Spark Straming,Spark Streaming与Storm的对比分析
Spark Straming,Spark Streaming与Storm的对比分析
一、大数据实时计算介绍
Spark Streaming,其实就是Spark提供的,对于大数据,进行实时计算的一种框架。
它的底层,就是基于Spark Core的。
基本的计算模型,还是基于内存的大数据实时计算模型,而且,它的底层的组件,其实还是最核心的RDD。
只不过,针对实时计算的特点,在RDD之上,进行了一层封装,叫做DStream。
二、大数据实时计算原理

三、Spark Streaming简介
Spark Streaming是Spark Core API的一种扩展,它可以用于进行大规模、高吞吐量、容错的实时数据的处理。
支持从很多种数据源中读取数据,比如kafka、Flume、Twitter、ZeroMQ、Kinesis或者TCP Socket。
能够使用类似高阶函数的复杂算法来进行数据处理,比如map、reduce、join和window。
处理后的数据可以被保存到文件系统、数据库、Dashboard等存储中。

3.1 SparkStreaming初始理解
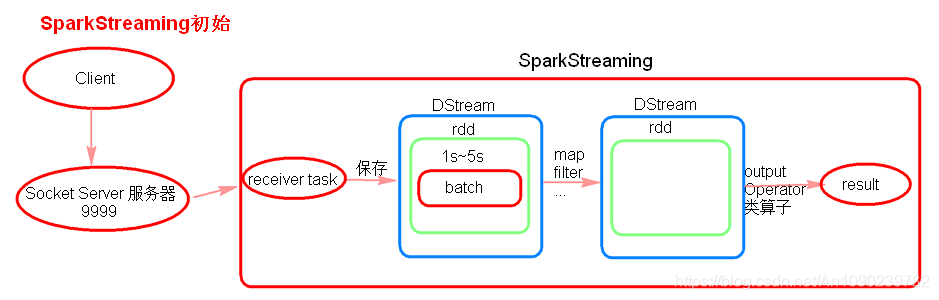
receiver task是7*24小时一直在执行,一直接受数据,将一段时间内接收来的数据保存到batch中。假设batchInterval为5s,那么会将接收来的数据每隔5秒封装到一个batch中,batch没有分布式计算特性,这一个batch的数据又被封装到一个RDD中,RDD最终封装到一个DStream中。
例如:假设batchInterval为5秒,每隔5秒通过SparkStreaming将得到一个DStream,在第6秒的时候计算这5秒的数据,假设执行任务的时间是3秒,那么第69秒一边在接收数据,一边在计算任务,910秒只是在接收数据。然后在第11秒的时候重复上面的操作。
如果job执行的时间大于batchInterval会有什么样的问题?
如果接受过来的数据设置的级别是仅内存,接收来的数据会越堆积越多,最后可能会导致OOM(如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至disk, 加大延迟 )。
3.2 2.SparkStreaming代码
启动socket server 服务器:nc –lk 9999
receiver模式下接受数据,local的模拟线程必须大于等于2,一个线程用来receiver用来接受数据,另一个线程用来执行job。
Durations时间设置就是我们能接收的延迟度。这个需要根据集群的资源情况以及任务的执行情况来调节。
创建JavaStreamingContext有两种方式(SparkConf,SparkContext)。
所有的代码逻辑完成后要有一个output operation类算子。
JavaStreamingContext.start() Streaming框架启动后不能再次添加业务逻辑。
JavaStreamingContext.stop() 无参的stop方法将SparkContext一同关闭,stop(false),不会关闭SparkContext。
JavaStreamingContext.stop()停止之后不能再调用start。
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("WordCountOnline");
/**
* 在创建streaminContext的时候 设置batch Interval
*/
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5));
JavaReceiverInputDStream<String> lines = jsc.socketTextStream("node5", 9999);
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) {
return Arrays.asList(s.split(" "));
}
});
JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairDStream<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
//outputoperator类的算子
counts.print();
jsc.start();
//等待spark程序被终止
jsc.awaitTermination();
jsc.stop(false);
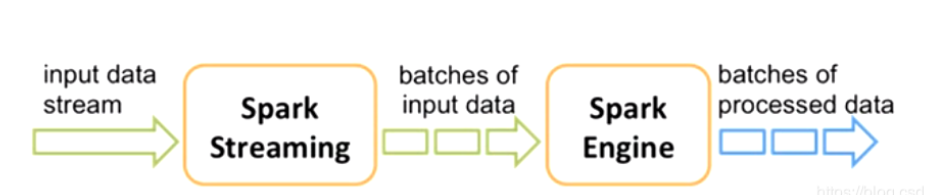
四、Spark Streaming基本工作原理
接收实时输入数据流,然后将数据拆分成多个batch。
比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark的计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch组成的。
五、DStream
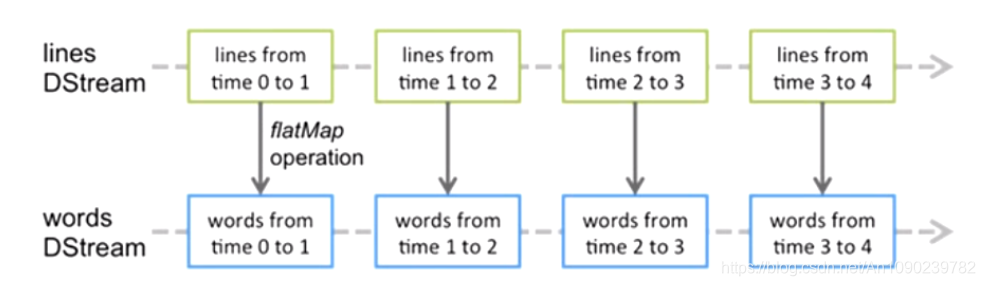
Spark Streaming提供了一种高级的抽象,叫做DStream,译为“离散流”,它代表了一个持续不断的数据流。
DStream可以通过输入数据源来创建,比如Kafka、Flume和Kinesis,也可通过其他DStream应用高阶函数来创建,比如map、reduce、join、window。
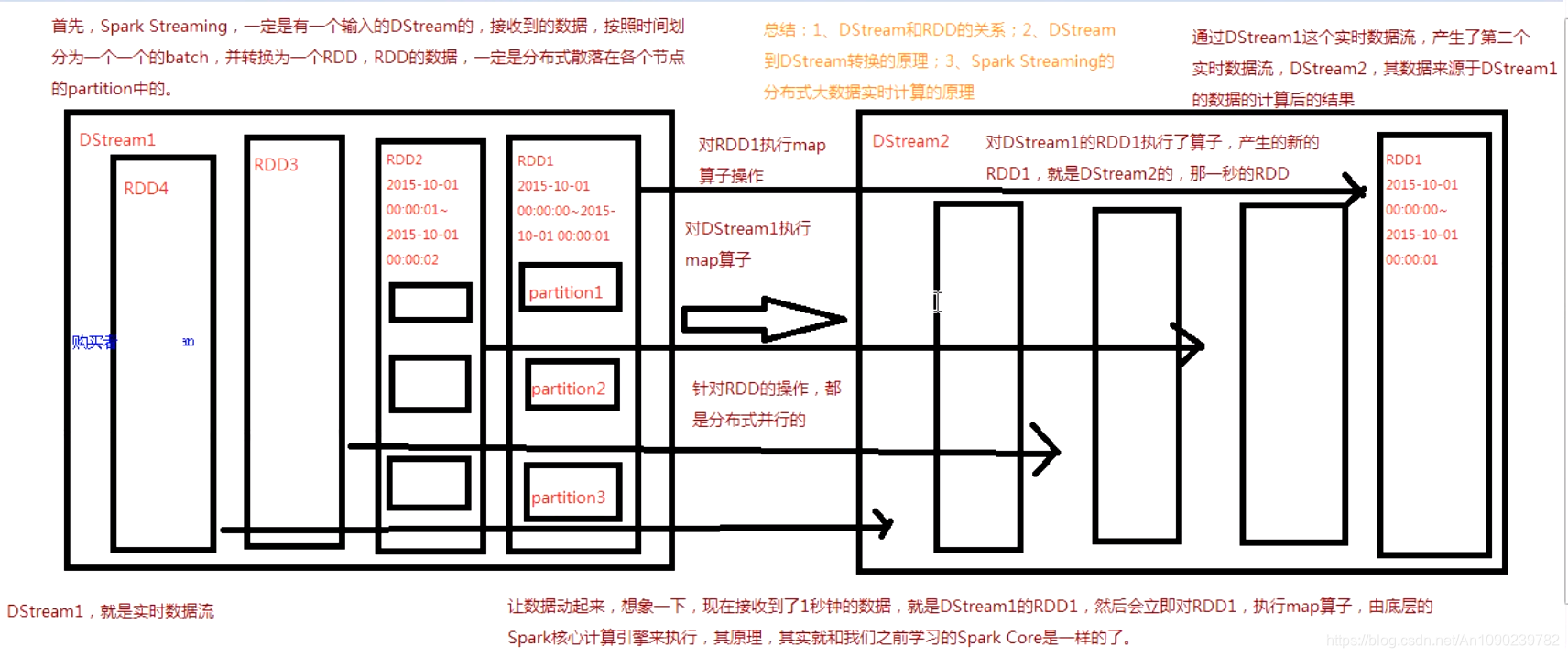
DSteam的内部,其实一系列不断产生的RDD。
RDD是Spark Core的核心抽象,即不可变的,分布式的数据集。
DStream中的每个RDD都包含了一个时间段内的数据。

对DStream应用的算子,比如map,其实在底层会被翻译为对DSteam中每个RDD的操作。
比如对一个DStream执行一个map擦欧洲哦,会产生一个新的DStream。
但是,在底层,其实对输入DStream中每个时间段的一个RDD,都应用一遍Map操作,然后生成新的RDD,即作为新的DStream中的那个时间段的RDD。
底层的RDD的transformation操作,其实,还是由Spark Core的计算引擎来实现的。
Spark Streaming对Spark Core进行了一层封装,隐藏了细节,然后对开发人员提供了方便易用的高层次的API。
六、Spark Streaming与Storm的对比分析
6.1 与Storm的对比
| 对比点 | Storm | Spark Streaming |
|---|---|---|
| 实时计算模型 | 纯实时,来一条数据,处理一条数据 | 准实时,对应事件段内数据收集起来,作为一个RDD再处理 |
| 实时计算延迟度 | 毫秒级 | 秒级 |
| 吞吐量 | 低 | 高 |
| 事务机制 | 支持完善 | 支持,但不够完善 |
| 健壮性/容错性 | Zookeeper,Acker,非常强 | Checkpoint,WAL,一般 |
| 动态调整并行度 | 支持 | 不支持 |
6.2 Spark Streaming与Storm的优劣分析
二者在实时计算领域中,都很优秀,只是擅长的细分场景并不相同。
Spark Streaming仅仅在吞吐量上比Storm更优秀。
Storm在实时延迟度上,比Spark Streaming好多了。而且,Storm的事务机制、健壮性/容错性、动态调整并行度等特性,都要比Spark Streaming更优秀。
Spark Streaming,是Storm无法比的,就是它位于Spark生态技术栈中,因此,其可以和Spark Core、Spark SQL无缝整合,也就意味着,我们可以对实时处理出来的中间数据立即在程序中无缝进行延迟批处理、交互式查询等操作。
Spark Straming,Spark Streaming与Storm的对比分析的更多相关文章
- Spark Streaming与Storm的对比及使用场景
Spark Streaming与Storm都可以做实时计算,那么在做技术选型的时候到底应该选择哪个呢?通过下图可以从计算模型.计算延迟.吞吐量.事物.容错性.动态并行度等方方面进行对比. 对比点 ...
- spark streaming 与 storm的对比
feature strom (trident) spark streaming 说明 并行框架 基于DAG的任务并行计算引擎(task parallel continuous computati ...
- Spark Streaming与Storm的对比
- 【Streaming】Storm内部通信机制分析
一.任务执行及通信的单元 Storm中关于任务执行及通信的三个概念:Worker(进程).Executor(线程)和Task(Spout.Bolt) 1. 一个worker进程执行的是一个Topol ...
- spark与storm的对比
对比点 Storm Spark Streaming 实时计算模型 纯实时,来一条数据,处理一条数据 准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理 实时计算延迟度 毫秒级 秒级 吞吐量 ...
- Spark记录-spark与storm比对与选型(转载)
大数据实时处理平台市场上产品众多,本文着重讨论spark与storm的比对,最后结合适用场景进行选型. 一.spark与storm的比较 比较点 Storm Spark Streaming 实时计算模 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(一)
本文由 网易云发布. 1.Flink架构及特性分析 Flink是个相当早的项目,开始于2008年,但只在最近才得到注意.Flink是原生的流处理系统,提供high level的API.Flink也提 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(二)
本文由 网易云发布. 本文内容接上一篇Apache 流框架 Flink,Spark Streaming,Storm对比分析(一) 2.Spark Streaming架构及特性分析 2.1 基本架构 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(2)
此文已由作者岳猛授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 2.Spark Streaming架构及特性分析 2.1 基本架构 基于是spark core的spark s ...
随机推荐
- java零基础之--JDK安装篇
---恢复内容开始--- 很多零基础学习者在开始学习java中很难理解JDK的安装和配置,以下是基于Windows 7 的安装配置流程(Windows 10类似) 1. 在安装之前我们先了解几个名词: ...
- J.U.C关于Execute实现
JAVASE5的Execute将为你管理Thread对象,是启动任务的优选方案 /***newCachedThreadPool在程序的执行过程中通常会创建于所需任务相同数量的线程即可以达到Intege ...
- Sqoop(一)安装及基本使用
Sqoop: 1.sqoop从数据库中导入数据到HDFS 2.SQOOP从数据库导入数据到hive 3.sqoop从hive中将数据导出到数据库 sqoop底层还是执行的m ...
- Spark算子使用
一.spark的算子分类 转换算子和行动算子 转换算子:在使用的时候,spark是不会真正执行,直到需要行动算子之后才会执行.在spark中每一个算子在计算之后就会产生一个新的RDD. 二.在编写sp ...
- WPF 关于拖拽打开文件的注意事项
由于开发需求,需要开发一个类似Win图片浏览的工具 当然也涉及到了拖拽打开的需求 按照固有思路: <Grid x:Name="grid1" AllowDrop="T ...
- 【C++】《Effective C++》第三章
第三章 资源管理 条款13:以对象管理资源 当申请一块动态内存时,可能会发生内存泄漏. class Investment {}; void f() { Investment* pInv = creat ...
- LeetCode703 流中第k大的元素
前言: 我们已经介绍了二叉搜索树的相关特性,以及如何在二叉搜索树中实现一些基本操作,比如搜索.插入和删除.熟悉了这些基本概念之后,相信你已经能够成功运用它们来解决二叉搜索树问题. 二叉搜索树的有优点是 ...
- 使用OpenCV进行简单的人像分割与合成
图像合成 实现思路 通过背景建模的方法,对源图像中的动态人物前景进行分割,再将目标图像作为背景,进行合成操作,获得一个可用的合成影像. 实现步骤如下. 使用BackgroundSubtractorMO ...
- 阿里云OSS整合
一.对象存储OSS 为了解决海量数据存储与弹性扩容(主要是静态文件的存储例如图片,语音,视频等),项目中我们通常采用云存储的解决方案- 阿里云OSS. 1.开通"对象存储OSS"服 ...
- kubernets之计算资源
一 为pod分配cpu,内存以及其他的资源 1.1 创建一个pod,同时为这个pod分配内存以及cpu的资源请求量 apiVersion: v1 kind: Pod metadata: name: ...