强化学习 3—— 使用蒙特卡洛采样法(MC)解决无模型预测与控制问题
一、问题引入
回顾上篇强化学习 2 —— 用动态规划求解 MDP我们使用策略迭代和价值迭代来求解MDP问题
1、策略迭代过程:
- 1、评估价值 (Evaluate)
\]
- 2、改进策略(Improve)
\pi_{i+1}(s) = argmax_a \; q^{\pi_i}(s,a)
\]
2、价值迭代过程:
\]
然后提取最优策略 $ \pi $
\]
可以发现,对于这两个算法,有一个前提条件是奖励 R 和状态转移矩阵 P 我们是知道的,因此我们可以使用策略迭代和价值迭代算法。对于这种情况我们叫做 Model base。同理可知,如果我们不知道环境中的奖励和状态转移矩阵,我们叫做 Model free。
不过有很多强化学习问题,我们没有办法事先得到模型状态转化概率矩阵 P,这时如果仍然需要我们求解强化学习问题,那么这就是不基于模型(Model Free)的强化学习问题了。
其实稍作思考,大部分的环境都是 属于 Model Free 类型的,比如 熟悉的雅达利游戏等等。另外动态规划还有一个问题:需要在每一次回溯更新某一个状态的价值时,回溯到该状态的所有可能的后续状态。导致对于复杂问题计算量很大。
所以,我们本次探讨在 Model Free 情况下的策略评估方法,策略控制部分留到下篇讨论。对于 Model Free 类型的强化学习模型如下如所示:
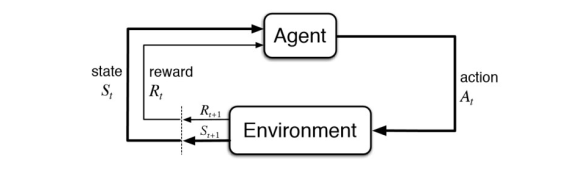
此时需要智能体直接和环境进行交互,环境根据智能体的动作返回下一个状态和相应的奖励给智能体。这时候就需要智能体搜集和环境交互的轨迹(Trajectory / episode)。
对于 Model Free 情况下的 策略评估,我们介绍两种采样方法。蒙特卡洛采样法(Monte Carlo)和时序差分法(Temporal Difference)
二、蒙特卡洛采样法(MC)
对于Model Free 我们不知道 奖励 R 和状态转移矩阵,那应该怎么办呢?很自然的,我们就想到,让智能体和环境多次交互,我们通过这种方法获取大量的轨迹信息,然后根据这些轨迹信息来估计真实的 R 和 P。这就是蒙特卡洛采样的思想。
蒙特卡罗法通过采样若干经历完整的状态序列(Trajectory / episode)来估计状态的真实价值。所谓的经历完整,就是这个序列必须是达到终点的。比如下棋问题分出输赢,驾车问题成功到达终点或者失败。有了很多组这样经历完整的状态序列,我们就可以来近似的估计状态价值,进而求解预测和控制问题了。
1、MC 解决预测问题
一个给定策略 \(\pi\) 的完整有 T 个状态的状态序列如下
\]
在马尔科夫决策(MDP)过程中,我们对价值函数 \(v_\pi(s)\) 的定义:
\]
可以看出每个状态的价值函数等于所有该状态收获的期望,同时这个收获是通过后续的奖励与对应的衰减乘积求和得到。那么对于蒙特卡罗法来说,如果要求某一个状态的状态价值,只需要求出所有的完整序列中该状态出现时候的收获再取平均值即可近似求解,也就是:
\]
\]
上面预测问题的求解公式里,我们有一个average的公式,意味着要保存所有该状态的收获值之和最后取平均。这样浪费了太多的存储空间。一个较好的方法是在迭代计算收获均值,即每次保存上一轮迭代得到的收获均值与次数,当计算得到当前轮的收获时,即可计算当前轮收获均值和次数。可以通过下面的公式理解:
\Downarrow \\
\mu_t = = \mu_{t-1} + \frac{1}{t}(x_t-\mu_{t-1})
\]
这样上面的状态价值公式就可以改写成:
v(S_t) \leftarrow v(S_t) + \frac{1}{N(S_t)}(G_t-v(S_t))
\]
这样我们无论数据量是多还是少,算法需要的内存基本是固定的 。我们可以把上面式子中 \(\frac{1}{N(S_t)}\) 看做一个超参数 \(\alpha\) ,可以代表学习率。
\]
对于动作价值函数\(Q(S_t, A_t)\), 类似的有:
\]
2、MC 解决控制问题
MC 求解控制问题的思路和动态规划策略迭代思路类似。在动态规划策略迭代算法中,每轮迭代先做策略评估,计算出价值 \(v_k(s)\) ,然后根据一定的方法(比如贪心法)更新当前 策略 \(\pi\) 。最后得到最优价值函数 \(v_*\) 和最优策略\(\pi_*\) 。在文章开始处有公式,还请自行查看。
对于蒙特卡洛算法策略评估时一般时优化的动作价值函数 \(q_*\),而不是状态价值函数 \(v_*\) 。所以评估方法是:
\]
蒙特卡洛还有一个不同是一般采用\(\epsilon - 贪婪法\)更新。\(\epsilon -贪婪法\)通过设置一个较小的 \(\epsilon\) 值,使用 \(1-\epsilon\) 的概率贪婪的选择目前认为有最大行为价值的行为,而 \(\epsilon\) 的概率随机的从所有 m 个可选行为中选择,具体公式如下:
\begin{cases}
\epsilon/|A| + 1 - \epsilon, & \text{if $a^* = argmax_a \; q(s,a)$} \\
\epsilon/|A|, & \text{otherwise}
\end{cases}
\]
在实际求解控制问题时,为了使算法可以收敛,一般 \(\epsilon\) 会随着算法的迭代过程逐渐减小,并趋于0。这样在迭代前期,我们鼓励探索,而在后期,由于我们有了足够的探索量,开始趋于保守,以贪婪为主,使算法可以稳定收敛。
Monte Carlo with \(\epsilon - Greedy\) Exploration 算法如下:

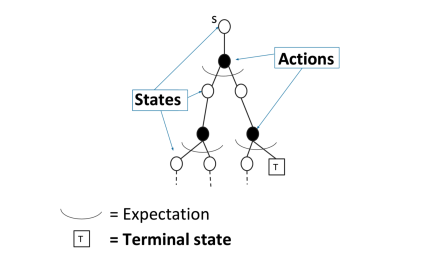
3、在 策略评估问题中 MC 和 DP 的不同
对于动态规划(DP)求解
通过 bootstrapping上个时刻次评估的价值函数 \(v_{i-1}\) 来求解当前时刻的 价值函数 \(v_i\) 。通过贝尔曼等式来实现:
\]
对于蒙特卡洛(MC)采样
MC通过一个采样轨迹来更新平均价值
\]
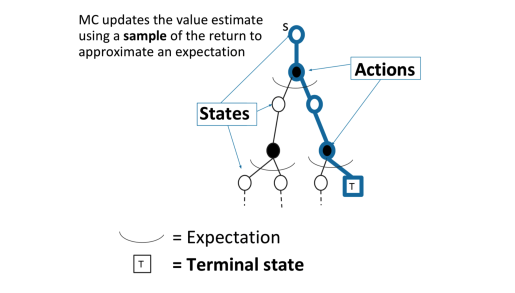
MC可以避免动态规划求解过于复杂,同时还可以不事先知道奖励和装填转移矩阵,因此可以用于海量数据和复杂模型。但是它也有自己的缺点,这就是它每次采样都需要一个完整的状态序列。如果我们没有完整的状态序列,或者很难拿到较多的完整的状态序列,这时候蒙特卡罗法就不太好用了。如何解决这个问题呢,就是下节要讲的时序差分法(TD)。
如果觉得文章写的不错,还请各位看官老爷点赞收藏加关注啊,小弟再此谢谢啦
参考资料:
B 站 周老师的强化学习纲要第三节上
强化学习 3—— 使用蒙特卡洛采样法(MC)解决无模型预测与控制问题的更多相关文章
- 伯克利、OpenAI等提出基于模型的元策略优化强化学习
基于模型的强化学习方法数据效率高,前景可观.本文提出了一种基于模型的元策略强化学习方法,实践证明,该方法比以前基于模型的方法更能够应对模型缺陷,还能取得与无模型方法相近的性能. 引言 强化学习领域近期 ...
- 强化学习(五)用时序差分法(TD)求解
在强化学习(四)用蒙特卡罗法(MC)求解中,我们讲到了使用蒙特卡罗法来求解强化学习问题的方法,虽然蒙特卡罗法很灵活,不需要环境的状态转化概率模型,但是它需要所有的采样序列都是经历完整的状态序列.如果我 ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 强化学习(六)时序差分在线控制算法SARSA
在强化学习(五)用时序差分法(TD)求解中,我们讨论了用时序差分来求解强化学习预测问题的方法,但是对控制算法的求解过程没有深入,本文我们就对时序差分的在线控制算法SARSA做详细的讨论. SARSA这 ...
- 强化学习(一)—— 基本概念及马尔科夫决策过程(MDP)
1.策略与环境模型 强化学习是继监督学习和无监督学习之后的第三种机器学习方法.强化学习的整个过程如下图所示: 具体的过程可以分解为三个步骤: 1)根据当前的状态 $s_t$ 选择要执行的动作 $ a_ ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 强化学习4-时序差分TD
之前讲到强化学习在不基于模型时可以用蒙特卡罗方法求解,但是蒙特卡罗方法需要在每次采样时生产完整序列,而在现实中,我们很可能无法生成完整序列,那么又该如何解决这类强化学习问题呢? 由贝尔曼方程 vπ(s ...
- 【转载】 强化学习(六)时序差分在线控制算法SARSA
原文地址: https://www.cnblogs.com/pinard/p/9614290.html ------------------------------------------------ ...
- 【转载】 强化学习(五)用时序差分法(TD)求解
原文地址: https://www.cnblogs.com/pinard/p/9529828.html ------------------------------------------------ ...
随机推荐
- 数据规整:连接、联合与重塑知识图谱-《利用Python进行数据分析》
所有内容整理自<利用Python进行数据分析>,使用MindMaster Pro 7.3制作,emmx格式,源文件已经上传Github,需要的同学转左上角自行下载或者右击保存图片. 其他章 ...
- OSCP Learning Notes - Scanning(2)
Scanning with Metasploite: 1. Start the Metasploite using msfconsole 2. search modules 3.Choose one ...
- 肝了两天IntelliJ IDEA 2020,解锁11种新姿势, 真香!!!
IDEA2020版本正式发布已经有3个月了,当时由于各方面原因(太懒)也没有去尝试新功能.于是这个周末特意去在另一个电脑上下载了最新版的IDEA,并尝试了一下.总的来说呢,体验上明显的提升. 作为一个 ...
- Trie——解决字符串搜索、异或最值问题
Trie--解决字符串搜索.异或最值问题 在说到Trie之前,我们设想如下问题: 给我们1e5个由小写字母构成的不重复的字符串,每个字符串长度不超过6,之后是1e5次查询操作,每次给我们一个字符串,要 ...
- go : 连接数据库并插入数据
package main import ( "database/sql" "fmt" "log" "net/http" ...
- 数据库分布式事务XA规范介绍及Mysql底层实现机制
1. 引言 分布式事务主要应用领域主要体现在数据库领域.微服务应用领域.微服务应用领域一般是柔性事务,不完全满足ACID特性,特别是I隔离性,比如说saga不满足隔离性,主要是通过根据分支事务执行成功 ...
- 感知机(perceptron)原理总结
目录 1. 感知机原理 2. 损失函数 3. 优化方法 4. 感知机的原始算法 5. 感知机的对偶算法 6. 从图形中理解感知机的原始算法 7. 感知机算法(PLA)的收敛性 8. 应用场景与缺陷 9 ...
- Mysql5.7前后修改用户密码变化
本文主要强调修改密码的sql语句变化.如果是root密码忘记了,请参考Mysql忘记root密码怎么解决 Mysql 5.7以前修改密码 update mysql.user set password= ...
- Java+MySQL企业级实训全套课程
总纲 JAVA基础部分 教学视频:第一讲:Java入门与环境搭建 提取码:h9vm第二讲:变量与运算符 提取码:928t第三讲:顺序结构及条件结构 提取码:3v1l第四讲:while ...
- SPRING 阅读--JdkDynamicAopProxy
一.简介 JdkDynamicAopProxy 代理类是spring 默认的JDK动态的代理类实现.它实现了Java 动态代理接口InvocationHandler接口和Spring定义的AopPro ...