influxdb集群部署
环境准备
influxdb enterprise运行条件最低需要三个meta nodes节点以及两个data nodes
Meta nodes之间使用TCP和Raft一致性协议通信,默认端口为8089
Meta nodes对外暴露8091,用于influxd-ctl命令进行交互
Data nodes通过8088进行数据同步,8086对于用户进行读写服务
在集群中,所有meta nodes节点必须要与data nodes节点保持通信。

mata nodes主要保存以下所有的元数据信息
- 集群中所有的节点以及角色
- 集群中所有存在的数据库和保留策略(retention policy)
- 保存所有分片和分片组信息
- 保存集群用户权限
data node保存所有原始时序数据以及元数据,包括
- measurement(数据表)
- tag key和value
- field key和value;

#wget https://dl.influxdata.com/enterprise/releases/influxdb-meta_1.7.8-c1.7.8_amd64.deb
# dpkg -i influxdb-meta_1.7.8-c1.7.8_amd64.deb
influxdb-meda01
# egrep -v "#|^$" /etc/influxdb/influxdb-meta.conf
hostname = "enterprise-meta-01"
[enterprise]
license-key = "224bca5e-514d-441e-b2c2-31b29dd79811"
[meta]
dir = "/var/lib/influxdb/meta"
internal-shared-secret = "123.com"
influxdb-meda02
# egrep -v "#|^$" /etc/influxdb/influxdb-meta.conf
hostname = "enterprise-meta-02"
[enterprise]
license-key = "224bca5e-514d-441e-b2c2-31b29dd79811"
[meta]
dir = "/var/lib/influxdb/meta"
internal-shared-secret = "123.com"
influxdb-meda03
# egrep -v "#|^$" /etc/influxdb/influxdb-meta.conf
hostname = "enterprise-meta-03"
[enterprise]
license-key = "224bca5e-514d-441e-b2c2-31b29dd79811"
[meta]
dir = "/var/lib/influxdb/meta"
internal-shared-secret = "123.com"
# systemctl start influxdb-meta
# systemctl enable influxdb-meta
将meta node节点加入集群
#influxd-ctl add-meta enterprise-meta-02:8091
#influxd-ctl add-meta enterprise-meta-03:8091
【部署influxdb-node节点】
#wget https://dl.influxdata.com/enterprise/releases/influxdb-data-1.8.2_c1.8.2.x86_64.rpm
#dpkg -i influxdb-data_1.8.2-c1.8.2_amd64.deb
#egrep -v "#|^$" /etc/influxdb/influxdb.conf
bind-address = "192.168.60.0:8088"
hostname = "enterprise-data-01"
[enterprise]
license-key = "224bca5e-514d-441e-b2c2-31b29dd79811"
[meta]
dir = "/var/lib/influxdb/meta"
meta-internal-shared-secret = "123.com"
[data]
dir = "/var/lib/influxdb/data"
wal-dir = "/var/lib/influxdb/wal"
cache-max-memory-size = "1g"
cache-snapshot-memory-size = "25m"
cache-snapshot-write-cold-duration = "10m"
max-series-per-database = 0
max-values-per-tag = 0
max-index-log-file-size = "128k"
[cluster]
[hinted-handoff]
dir = "/var/lib/influxdb/hh"
[anti-entropy]
[retention]
[shard-precreation]
[monitor]
store-enabled = false
[http]
log-enabled = true [logging]
[subscriber]
[[graphite]]
[[collectd]]
[[opentsdb]]
[[udp]]
[continuous_queries]
[tls]
# egrep -v "#|^$" /etc/influxdb/influxdb.conf
bind-address = "192.168.60.0:8088"
hostname = "enterprise-data-02"
[enterprise]
license-key = "224bca5e-514d-441e-b2c2-31b29dd79811"
[meta]
dir = "/var/lib/influxdb/meta"
meta-internal-shared-secret = "123.com"
[data]
dir = "/var/lib/influxdb/data"
wal-dir = "/var/lib/influxdb/wal"
cache-max-memory-size = "1g"
cache-snapshot-memory-size = "25m"
cache-snapshot-write-cold-duration = "10m"
max-series-per-database = 0
max-values-per-tag = 0
max-index-log-file-size = "128k"
[cluster]
[hinted-handoff]
dir = "/var/lib/influxdb/hh"
[anti-entropy]
[retention]
[shard-precreation]
[monitor]
store-enabled = true
[http] [logging]
[subscriber]
[[graphite]]
[[collectd]]
[[opentsdb]]
[[udp]]
[continuous_queries]
log-enabled = true
[tls]
#systemctl start influxd
#systemctl enable influxd
#将date node加入集群
#influxd-ctl add-data enterprise-data-01:8088
#influxd-ctl add-data enterprise-data-02:8088
最后我们在influxdb-meta节点上执行 influxd-ctl show查看集群节点状态
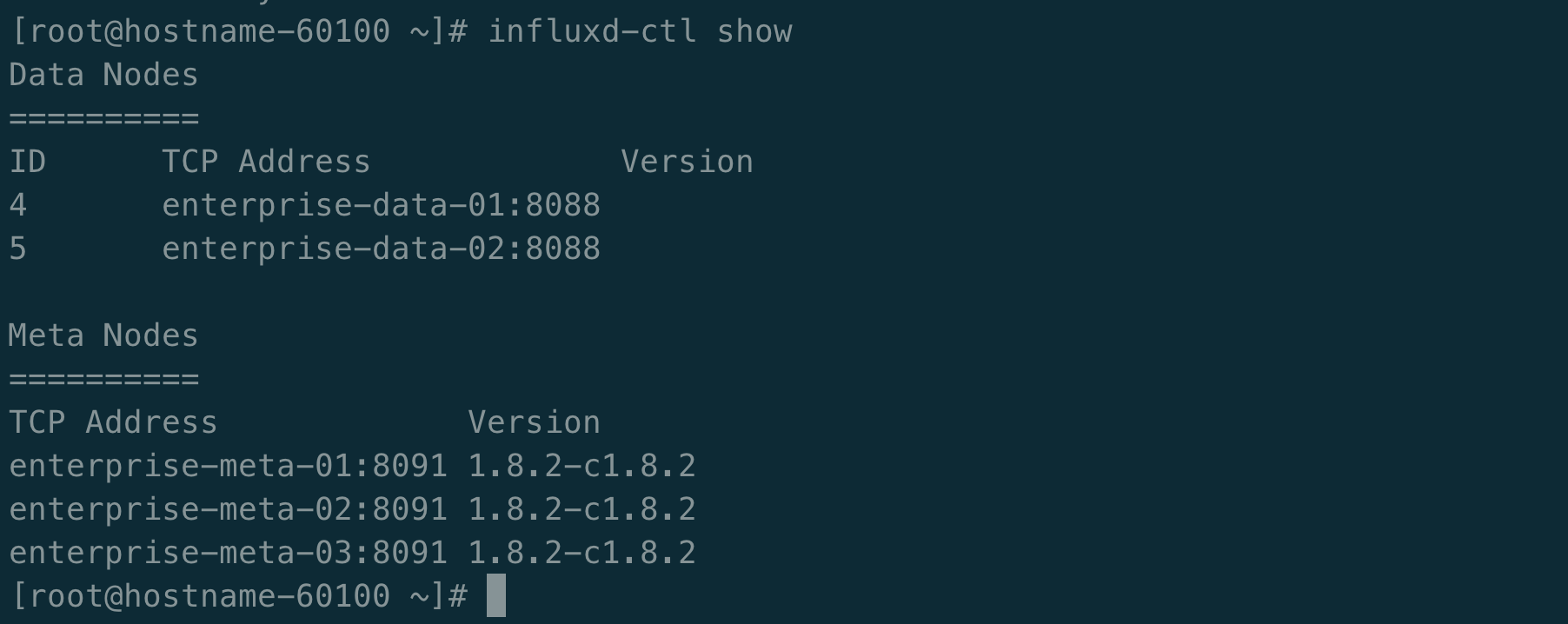
截止目前influxdb集群部署完毕!END
influxdb集群部署的更多相关文章
- Kubernetes集群部署关键知识总结
Kubernetes集群部署需要安装的组件东西很多,过程复杂,对服务器环境要求很苛刻,最好是能连外网的环境下安装,有些组件还需要连google服务器下载,这一点一般很难满足,因此最好是能提前下载好准备 ...
- Kubernetes(k8s)集群部署(k8s企业级Docker容器集群管理)系列目录
0.目录 整体架构目录:ASP.NET Core分布式项目实战-目录 k8s架构目录:Kubernetes(k8s)集群部署(k8s企业级Docker容器集群管理)系列目录 一.感谢 在此感谢.net ...
- linux运维、架构之路-Kubernetes离线集群部署-无坑
一.部署环境介绍 1.服务器规划 系统 IP地址 主机名 CPU 内存 CentOS 7.5 192.168.56.11 k8s-node1 2C 2G CentOS 7.5 192.168.56 ...
- k8s集群部署(2)
一.利用ansible部署kubernetes准备阶段 1.集群介绍 基于二进制方式部署k8s集群和利用ansible-playbook实现自动化:二进制方式部署有助于理解系统各组件的交互原理和熟悉组 ...
- Quartz.net持久化与集群部署开发详解
序言 我前边有几篇文章有介绍过quartz的基本使用语法与类库.但是他的执行计划都是被写在本地的xml文件中.无法做集群部署,我让它看起来脆弱不堪,那是我的罪过. 但是quart.net是经过许多大项 ...
- Openfire 集群部署和负载均衡方案
Openfire 集群部署和负载均衡方案 一. 概述 Openfire是在即时通讯中广泛使用的XMPP协议通讯服务器,本方案采用Openfire的Hazelcast插件进行集群部署,采用Hapro ...
- 基于Tomcat的Solr3.5集群部署
基于Tomcat的Solr3.5集群部署 一.准备工作 1.1 保证SOLR库文件版本相同 保证SOLR的lib文件版本,slf4j-log4j12-1.6.1.jar slf4j-jdk14-1.6 ...
- jstorm集群部署
jstorm集群部署下载 Install JStorm Take jstorm-0.9.6.zip as an example unzip jstorm-0.9.6.1.zip vi ~/.bashr ...
- CAS 集群部署session共享配置
背景 前段时间,项目计划搞独立的登录鉴权中心,由于单独开发一套稳定的登录.鉴权代码,工作量大,最终的方案是对开源鉴权中心CAS(Central Authentication Service)作适配修改 ...
随机推荐
- 解决IDEA打包出现中文乱码的问题
这主要是maven编译时编码问题导致的. 解决办法: 1.在IDEA的File里面打开Settings. 2.找到Runner,在VM Options输入-DarchetypeCatalog=inte ...
- mariadb 4
连接查询,视图,事物,索引,外键(第四章) 连接查询 --创建学生表 create table students ( id int unsigned not null auto_increment ...
- hystrix熔断器之配置
HystrixCommandProperties命令执行相关配置: hystrix.command.[commandkey].execution.isolation.strategy 隔离策略THRE ...
- maven安装配置以及eclipse的配置
一.需要准备的东西 JDK Eclipse Maven程序包 二.下载与安装 前往https://maven.apache.org/download.cgi下载最新版的Maven程序: 将文件解压到D ...
- python爬取酷狗音乐
url:https://www.kugou.com/yy/html/rank.html 我们随便访问一个歌曲可以看到url有个hash https://www.kugou.com/song/#hash ...
- Unity 自己使用顶点描绘圆形UI图片
2020-09-10 在游戏的UI中,圆形图片的需求是很高的,但是,在Unity中想要实现圆形UI,一般的做法是是使用圆形Mask(遮罩),但是使用Mask的缺点很明显,主要有三点: 1.比较麻烦,使 ...
- kubernetes的思考
初识k8s kubernetes,从接触到今年6月接触到现在有3个月了,严格来说是断断续续的接触,没有一直持续学习.在未接触之前,这个技术对我来说,有点像传说,运维同行对此评价普遍是比较难懂,概念庞大 ...
- 从CPU缓存看缓存的套路
一.前言 不同存储技术的访问时间差异很大,从 计算机层次结构 可知,通常情况下,从高层往底层走,存储设备变得更慢.更便宜同时体积也会更大,CPU 和内存之间的速度存在着巨大的差异,此时就会想到计算机科 ...
- 虚拟机CentOS开机黑屏解决方案
默认配置 错误: 1.直接就是黑屏,连杠杠都没有 2.centos系统关不掉 3.关闭vmware提示:虚拟机XXX繁忙 解决方案一: 1.以管理员身份运行cmd控制台程序 2.在cmd窗口中输入ne ...
- ZooKeeper-3.5.6分布式锁
原理 基本方案是基于ZooKeeper的临时节点与和watch机制.当要获取锁时在某个目录下创建一个临时节点,创建成功则表示获取锁成功,创建失败则表示获取锁失败,此时watch该临时节点,当该临时节点 ...