Caffe源码解析5:Conv_Layer
转载请注明出处,楼燚(yì)航的blog,http://home.cnblogs.com/louyihang-loves-baiyan/
Vision_layer里面主要是包括了一些关于一些视觉上的操作,比如卷积、反卷积、池化等等。这里的类跟data layer一样好很多种继承关系。主要包括了这几个类,其中CuDNN分别是CUDA版本,这里先不讨论,在这里先讨论ConvolutionLayer
- BaseConvolutionLayer
- ConvolutionLaye
- DeconvolutionLayer
- CuDNNConvolutionLayer
- Im2colLayer
- LRNLayer
- CuDNNLRNLayer
- CuDNNLCNLayer
- PoolingLayer
- CuDNNPoolingLayer
- SPPLayer
这里我画了一个类图,将关系梳理了一下:

BaseConvolutionLayer
其继承自Layer,是一个卷积以及反卷积操作的基类,首先我们来看BaseConvolutionLayer的LayerSetUp函数
void BaseConvolutionLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top)
//首先这里主要是在配置卷积kernel 的size,padding,stride以及inputs
ConvolutionParameter conv_param = this->layer_param_.convolution_param();
force_nd_im2col_ = conv_param.force_nd_im2col();
channel_axis_ = bottom[0]->CanonicalAxisIndex(conv_param.axis());
const int first_spatial_axis = channel_axis_ + 1;
const int num_axes = bottom[0]->num_axes();
num_spatial_axes_ = num_axes - first_spatial_axis;
CHECK_GE(num_spatial_axes_, 0);
vector<int> bottom_dim_blob_shape(1, num_spatial_axes_ + 1);
vector<int> spatial_dim_blob_shape(1, std::max(num_spatial_axes_, 1));
// 设置kernel的dimensions
kernel_shape_.Reshape(spatial_dim_blob_shape);
int* kernel_shape_data = kernel_shape_.mutable_cpu_data();
接着是设置相应的stride dimensions,对于2D,设置在h和w方向上的stride,代码太长列出简要的
pad_.Reshape(spatial_dim_blob_shape);
int* pad_data = pad_.mutable_cpu_data();
pad_data[0] = conv_param.pad_h();
pad_data[1] = conv_param.pad_w();
......一堆if else判断
对于kernel的pad也做相应设置
pad_.Reshape(spatial_dim_blob_shape);
int* pad_data = pad_.mutable_cpu_data();
pad_data[0] = conv_param.pad_h();
pad_data[1] = conv_param.pad_w();
接下来是对widhts 和bias左设置和填充,其中blob[0]里面存放的是filter weights,而blob[1]里面存放的是biases,当然biases是可选的,也可以没有
//设置相应的shape,并检查
vector<int> weight_shape(2);
weight_shape[0] = conv_out_channels_;
weight_shape[1] = conv_in_channels_ / group_;
bias_term_ = this->layer_param_.convolution_param().bias_term();
vector<int> bias_shape(bias_term_, num_output_);
//填充权重
this->blobs_[0].reset(new Blob<Dtype>(weight_shape));
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>(
this->layer_param_.convolution_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get());
//填充偏置项
if (bias_term_) {
this->blobs_[1].reset(new Blob<Dtype>(bias_shape));
shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>(
this->layer_param_.convolution_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get());
}
ConvolutionLayer
ConvolutionLayer继承了BaseConvolutionLayer,主要作用就是将一副image做卷积操作,使用学到的filter的参数和biaes。同时在Caffe里面,卷积操作做了优化,变成了一个矩阵相乘的操作。其中有两个比较主要的函数是im2col以及col2im。
图中上半部分是一个传统卷积,下图是一个矩阵相乘的版本
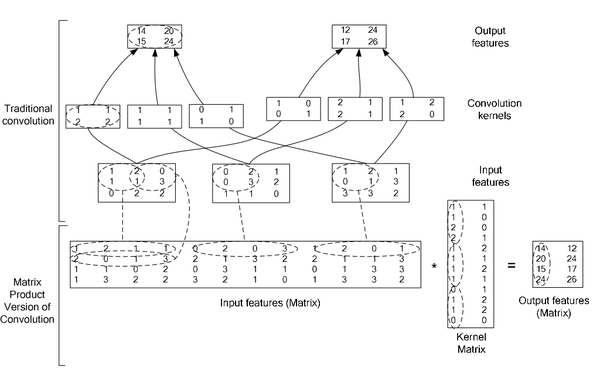
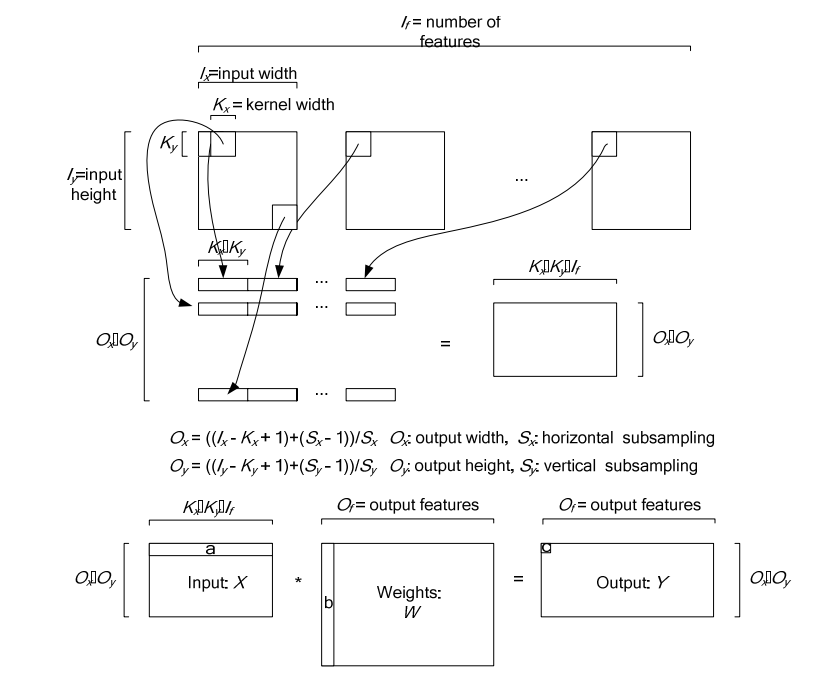
下图是在一个卷积层中将卷积操作展开的具体操作过程,他里面按照卷积核的大小取数据然后展开,在同一张图里的不同卷积核选取的逐行摆放,不同N的话,就在同一行后面继续拼接,不同个可以是多个通道,但是需要注意的是同一行里面每一段都应该对应的是原图中中一个位置的卷积窗口。
对于卷积层中的卷积操作,还有一个group的概念要说明一下,groups是代表filter 组的个数。引入gruop主要是为了选择性的连接卷基层的输入端和输出端的channels,否则参数会太多。每一个group 和1/ group的input 通道和 1/group 的output通道进行卷积操作。比如有4个input, 8个output,那么1-4属于第一组,5-8属于第二个gruop
ConvolutionLayer里面,主要重写了Forward_cpu和Backward_cpu
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* weight = this->blobs_[0]->cpu_data();
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* top_data = top[i]->mutable_cpu_data();
for (int n = 0; n < this->num_; ++n) {
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_);
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
}
可以看到其实这里面他调用了forward_cpu_gemm,而这个函数内部又调用了math_function里面的caffe_cpu_gemm的通用矩阵相乘接口,GEMM的全称是General Matrix Matrix Multiply。其基本形式如下:
\]
template <typename Dtype>
void ConvolutionLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
//反向传播梯度误差
const Dtype* weight = this->blobs_[0]->cpu_data();
Dtype* weight_diff = this->blobs_[0]->mutable_cpu_diff();
for (int i = 0; i < top.size(); ++i) {
const Dtype* top_diff = top[i]->cpu_diff();
const Dtype* bottom_data = bottom[i]->cpu_data();
Dtype* bottom_diff = bottom[i]->mutable_cpu_diff();
//如果有bias项,计算Bias导数
if (this->bias_term_ && this->param_propagate_down_[1]) {
Dtype* bias_diff = this->blobs_[1]->mutable_cpu_diff();
for (int n = 0; n < this->num_; ++n) {
this->backward_cpu_bias(bias_diff, top_diff + n * this->top_dim_);
}
}
//计算weight
if (this->param_propagate_down_[0] || propagate_down[i]) {
for (int n = 0; n < this->num_; ++n) {
// 计算weights权重的梯度
if (this->param_propagate_down_[0]) {
this->weight_cpu_gemm(bottom_data + n * this->bottom_dim_,
top_diff + n * this->top_dim_, weight_diff);
}
//计算botttom数据的梯度,下后传递
if (propagate_down[i]) {
this->backward_cpu_gemm(top_diff + n * this->top_dim_, weight,
bottom_diff + n * this->bottom_dim_);
}
}
}
}
}
Caffe源码解析5:Conv_Layer的更多相关文章
- Caffe源码解析7:Pooling_Layer
转载请注明出处,楼燚(yì)航的blog,http://home.cnblogs.com/louyihang-loves-baiyan/ Pooling 层一般在网络中是跟在Conv卷积层之后,做采样 ...
- Caffe源码解析6:Neuron_Layer
转载请注明出处,楼燚(yì)航的blog,http://home.cnblogs.com/louyihang-loves-baiyan/ NeuronLayer,顾名思义这里就是神经元,激活函数的相应 ...
- Caffe源码解析4: Data_layer
转载请注明出处,楼燚(yì)航的blog,http://home.cnblogs.com/louyihang-loves-baiyan/ data_layer应该是网络的最底层,主要是将数据送给blo ...
- Caffe源码解析3:Layer
转载请注明出处,楼燚(yì)航的blog,http://home.cnblogs.com/louyihang-loves-baiyan/ layer这个类可以说是里面最终的一个基本类了,深度网络呢就是 ...
- Caffe源码解析2:SycedMem
转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang loves baiyan/ 看到SyncedMem就知道,这是在做内存同步的操作.这类个类的 ...
- Caffe源码解析1:Blob
转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ 首先看到的是Blob这个类,Blob是作为Caffe中数据流通的 ...
- caffe源码解析
http://blog.csdn.net/lanxuecc/article/details/53186613
- caffe源码阅读
参考网址:https://www.cnblogs.com/louyihang-loves-baiyan/p/5149628.html 1.caffe代码层次熟悉blob,layer,net,solve ...
- 【Caffe】源码解析----caffe.proto (转载)
分析caffe源码,看首先看caffe.proto,是明智的选择.好吧,我不是创造者,只是搬运工. 原文地址:http://blog.csdn.net/qq_16055159/article/deta ...
随机推荐
- 谁在关心toString的性能?
谁在关心toString的性能?没有人!除非当你有大量的数据在批量处理,使用toString产生了许多日志.然后,你去调查为何如此之慢,才意识到大部分的toString方法使用的是introspect ...
- SSRF安全威胁在JAVA代码中的应用
如上图所示代码,在进行外部url调用的时候,引入了SSRF检测:ssrfChecker.checkUrlWithoutConnection(url)机制. SSRF安全威胁: 很多web应用都提供 ...
- 【JAVA并发编程实战】3、同步容器
同步容器包括Vector和Hashtable,还有一些由Collections.synchronizedXxx等工厂方法创建的 1.同步容器类的问题 同步容器类都是线程安全的,但是有些时候还是要客户端 ...
- android.view.InflateException: Binary XML file line #34: Error inflating class
问题一般出在xml的第三方View的全类名,你可能是直接粘贴过来的,没有改成自己项目的全类名.
- EasyUI弹出窗口实例
效果体验:http://hovertree.com/texiao/jeasyui/1.htm 源代码下载:HovertreeJEasyUI HTML文件代码: <!DOCTYPE html> ...
- web前端交互性易用性说明
总结一下我们在web前端开发过程中总是强调交互性.易用性的情况分析说明.个人觉得web前端的易用交互也就是我们所说人性化操作.不外乎希望达到的效果为:界面风格简洁明了.重点突出:操作简单,直观可见.当 ...
- Android—自定义控件实现ListView下拉刷新
这篇博客为大家介绍一个android常见的功能——ListView下拉刷新(参考自他人博客,网址忘记了,阅读他的代码自己理解注释的,希望能帮助到大家): 首先下拉未松手时候手机显示这样的界面: 下面的 ...
- android中的回调请求的个人理解
Fragment类提供了管理"选项菜单"的回调函数onCreateOptionMenu(Menu,MenuInflater),调用它可以--创建"选项菜单". ...
- iOS 获取用户授权的用户隐私保护-地图定位
获取用户授权的用户隐私保护地图定位示例://导入定位框架#import<CoreLocation/CoreLocation.h>@interfaceViewController()< ...
- iOS 直播-闪光灯的使用
iOS 直播-闪光灯的使用 应用场景是这样的,最近公司决定做一款直播类的软件. 在开发中就遇到了不曾使用过的硬件功能-闪光灯. 这篇博客将简单介绍一下闪光灯的使用. // // ViewControl ...