1 #coding=utf-8
2 import pandas as pd
3 import matplotlib.pyplot as plt
4 filename='D:\\work\\data\\ch9\\6007852019-06-012020-01-31.csv'
5 df = pd.read_csv(filename,encoding='gbk') #读取数据到DataFrame
6 #绘制箱状图
7 df['Close'].plot.box(patch_artist=True,notch = True)
8 plt.show()![]()
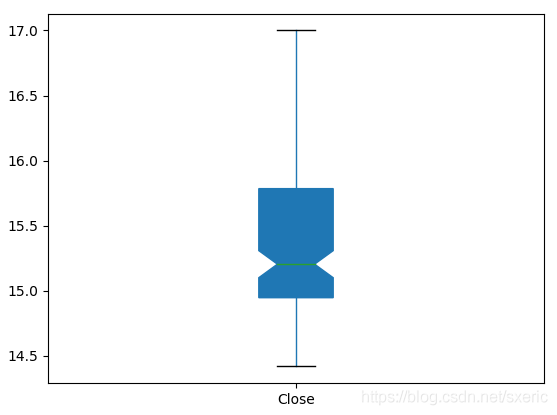
在代码的第5行里,还是通过read_csv方法把csv文件数据读到df对象,之后,是通过第7行的plot.box方法,绘制“收盘价”的箱状图,运行本范例后,能看到如下图所示的效果。
![]()
在第7行绘制箱状图时传入了两个参数,其中patch_artist=True表示需要填充箱体的颜色,用notch = True表示以凹口的方式展示箱状图。从上述箱状图里,能形象地看到最高和最低的值,以及第25、第50和第75百分位数的值,由此更能形象地看到“收盘价”样本数的聚集区间。
3 统计极差、方差和标准差
在统计学里,一般用这三个指标来衡量样本数据的离散度,即衡量样本数对于中心位置(一般是平均数)的偏离程度。
其中,极差的算法比较简单,是样本里最大值和最小值的差,而方差是每个样本值与全体样本值的平均数之差的平方值的平均数,标准差则是方差的平方根。在如下的CalAlias.py范例中,将演示这三个值的获取方式。
1 #coding=utf-8
2 import pandas as pd
3 filename='D:\\work\\data\\ch9\\6007852019-06-012020-01-31.csv'
4 df = pd.read_csv(filename,encoding='gbk') #读取数据到DataFrame
5 print(df['Close'].max() - df['Close'].min()) #求极差
6 print(df['Close'].var()) #求方差
7 print(df['Close'].std()) #求标准差![]()
在第5行里,是通过最大值减最小值的方法算出了极差,在第6行里,通过var方法计算了方差,第7行则通过std方法求标准差。
本文出自我写的书: Python爬虫、数据分析与可视化:工具详解与案例实战,https://item.jd.com/10023983398756.html

![]()
请大家关注我的公众号:一起进步,一起挣钱,在本公众号里,会有很多精彩文章。

![]()
在Python里,用股票案例讲描述性统计分析方法(内容来自我的书)的更多相关文章
- 在python里调用java的py4j的使用方法
py4j可以使python和java互调 py4j并不会开启jvm,需要先启动jvm server,然后再使用python的client去连接jvm GatewayServer实例:允许python程 ...
- 在我的新书里,尝试着用股票案例讲述Python爬虫大数据可视化等知识
我的新书,<基于股票大数据分析的Python入门实战>,预计将于2019年底在清华出版社出版. 如果大家对大数据分析有兴趣,又想学习Python,这本书是一本不错的选择.从知识体系上来看, ...
- 以股票案例入门基于SVM的机器学习
SVM是Support Vector Machine的缩写,中文叫支持向量机,通过它可以对样本数据进行分类.以股票为例,SVM能根据若干特征样本数据,把待预测的目标结果划分成“涨”和”跌”两种,从而实 ...
- Python里的黄金库,学会了你的工资至少翻一倍
作者:[已重置]链接:https://zhuanlan.zhihu.com/p/26054228来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 阅读本文大概需要5分钟 ...
- 用Python爬取股票数据,绘制K线和均线并用机器学习预测股价(来自我出的书)
最近我出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中用股票范例讲述Pyth ...
- 主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)
目录 主成分分析(PCA)——以葡萄酒数据集分类为例 1.认识PCA (1)简介 (2)方法步骤 2.提取主成分 3.主成分方差可视化 4.特征变换 5.数据分类结果 6.完整代码 总结: 1.认识P ...
- AJAX应用【股票案例】
股票案例 我们要做的是股票的案例,它能够无刷新地更新股票的数据.当鼠标移动到具体的股票中,它会显示具体的信息. 我们首先来看一下要做出来的效果: 服务器端分析 首先,从效果图我们可以看见很多股票基本信 ...
- 为什么在Python里推荐使用多进程而不是多线程
转载 http://bbs.51cto.com/thread-1349105-1.html 最近在看Python的多线程,经常我们会听到老手说:"Python下多线程是鸡肋,推荐使用多进程 ...
- 为什么在Python里推荐使用多进程而不是多线程?
最近在看Python的多线程,经常我们会听到老手说:“Python下多线程是鸡肋,推荐使用多进程!”,但是为什么这么说呢? 要知其然,更要知其所以然.所以有了下面的深入研究: 首先强调背景: 1. ...
随机推荐
- uni-app开发经验分享十五: uni-app 蓝牙打印功能
最近在做uni-app项目时,遇到了需要蓝牙打印文件的功能需要制作,在网上找到了一个教程,这里分享给大家. 引入tsc.js 简单得引入到自己所需要得页面中去,本次我们只要到了标签模式,他同时还有账单 ...
- 解决window10 和 ubuntu 双系统安装没有启动选项问题
win10 和Ubuntu 双系统安装在网上已经有很多例子了,这里就不在赘述了. 今天新买的笔记本,想安装双系统.正常安装完ubuntu 重启后没有选项. 解决方法一 下载和解压以后,按照以下的步骤安 ...
- 对于两个输入文件,即文件A 和文件B ,请编写MapReduce程序,对两个文件进行合并排除其中重复的内容,得到一个新的输出文件C。
package org.apache.hadoop.examples; import java.util.HashMap; import java.io.IOException; import jav ...
- Sapphire: Copying GC Without Stopping the World
https://people.cs.umass.edu/~moss/papers/jgrande-2001-sapphire.pdf Many concurrent garbage collectio ...
- https://github.com/golang/go/wiki/CommonMistakes
CommonMistakes https://golang.org/doc/faq#closures_and_goroutines Why is there no goroutine ID? ¶ Go ...
- webmvc 拦截器 允许跨域 跨域问题 sessionid不一样
package cn.com.yitong.ares.filter; import java.io.IOException; import javax.servlet.Filter;import ja ...
- JAXB学习(一):概述
pre.XML { background-color: rgba(255, 204, 204, 1); padding-left: 25px } JAXB是 Java Architecture for ...
- 切片声明 切片在内存中的组织方式 reslice
数组是具有相同 唯一类型 的一组已编号且长度固定的数据项序列(这是一种同构的数据结构),[5]int和[10]int是属于不同类型的.数组的编译时值初始化是按照数组顺序完成的(如下). 切片声明方式, ...
- 【算法】深度优先搜索(dfs)
突然发现机房里有很多人不会暴搜(dfs),所以写一篇他们能听得懂的博客(大概?) PS:万能 yuechi ---- 大法师怎么能不会呢?! 若有错误,请 dalao 指出. 前置 我知道即使很多人都 ...
- POSTGIS
https://blog.csdn.net/qq_35732147/article/details/85256640 官方文档:http://www.postgis.net/docs/ST_Buffe ...