强化学习(六)时序差分在线控制算法SARSA
在强化学习(五)用时序差分法(TD)求解中,我们讨论了用时序差分来求解强化学习预测问题的方法,但是对控制算法的求解过程没有深入,本文我们就对时序差分的在线控制算法SARSA做详细的讨论。
SARSA这一篇对应Sutton书的第六章部分和UCL强化学习课程的第五讲部分。
1. SARSA算法的引入
SARSA算法是一种使用时序差分求解强化学习控制问题的方法,回顾下此时我们的控制问题可以表示为:给定强化学习的5个要素:状态集$S$, 动作集$A$, 即时奖励$R$,衰减因子$\gamma$, 探索率$\epsilon$, 求解最优的动作价值函数$q_{*}$和最优策略$\pi_{*}$。
这一类强化学习的问题求解不需要环境的状态转化模型,是不基于模型的强化学习问题求解方法。对于它的控制问题求解,和蒙特卡罗法类似,都是价值迭代,即通过价值函数的更新,来更新当前的策略,再通过新的策略,来产生新的状态和即时奖励,进而更新价值函数。一直进行下去,直到价值函数和策略都收敛。
再回顾下时序差分法的控制问题,可以分为两类,一类是在线控制,即一直使用一个策略来更新价值函数和选择新的动作。而另一类是离线控制,会使用两个控制策略,一个策略用于选择新的动作,另一个策略用于更新价值函数。
我们的SARSA算法,属于在线控制这一类,即一直使用一个策略来更新价值函数和选择新的动作,而这个策略是$\epsilon-$贪婪法,在强化学习(四)用蒙特卡罗法(MC)求解中,我们对于$\epsilon-$贪婪法有详细讲解,即通过设置一个较小的$\epsilon$值,使用$1−\epsilon$的概率贪婪地选择目前认为是最大行为价值的行为,而用$\epsilon$的概率随机的从所有m个可选行为中选择行为。用公式可以表示为:$$\pi(a|s)= \begin{cases} \epsilon/m + 1- \epsilon & {if\; a^{*} = \arg\max_{a \in A}Q(s,a)}\\ \epsilon/m & {else} \end{cases}$$
2. SARSA算法概述
作为SARSA算法的名字本身来说,它实际上是由S,A,R,S,A几个字母组成的。而S,A,R分别代表状态(State),动作(Action),奖励(Reward),这也是我们前面一直在使用的符号。这个流程体现在下图:
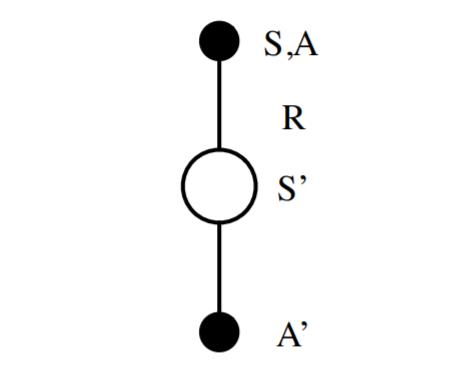
在迭代的时候,我们首先基于$\epsilon-$贪婪法在当前状态$S$选择一个动作$A$,这样系统会转到一个新的状态$S'$, 同时给我们一个即时奖励$R$, 在新的状态$S'$,我们会基于$\epsilon-$贪婪法在状态$S‘’$选择一个动作$A'$,但是注意这时候我们并不执行这个动作$A'$,只是用来更新的我们的价值函数,价值函数的更新公式是:$$Q(S,A) = Q(S,A) + \alpha(R+\gamma Q(S',A') - Q(S,A))$$
其中,$\gamma$是衰减因子,$\alpha$是迭代步长。这里和蒙特卡罗法求解在线控制问题的迭代公式的区别主要是,收获$G_t$的表达式不同,对于时序差分,收获$G_t$的表达式是$R+\gamma Q(S',A')$。这个价值函数更新的贝尔曼公式我们在强化学习(五)用时序差分法(TD)求解第2节有详细讲到。
除了收获$G_t$的表达式不同,SARSA算法和蒙特卡罗在线控制算法基本类似。
3. SARSA算法流程
下面我们总结下SARSA算法的流程。
算法输入:迭代轮数$T$,状态集$S$, 动作集$A$, 步长$\alpha$,衰减因子$\gamma$, 探索率$\epsilon$,
输出:所有的状态和动作对应的价值$Q$
1. 随机初始化所有的状态和动作对应的价值$Q$. 对于终止状态其$Q$值初始化为0.
2. for i from 1 to T,进行迭代。
a) 初始化S为当前状态序列的第一个状态。设置$A$为$\epsilon-$贪婪法在当前状态$S$选择的动作。
b) 在状态$S$执行当前动作$A$,得到新状态$S'$和奖励$R$
c) 用$\epsilon-$贪婪法在状态$S'$选择新的动作$A'$
d) 更新价值函数$Q(S,A)$:$$Q(S,A) = Q(S,A) + \alpha(R+\gamma Q(S',A') - Q(S,A))$$
e) $S=S', A=A'$
f) 如果$S'$是终止状态,当前轮迭代完毕,否则转到步骤b)
这里有一个要注意的是,步长$\alpha$一般需要随着迭代的进行逐渐变小,这样才能保证动作价值函数$Q$可以收敛。当$Q$收敛时,我们的策略$\epsilon-$贪婪法也就收敛了。
4. SARSA算法实例:Windy GridWorld
下面我们用一个著名的实例Windy GridWorld来研究SARSA算法。
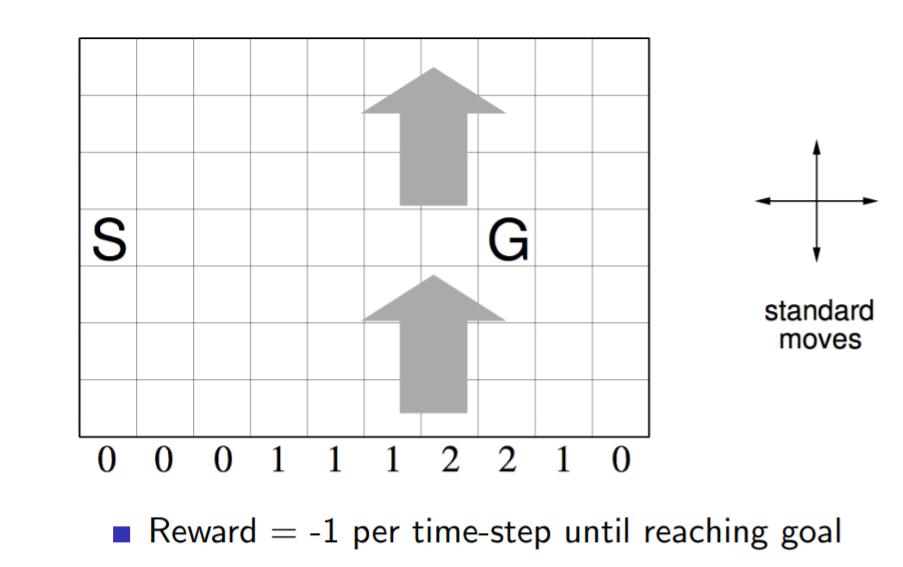
如下图一个10×7的长方形格子世界,标记有一个起始位置 S 和一个终止目标位置 G,格子下方的数字表示对应的列中一定强度的风。当个体进入该列的某个格子时,会按图中箭头所示的方向自动移动数字表示的格数,借此来模拟世界中风的作用。同样格子世界是有边界的,个体任意时刻只能处在世界内部的一个格子中。个体并不清楚这个世界的构造以及有风,也就是说它不知道格子是长方形的,也不知道边界在哪里,也不知道自己在里面移动移步后下一个格子与之前格子的相对位置关系,当然它也不清楚起始位置、终止目标的具体位置。但是个体会记住曾经经过的格子,下次在进入这个格子时,它能准确的辨认出这个格子曾经什么时候来过。格子可以执行的行为是朝上、下、左、右移动一步,每移动一步只要不是进入目标位置都给予一个 -1 的惩罚,直至进入目标位置后获得奖励 0 同时永久停留在该位置。现在要求解的问题是个体应该遵循怎样的策略才能尽快的从起始位置到达目标位置。
逻辑并不复杂,完整的代码在我的github。这里我主要看一下关键部分的代码。
算法中第2步步骤a,初始化$S$,使用$\epsilon-$贪婪法在当前状态$S$选择的动作的过程:
# initialize state
state = START # choose an action based on epsilon-greedy algorithm
if np.random.binomial(1, EPSILON) == 1:
action = np.random.choice(ACTIONS)
else:
values_ = q_value[state[0], state[1], :]
action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)])
算法中第2步步骤b,在状态$S$执行当前动作$A$,得到新状态$S'$的过程,由于奖励不是终止就是-1,不需要单独计算:
def step(state, action):
i, j = state
if action == ACTION_UP:
return [max(i - 1 - WIND[j], 0), j]
elif action == ACTION_DOWN:
return [max(min(i + 1 - WIND[j], WORLD_HEIGHT - 1), 0), j]
elif action == ACTION_LEFT:
return [max(i - WIND[j], 0), max(j - 1, 0)]
elif action == ACTION_RIGHT:
return [max(i - WIND[j], 0), min(j + 1, WORLD_WIDTH - 1)]
else:
assert False
算法中第2步步骤c,用$\epsilon-$贪婪法在状态$S‘$选择新的动作$A'$的过程:
next_state = step(state, action)
if np.random.binomial(1, EPSILON) == 1:
next_action = np.random.choice(ACTIONS)
else:
values_ = q_value[next_state[0], next_state[1], :]
next_action = np.random.choice([action_ for action_, value_ in enumerate(values_) if value_ == np.max(values_)])
算法中第2步步骤d,e, 更新价值函数$Q(S,A)$以及更新当前状态动作的过程:
# Sarsa update
q_value[state[0], state[1], action] += \
ALPHA * (REWARD + q_value[next_state[0], next_state[1], next_action] -
q_value[state[0], state[1], action])
state = next_state
action = next_action
代码很简单,相信大家对照算法,跑跑代码,可以很容易得到这个问题的最优解,进而搞清楚SARSA算法的整个流程。
5. SARSA($\lambda$)
在强化学习(五)用时序差分法(TD)求解中我们讲到了多步时序差分$TD(\lambda)$的价值函数迭代方法,那么同样的,对应的多步时序差分在线控制算法,就是我们的$SARSA(\lambda)$。
$TD(\lambda)$有前向和后向两种价值函数迭代方式,当然它们是等价的。在控制问题的求解时,基于反向认识的 $SARSA(\lambda)$算法将可以有效地在线学习,数据学习完即可丢弃。因此 $SARSA(\lambda)$算法默认都是基于反向来进行价值函数迭代。
在上一篇我们讲到了$TD(\lambda)$状态价值函数的反向迭代,即:$$\delta_t = R_{t+1} + \gamma V(S_{t+1}) -V(S_t)$$$$V(S_t) = V(S_t) + \alpha\delta_tE_t(S)$$
对应的动作价值函数的迭代公式可以找样写出,即:$$\delta_t = R_{t+1} + \gamma Q(S_{t+1},A_{t+1}) -Q(S_t, A_t)$$$$Q(S_t, A_t) = Q(S_t, A_t) + \alpha\delta_tE_t(S,A)$$
除了状态价值函数$ Q(S,A) $的更新方式,多步参数$\lambda$以及反向认识引入的效用迹$E(S,A)$,其余算法思想和SARSA类似。这里我们总结下$SARSA(\lambda)$的算法流程。
算法输入:迭代轮数$T$,状态集$S$, 动作集$A$, 步长$\alpha$,衰减因子$\gamma$, 探索率$\epsilon$, 多步参数$\lambda$
输出:所有的状态和动作对应的价值$Q$
1. 随机初始化所有的状态和动作对应的价值$Q$. 对于终止状态其$Q$值初始化为0.
2. for i from 1 to T,进行迭代。
a) 初始化所有状态动作的效用迹$E$为0,初始化S为当前状态序列的第一个状态。设置$A$为$\epsilon-$贪婪法在当前状态$S$选择的动作。
b) 在状态$S$执行当前动作$A$,得到新状态$S'$和奖励$R$
c) 用$\epsilon-$贪婪法在状态$S'$选择新的动作$A'$
d) 更新效用迹函数$E(S,A) $和TD误差$\delta$: $$E(S,A) = E(S,A)+1$$$$\delta= R_{t+1} + \gamma Q(S_{t+1},A_{t+1}) -Q(S_t, A_t)$$
e) 对当前序列所有出现的状态s和对应动作a, 更新价值函数$Q(s,a)$和效用迹函数$E(s,a) $:$$Q(s,a) = Q(s,a) + \alpha\delta E(s,a)$$$$E(s,a) = \gamma\lambda E(s,a)$$
f) $S=S', A=A'$
g) 如果$S'$是终止状态,当前轮迭代完毕,否则转到步骤b)
对于步长$\alpha$,和SARSA一样,一般也需要随着迭代的进行逐渐变小才能保证动作价值函数$Q$收敛。
6. SARSA小结
SARSA算法和动态规划法比起来,不需要环境的状态转换模型,和蒙特卡罗法比起来,不需要完整的状态序列,因此比较灵活。在传统的强化学习方法中使用比较广泛。
但是SARSA算法也有一个传统强化学习方法共有的问题,就是无法求解太复杂的问题。在 SARSA 算法中,$Q(S,A)$ 的值使用一张大表来存储的,如果我们的状态和动作都达到百万乃至千万级,需要在内存里保存的这张大表会超级大,甚至溢出,因此不是很适合解决规模很大的问题。当然,对于不是特别复杂的问题,使用SARSA还是很不错的一种强化学习问题求解方法。
下一篇我们讨论SARSA的姊妹算法,时序差分离线控制算法Q-Learning。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
强化学习(六)时序差分在线控制算法SARSA的更多相关文章
- 【转载】 强化学习(六)时序差分在线控制算法SARSA
原文地址: https://www.cnblogs.com/pinard/p/9614290.html ------------------------------------------------ ...
- 强化学习(七)时序差分离线控制算法Q-Learning
在强化学习(六)时序差分在线控制算法SARSA中我们讨论了时序差分的在线控制算法SARSA,而另一类时序差分的离线控制算法还没有讨论,因此本文我们关注于时序差分离线控制算法,主要是经典的Q-Learn ...
- 【转载】 强化学习(七)时序差分离线控制算法Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9669263.html ------------------------------------------------ ...
- 强化学习8-时序差分控制离线算法Q-Learning
Q-Learning和Sarsa一样是基于时序差分的控制算法,那两者有什么区别呢? 这里已经必须引入新的概念 时序差分控制算法的分类:在线和离线 在线控制算法:一直使用一个策略选择动作和更新价值函数, ...
- 强化学习4-时序差分TD
之前讲到强化学习在不基于模型时可以用蒙特卡罗方法求解,但是蒙特卡罗方法需要在每次采样时生产完整序列,而在现实中,我们很可能无法生成完整序列,那么又该如何解决这类强化学习问题呢? 由贝尔曼方程 vπ(s ...
- 强化学习(五)用时序差分法(TD)求解
在强化学习(四)用蒙特卡罗法(MC)求解中,我们讲到了使用蒙特卡罗法来求解强化学习问题的方法,虽然蒙特卡罗法很灵活,不需要环境的状态转化概率模型,但是它需要所有的采样序列都是经历完整的状态序列.如果我 ...
- 【转载】 强化学习(五)用时序差分法(TD)求解
原文地址: https://www.cnblogs.com/pinard/p/9529828.html ------------------------------------------------ ...
- 强化学习之 免模型学习(model-free based learning)
强化学习之 免模型学习(model-free based learning) ------ 蒙特卡罗强化学习 与 时序查分学习 ------ 部分节选自周志华老师的教材<机器学习> 由于现 ...
- 【整理】强化学习与MDP
[入门,来自wiki] 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的 ...
随机推荐
- 在Mybatis-spring上基于注解的数据源实现方案
一.遇到的痛点 最近在学习Spring-boot过程中,涉及到操作数据库.按照DOC引入mybatis-spring-boot-starter,然后按照套路配置application.properti ...
- orcl数据库先决条件检查时失败
在服务里面开启下面服务,在cmd输入 services.msc 就能打开[服务] 在cmd输入以下命令 我的是server服务没开,然后开了资源共享,就安装成功了
- bzoj3199 [Sdoi2013]escape
这题真tm是醉了. 就是对于每个亲戚,利用其它的亲戚对他半平面交求出其控制的范围,然后随便跑个最短路就行了 n=0卡了我一下午////// #include <cstdio> #inclu ...
- 服务网关基于RPC的用法
企业为了保护内部系统的安全性,内网与外网都是隔离的,企业的服务应用都是运行在内网环境中,为了安全的考量,一般都不允许外部直接访问.API网关部署在防火墙外面,起到一层挡板作用,内部系统只接受API网关 ...
- CentOS7搭建本地YUM仓库,并定期同步阿里云源
CentOS7同步阿里云镜像rpm包并自建本地yum仓库 系统环境 # cat /etc/centos-release CentOS Linux release 7.6.1810 (Core) # u ...
- Spire高效稳定的.NET组件
年末将至,又到了一年一度的收集发票时间,平时零零碎碎的花钱都是不在意开发票,现在好了,到处找发票来报销,简直头大, 东拼西凑,终于搞定了全部发票,大伙多余的发票,麻烦艾特我一下啊,不限日期,能开发票的 ...
- ABP学习笔记(1)-使用mysql
前言 开始学习ABP啦 下载官方模板 下载地址: https://aspnetboilerplate.com/Templates 我这边选择的是.NET Core+VUE 移除SqlServe ...
- python接口自动化(二十)--token登录(详解)
简介 为了验证用户登录情况以及减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮.有些登录不是用 cookie 来验证的,是用 token 参数来判断是否登录.token 传参有两种一种是放在请 ...
- Caffe源码理解3:Layer基类与template method设计模式
目录 写在前面 template method设计模式 Layer 基类 Layer成员变量 构造与析构 SetUp成员函数 前向传播与反向传播 其他成员函数 参考 博客:blog.shinelee. ...
- 使用LXD搭建Web网站
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由独木桥先生 发表于云+社区专栏 介绍 Linux的容器是Linux的一组进程,通过使用Linux内核功能与系统隔离.它是一个类似于虚拟 ...