大数据谢列3:Hdfs的HA实现
在之前的文章:大数据系列:一文初识Hdfs ,
大数据系列2:Hdfs的读写操作 中Hdfs的组成、读写有简单的介绍。
在里面介绍Secondary NameNode和Hdfs读写的流程。
并且在文章结尾也说了,Secondary NameNode并不是我常说的HA,(High Availability)。
本文承接之前的内容,对Hdfs的HA实现做个简单的介绍。
NameNode的重要性
先来看看Hdfs读写的流程图:

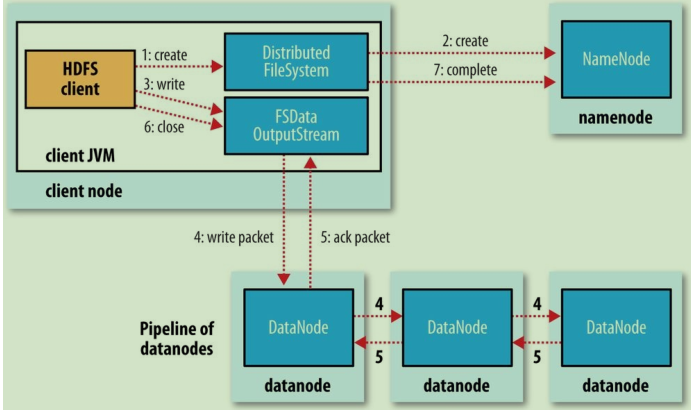
可以看到无论是读还是写,我们都必须和存储元数据的NameNode进行交互。
一旦NameNode出问题,整个集群的读写基本上就凉凉了。
所以,在设计的时候本就有做一些容错的措施。
容错的措施
如果NameNode除了问题,整个文件Hdfs将不可用。
摄像一个场景:
如果以为某种原因我们运行NameNode的机器被删除。
此时所有Hdfs的文件都回丢失,因为我们虽然在DataNode中存储了文件的NameNode信息,但是我们无法通过这些NameNode重新构建文件。
所以让NameNode有一定抗拒错误的能力是很重要的。
而Hadoop本身提供了两种机制。
备份元数据
第一种机制:
将Hdfs元数据中持久化状态的文件做多个备份。
Hadoop 可以进行相关的配置,把这些持久的状态备份到多个文件系统。这个过程是同步且原子的 。
一般都是配置为本分到本例磁盘,同时远程NFS 挂载
Secondary NameNode
第二种机制:
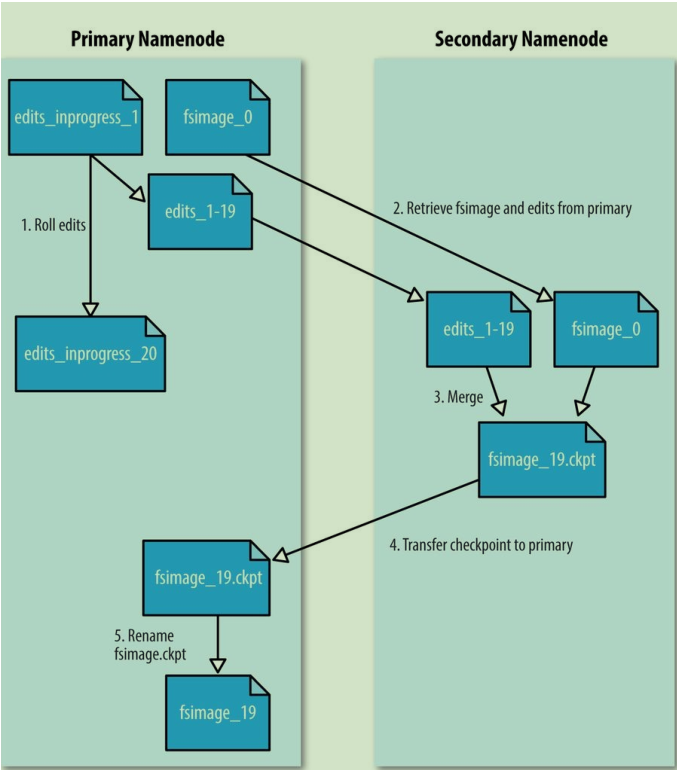
运行一个Secondary NameNode,负责定期合并名称namespace iamge和edit log,以防止edit log变得过大。
合并流程如下,详细过程之前有介绍过,此处不累赘:
存在问题
虽然有两个方式让Hdfs有一定的容错能力,但是还是存在一些问题。
Secondary NameNode拥有一个合并的namespace iamge像的副本,在NameNode失败时可以使用该iamge。
但是Secondary NameNode中的状态是滞后于NameNode的,如果NameNode是宕机的情况下,数据丢失必不可少。
此时通常的做法是将NFS上的NameNode元数据文件复制到Secondary NameNode,并将其作为新的NameNode运行。
因为NFS中的与
NameNode的元数据是同步的,所以可以通过NFS中的数据恢复。
在多个文件系统上复制NameNode元数据和使用Secondary NameNode创建checkpoints的组合可以防止数据丢失。
然而这中组合的机制并不能提供Hdfs的高可用性。
主要原因是这种方式恢复太耗时间了。
NameNode是唯一的存储了文件与Blcok映射关系的元数据存储库
,一旦它罢工,所有的Client的作业包括Mapreduce、读、写、列出文件无法进行。
在新的NameNode上线之前,整个集群处于停止服务的状态
如果NameNode要重新上线服务需要经过一下的步骤:
- 加载明明空间到内存
- 重放
edit log - 从
DataNode接收足够的NameNode报告并离开安全模式。
在具有许多文件和NameNode的大型集群上,NameNode的冷启动所需的时间可能是30分钟或更长。
这么拉垮可不太能接受,无论是日常运维还是计划停机之类的操作。
所以,归根结底就是NameNode仍然是存在单点故障(SPOF,Single Point Of Failure)
下面就看看怎么解决这个问题。
HDFS high availability (HA)
一般情况下会有两个场景和HA息息相关。
- 在出现计划外事件(如服务器宕机)的情况下,在重新启动
NameNode之前,集群将不可用。 - 有计划的维护事件,例如
NameNode机器上的软件或硬件升级,将导致集群停机。
为了解决上述的问题,Hadoop 提供了HDFS high availability (HA)的支持。
通过active-standby的方式配置两个NameNode(3.0后可以支持超过两个),在Active/Passive动配置中使用热备份。
在机器崩溃的情况下,实现快速故障转移到新的NameNode,
或者出于计划维护的目的,允许管理员发起优雅的故障转移。
为了实现这个目标,在架构层面需要做一些改变:
NameNode建必须要通过一些高可用的共享内存共享edit log,一旦standby NameNode接管工作的时候,它通过读取共享edit log直至结尾以保持它的状态与active NameNode一致,然后继续读取由activeNameNode写入的新条目。DataNodes必须向两个NameNode发送NameNode报告,因为NameNode映射关系是存储在NameNode的内存而不是磁盘。- 客户端必须使用一种机制来处理
NameNode失效问题,让用户对于NameNode的切换是透明的。(就是不需要用户自己去切换NameNode) standby NameNode应该承担之前Secondary NameNode的角色,定期为active NameNode的命名空间创建检查点。
在典型的HA集群中,会配置两个或更多的NameNodes,但是在任何时候,都只能有一个NameNode处于活动状态,其他NameNode处于备用状态。
Active状态的NameNode负责集群中的所有Client的操作,
Standby状态的NameNode仅需要保存足够的状态的即可。
有两种实现方式
Quorum Journal Manager (QJM)
QJM是一个专用的HDFS实现,设计的唯一目的是提供高度可用的编辑日志,并且是大多数HDFS安装的推荐选择。
QJM作为一组journalnodes(JNs)独立守护进程运行,每次编辑都必须写入大部分JNs节点。
为了使备节点与主节点保持状态同步,两个节点都与JNs进程通信。
Active NameNode执行任何关于名称空间修改时,它会持久地记录修改记录到大部分的JNs。
通常,有三个journal节点,因此系统可以容忍其中一个节点的丢失。
尽管这种方式类似ZooKeeper工作方式,但是必须说明的是QJM实现没有使用ZooKeeper
同时还要注意,HDFS的HA确实使用了ZooKeeper来选择activeNameNode,后续会介绍
standby NameNode能够从JNs中读取edits ,并不断监视它们对edit log的修改。
当standby NameNode````看到这edits时,它将它们应用到自己的名称空间。
standby NameNode必须持有集群中NameNode位置的最新信息。
所以,DataNodes需要配置所有NameNode的位置,并向所有NameNode发送NameNode 位置信息和心跳。
因为standby NameNode 在内存中有最新的状态:最新的edit log和最新的NameNode映射
所以Active NameNode发生故障时,standby NameNode可以很快接管(在几十秒内)。
实际观察到的故障转移时间要长一些(大约一分钟左右),因为系统需要保守地判断active
NameNode是否发生了故障。
NFS
与QJM方共享不同,edit log记录到JNs不同,
此处的共享内存一般使用过一个支持NFS(Network File System:网络文件系统)的NAS(Network Attached Storage:网络附属存储)创建应共享文件,通常会挂载在每隔一个NameNode的机器上,NameNode可以对其进行读、写操作。
但是,目前只支持一个共享edit目录。
因此,系统的可用性受到共享edit目录的可用性的限制,
为了消除所有单点故障,共享编辑目录需要有冗余。
具体来说,就是到存储的多条网络路径,以及存储本身的冗余(磁盘、网络和电源)。
所以,建议使用高质量的专用NAS设备作为共享存储服务器,而不是简单的Linux服务器。
故障转移和规避
在HA集群中,standby NameNode还执行名称空间状态检查点操作,
因此在HA集群中没有必要运行 Secondary NameNode, CheckpointNode, or BackupNode。
同时无论是QJM还是NFS中,
在同一时刻只有一个NameNode处于Active是至关重要的。
否则,名称空间状态将很快在两者之间出现分歧(脑裂),可能导致数据丢失或其他不正确的结果。
为了避免这个情况,同一时间只允许一个NameNode 对 JournalNodes 或 NFS的共享内存写入。
在故障转移期间,即将成为Active状态的NameNode将接管向共享eidt文件写入数据的角色,
这将有效地阻止其他NameNode继续处于Active状态,从而允许新的Active状态安全地进行故障转移。
但是要如何实现呢?
故障转移
从active NameNode到standby NameNode```` 的过渡由系统中称为故障转移控制器(failover controller)的新实体进行管理。
可以理解为
active NameNode挂了standby NameNode上位的过程
有各种各样的故障转移控制器,但是默认的实现是使用ZooKeeper来确保只有一个NameNode是active的。
每个NameNode运行一个轻量级的故障转移控制器进程,
它的任务是监视它的NameNode是否出现故障(使用一个简单的心跳机制),
并在NameNode出现故障时触发故障转移。
故障转移也可以由管理员手动启动,
例如,在例行维护的情况下。
这被称为优雅的故障转移( graceful failover),因为故障转移控制器为两个NameNode安排了有序的角色转换。
但是,
在意料之外的故障转移的情况下,不可能确保失败的NameNode已经停止运行。
例如,网络或网络分区速度较慢的情况下,
即使以前activeNameNode仍然在运行
也可能会触发故障转移。
为了避免这种情况,HA实现了确保以前active NameNode不会造成任不良影响的方法称为规避(fencing)。
规避
JNs一次只允许一个NameNode写入编辑日志;
但是,以前活跃的NameNode仍然可能向客户端提供过时的读请求,
因此可以设置一个SSH 规避命令来杀死NameNode进程。
对于使用NFS文件的共享edit log,因为很难控制一次只允许一个NameNode写入,
需要更强有力地规避方法,一般可以选择如下方法:
- 撤销
NameNode对共享存储目录的访问(通常使用特定于供应商的NFS命令) - 通过远程管理命屏蔽相应网络端口(port)
- 做绝一点可以通过一个叫做“一枪爆头”方式进行规避(
STONITH,short the other node in the head),通过一个特定的供电单元对相应的NameNode进行断电操作。
这就是推荐使用QJM的主要原因。
有了上述只是储备,我们很容易就可以把这个架构图画出来,以QJM为例
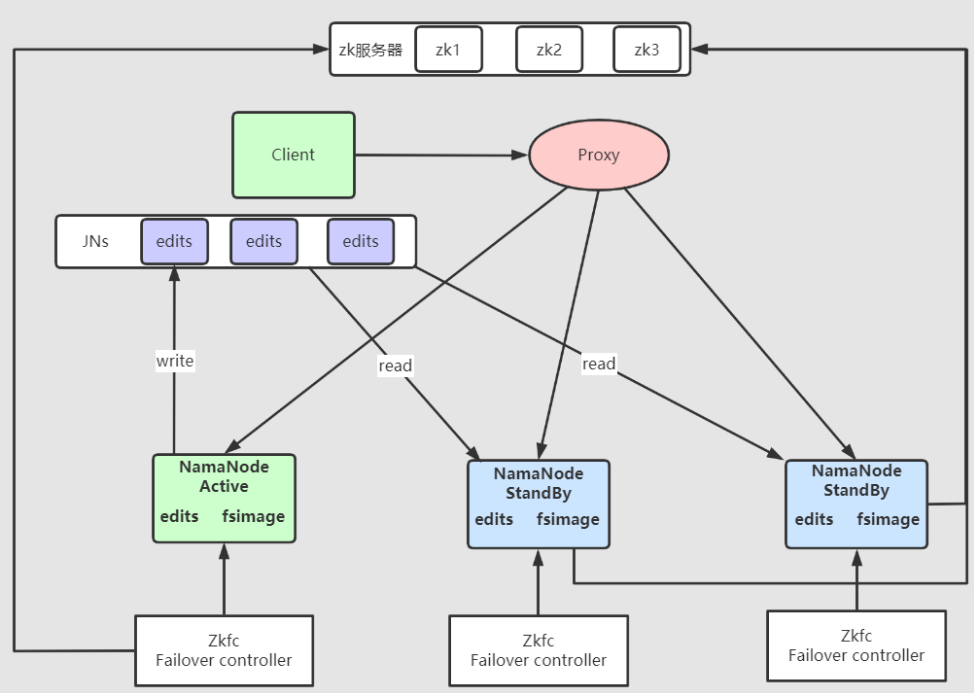
那么转移过程大致如下:
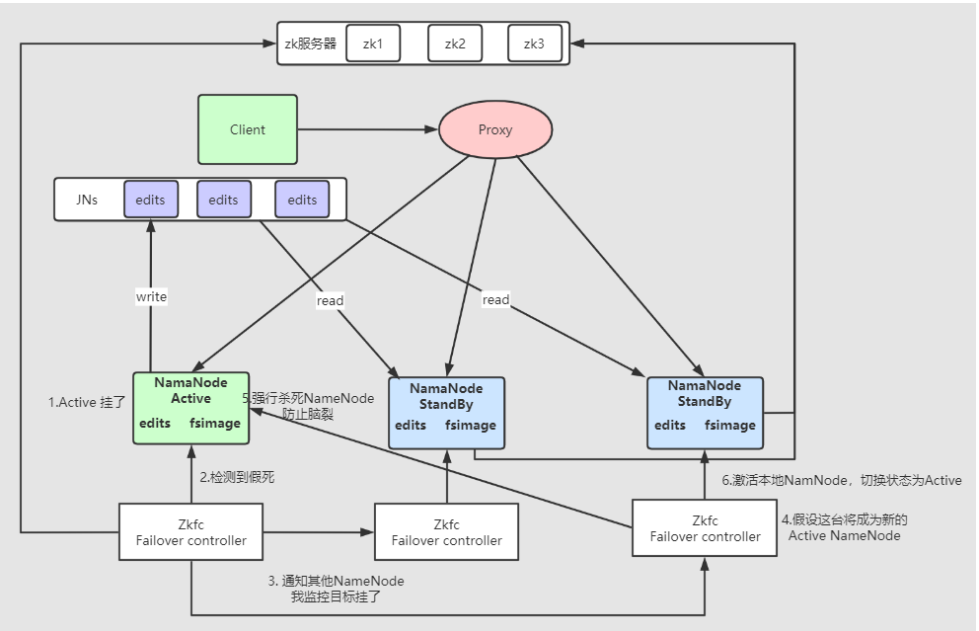
客户端故障转移
对于客户端而言,我们要让用户对于故障转移是无感的。
可以通过配置文件实现一个故障转移
在配置文件中通过配置几个参数实现故障转移:
dfs.nameservices:Hdfs逻辑名称
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
dfs.ha.NameNodes.[nameservice ID]:nameservice中每个NameNode的唯一标识符
<property>
<name>dfs.ha.``NameNode``s.mycluster</name>
<value>nn1,nn2, nn3</value>
</property>
dfs.NameNode.rpc-address.[nameservice ID].[name node ID]:每个NameNode监听的完全限定RPC地址
<property>
<name>dfs.``NameNode``.rpc-address.mycluster.nn1</name>
<value>machine1.example.com:8020</value>
</property>
<property>
<name>dfs.``NameNode``.rpc-address.mycluster.nn2</name>
<value>machine2.example.com:8020</value>
</property>
<property>
<name>dfs.``NameNode``.rpc-address.mycluster.nn3</name>
<value>machine3.example.com:8020</value>
</property>
更多的配置可以查看
NameNode HA With QJM
NameNode HA With NFS
关于HA暂时介绍到这里,后续有空再进行详细的介绍。
之后会写一下关于Yarn的文章,感兴趣可以关注【兔八哥杂谈】
大数据谢列3:Hdfs的HA实现的更多相关文章
- 大数据(3) - 高可用 HDFS HA
HDFS HA高可用 1 HA概述 1)所谓HA(high available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制 ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- 【大数据】Hadoop的高可用HA
第1章 HA高可用 1.1 HA概述 1)所谓HA(high available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障(single point of fa ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- 大数据 - hadoop基础概念 - HDFS
Hadoop之HDFS的概念及用法 1.概念介绍 Hadoop是Apache旗下的一个项目.他由HDFS.MapReduce.Hive.HBase和ZooKeeper等成员组成. HDFS是一个高度容 ...
- 大数据【二】HDFS部署及文件读写(包含eclipse hadoop配置)
一 原理阐述 1' DFS 分布式文件系统(即DFS,Distributed File System),指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连.该系统架构 ...
- 大数据开发实战:HDFS和MapReduce优缺点分析
一. HDFS和MapReduce优缺点 1.HDFS的优势 HDFS的英文全称是 Hadoop Distributed File System,即Hadoop分布式文件系统,它是Hadoop的核心子 ...
- 大数据:Hadoop(HDFS 的设计思路、设计目标、架构、副本机制、副本存放策略)
一.HDFS 的设计思路 1)思路 切分数据,并进行多副本存储: 2)如果文件只以多副本进行存储,而不进行切分,会有什么问题 缺点 不管文件多大,都存储在一个节点上,在进行数据处理的时候很难进行并行处 ...
- 我眼中的大数据(二)——HDFS
Hadoop的第一个产品是HDFS,可以说分布式文件存储是分布式计算的基础,也可见分布式文件存储的重要性.如果我们将大数据计算比作烹饪,那么数据就是食材,而Hadoop分布式文件系统HDFS就是烧菜的 ...
随机推荐
- Linux下安装ffmpeg,视频格式转换
下载ffmpeg 从ffmpeg官网:http://ffmpeg.org/download.html 下载最新的ffmpeg安装包,然后通过如下命令解压: 解压 ffmpeg-*.tar.bz2 文件 ...
- 高可用K8S构建3master+3node+keepalived+haproxy
视频地址:https://www.bilibili.com/video/BV1w4411y7Go?p=66 所需安装包在视频评论区 安装准备 系统: CentOS-7-x86_64-Minimal-1 ...
- MySQL的修仙者之旅,不来看看你的修为如何吗?
目录 因为我个人比较喜欢看修仙类的小说,所以本文的主体部分借用修仙者的修为等级,将学习旅程划分成:练气.筑基.结丹.元婴.化神.飞升六个段位,你可以看下你大概在哪个段位上哦! 本文目录: 我为什么要写 ...
- 码农英语四级考了6次,也能进知名IT外企
程序员学英语 这显然不是新鲜的话题,但再怎么重复强调都不过分! 为啥要学 IT是当今世界发展最快的行业,没有之一!作为其中的从业人员,要始终保持对最新技术的关注度,难免需要阅读英文新闻或文章 平时工作 ...
- mysql数据库的连接以及增删改查Java代码实现(转载)
每天叫醒自己的不是闹钟,而是梦想 数据库: create table t1(id int primary key not null auto_increment,name varchar(32),pa ...
- 第十八章节 BJROBOT 安卓手机 APP 建地图【ROS全开源阿克曼转向智能网联无人驾驶车】
1.把小车平放在地板上,用资料里的虚拟机,打开一个终端 ssh 过去主控端启动roslaunch znjrobotbringup.launch 2.在虚拟机端再打开一个终端,ssh 过去主控端启动ro ...
- javabean 数组对应yml中的写法
gate-info: gate-list: - channel: channel-one io-flag: I - channel: channel-two io-flag: E 上面的是 yml 文 ...
- kubectl常用命令(个人记录)
一.获取pod信息 1.获取当前集群运行的所有的pods的信息 kubectl get pod 2.获取当前集群运行的所有的pod运行在哪个节点 kubectl get pods -owide ...
- Docker环境下升级PostgreSQL
查阅PostgreSQL官方文档可以得知,官方提供了两种方式对数据库进行升级--pg_dumpall与pg_upgrade. pg_dumpall是将数据库转储成一个脚本文件,然后在新版数据库中可以直 ...
- notapai++ 使用小技巧
alt+鼠标右键 建 实现整体添加字符 例: 25001510153394032 25001510153394034 25001510153393963 25001510153392080 25001 ...