python爬取酷狗音乐
我们随便访问一个歌曲可以看到url有个hash
https://www.kugou.com/song/#hash=AC9D859362CABB2092AEAA39A072606A&album_id=39211957
但是这个hash是可以得到的

import re
import requests
import json
headers = {
'cookie': 'kg_mid=7a7f50715e7cbc43187cb14650a074d7; ACK_SERVER_10015=%7B%22list%22%3A%5B%5B%22gzlogin-user.kugou.com%22%5D%5D%7D; ACK_SERVER_10016=%7B%22list%22%3A%5B%5B%22gzreg-user.kugou.com%22%5D%5D%7D; ACK_SERVER_10017=%7B%22list%22%3A%5B%5B%22gzverifycode.service.kugou.com%22%5D%5D%7D; kg_dfid=2lP8Vp1RHLHj0wmucn0XlXFL; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1600062203; kg_mid_temp=7a7f50715e7cbc43187cb14650a074d7; KuGooRandom=66401600062231494; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1600062409',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
hash_com = re.compile('"Hash":"(.*?)"',re.I|re.S)
html = requests.get('https://www.kugou.com/yy/html/rank.html',headers=headers)
hash_result = hash_com.findall(html.text)
print(hash_result)
然后我们刷新歌曲这里得网页可以看到都是在这里
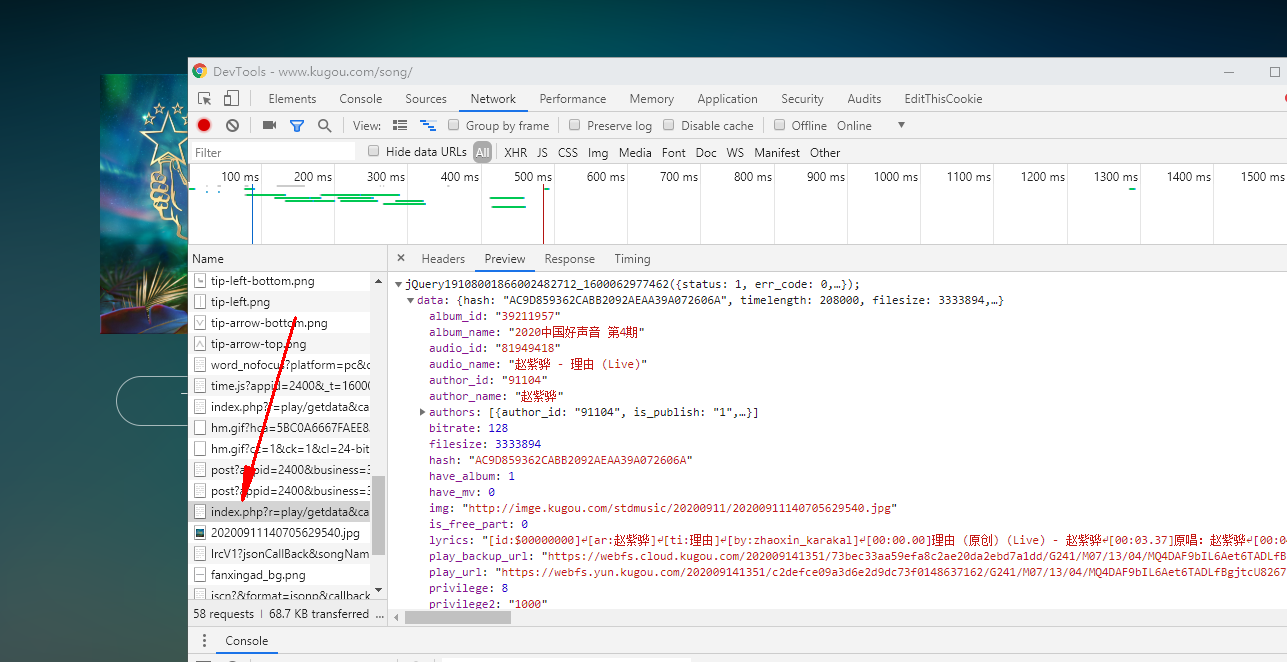
然后我敲门只留hash前面看看能不能访问
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19108001866002482712_1600062977462&hash=AC9D859362CABB2092AEAA39A072606A
访问是可以的
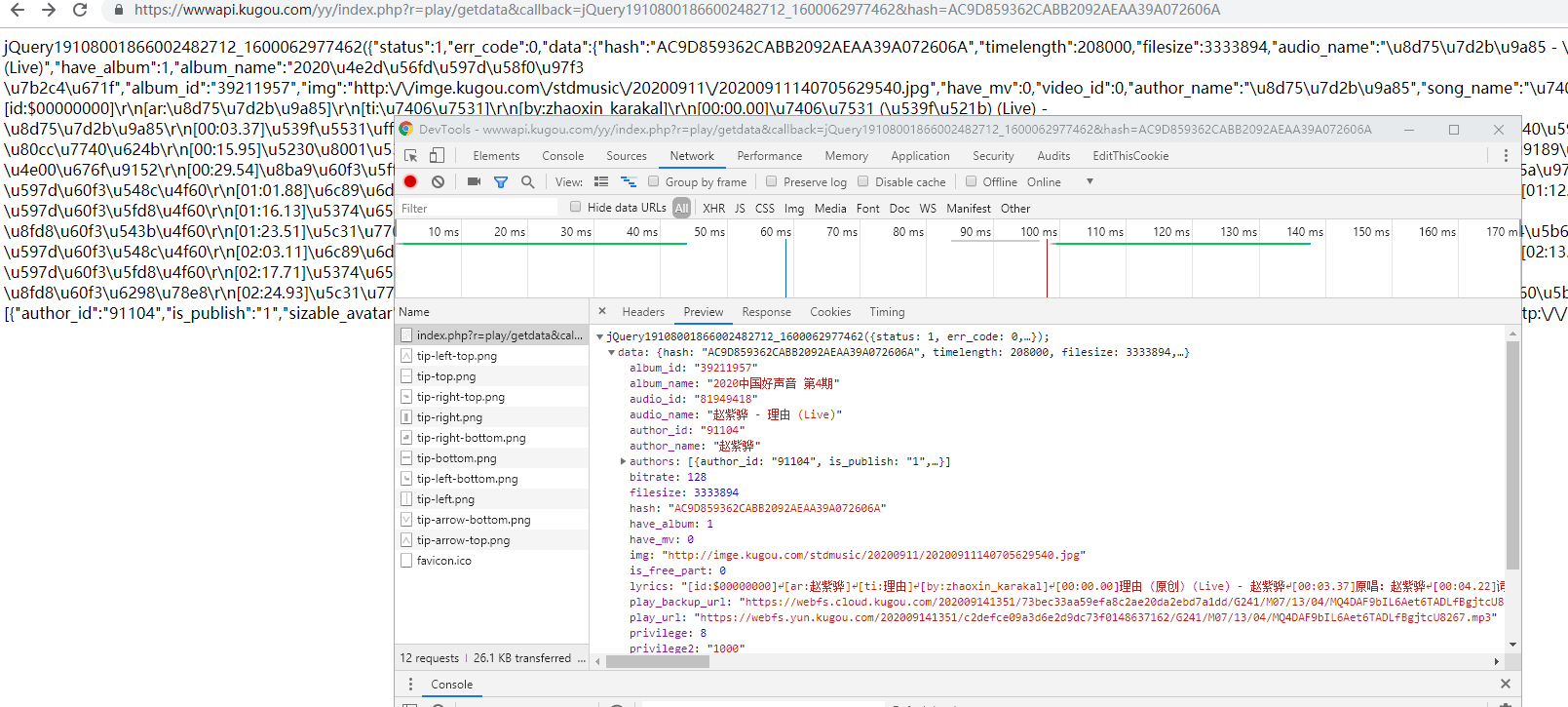
然后我们再拼接一下
import re
import requests
import json
headers = {
'cookie': 'kg_mid=7a7f50715e7cbc43187cb14650a074d7; ACK_SERVER_10015=%7B%22list%22%3A%5B%5B%22gzlogin-user.kugou.com%22%5D%5D%7D; ACK_SERVER_10016=%7B%22list%22%3A%5B%5B%22gzreg-user.kugou.com%22%5D%5D%7D; ACK_SERVER_10017=%7B%22list%22%3A%5B%5B%22gzverifycode.service.kugou.com%22%5D%5D%7D; kg_dfid=2lP8Vp1RHLHj0wmucn0XlXFL; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1600062203; kg_mid_temp=7a7f50715e7cbc43187cb14650a074d7; KuGooRandom=66401600062231494; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1600062409',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
hash_com = re.compile('"Hash":"(.*?)"',re.I|re.S)
html = requests.get('https://www.kugou.com/yy/html/rank.html',headers=headers)
hash_result = hash_com.findall(html.text)
# print(hash_result)
base_url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19108001866002482712_1600062977462&hash='
for hash in hash_result:
url = base_url+hash
# print(url)
然后再获取url
jsondata = requests.get(url,headers=headers)
print(jsondata.text)
输出为

我们来.json()看看
print(jsondata.json())
但是返回错误了,所以不是一个合法json,来转换一下,通过find来找到合法的json头部和尾部
他的合法开头再这里

结尾就是 .mp3"}}
start = jsondata.text.find('{"status":1')
end = jsondata.text.find('.mp3"}}')+len('.mp3"}}')
print(jsondata.text[start:end])
这里加上len就是因为[]是左闭右合的,返回

全部代码
import re
import requests
import json
import os
headers = {
'cookie': 'kg_mid=7a7f50715e7cbc43187cb14650a074d7; ACK_SERVER_10015=%7B%22list%22%3A%5B%5B%22gzlogin-user.kugou.com%22%5D%5D%7D; ACK_SERVER_10016=%7B%22list%22%3A%5B%5B%22gzreg-user.kugou.com%22%5D%5D%7D; ACK_SERVER_10017=%7B%22list%22%3A%5B%5B%22gzverifycode.service.kugou.com%22%5D%5D%7D; kg_dfid=2lP8Vp1RHLHj0wmucn0XlXFL; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1600062203; kg_mid_temp=7a7f50715e7cbc43187cb14650a074d7; KuGooRandom=66401600062231494; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1600062409',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
hash_com = re.compile('"Hash":"(.*?)"',re.I|re.S)
html = requests.get('https://www.kugou.com/yy/html/rank.html',headers=headers)
hash_result = hash_com.findall(html.text)
# print(hash_result)
base_url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19108001866002482712_1600062977462&hash='
for hash in hash_result:
url = base_url+hash
# print(url)
jsondata = requests.get(url,headers=headers)
start = jsondata.text.find('{"status":1')
end = jsondata.text.find('.mp3"}}')+len('.mp3"}}')
# print(jsondata.text[start:end])
songurl = json.loads(jsondata.text[start:end])['data']['play_url']
title = json.loads(jsondata.text[start:end])['data']['audio_name']
if not os.path.exists('酷狗'):
os.mkdir('酷狗')
with open('酷狗/{}.mp3'.format(title),'wb')as f:
f.write(requests.get(songurl).content)

python爬取酷狗音乐的更多相关文章
- python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- Python爬取酷狗飙升榜前十首(100)首,写入CSV文件
酷狗飙升榜,写入CSV文件 爬取酷狗音乐飙升榜的前十首歌名.歌手.时间,是一个很好的爬取网页内容的例子,对爬虫不熟悉的读者可以根据这个例子熟悉爬虫是如何爬取网页内容的. 需要用到的库:requests ...
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- 使用scrapy 爬取酷狗音乐歌手及歌曲名并存入mongodb中
备注还没来得及写,共爬取八千多的歌手,每名歌手平均三十首歌曲算,大概二十多万首歌曲 run.py #!/usr/bin/env python # -*- coding: utf-8 -*- __aut ...
- 【Python】【爬虫】爬取酷狗音乐网络红歌榜
原理:我的上篇博客 import requests import time from bs4 import BeautifulSoup def get_html(url): ''' 获得 HTML ' ...
- 【Python】【爬虫】爬取酷狗TOP500
好啦好啦,那我们来拉开我们的爬虫之旅吧~~~ 这一只小爬虫是爬取酷狗TOP500的,使用的爬取手法简单粗暴,目的是帮大家初步窥探爬虫长啥样,后期会慢慢变得健壮起来的. 环境配置 在此之前需要下载一个谷 ...
- htmlunit+fastjson抓取酷狗音乐 qq音乐链接及下载
上次学了jsoup之后,发现一些动态生成的网页内容是无法抓取的,于是又学习了htmlunit,下面是抓取酷狗音乐与qq音乐链接的例子: 酷狗音乐: import java.io.BufferedInp ...
- 使用Xpath爬取酷狗TOP500的歌曲信息
使用xpath爬取酷狗TOP500的歌曲信息, 将排名.歌手名.歌曲名.歌曲时长,提取的结果以文件形式保存下来.参考网址:http://www.kugou.com/yy/rank/home/1-888 ...
随机推荐
- linux命令--大小写转换命令
1.tr命令 tr命令转换小写为大写 cat aa.txt | tr a-z A-Z 或者 cat aa.txt | tr [:lower:] [:upper:] tr命令大写转换小写 ...
- JavaScript学习系列博客_13_JavaScript中的对象(Object)简介
对象 对象属于一种复合的数据类型,在对象中可以保存多个不同数据类型的属性.除了那5种基本数据类型,就是对象. 分类:1.内建对象- 由ES标准中定义的对象,在任何的ES的实现中都可以使用- 比如:Ma ...
- 9.oracle表查询关键字
1.使用逻辑操作符号问题:查询工资高于500或者是岗位为manager的雇员,同时还要满足他们的姓名首字母为大写的J? select * from emp where (sal > 500 or ...
- 在laravel中遇到并发的解决方案
1,在mysql中创建唯一索引,在代码中try catch mysql的1062错误 2.将存在并发的代码丢给队列异步处理.这种解决方案的问题是,接下来的代码不能依赖队列的处理结果 3.使用mysql ...
- Java中实现对集合中对象按中文首字母排序
有一个person对象如下: public class Person { private String id;private String nam; } 一个list集合如下: List<Emp ...
- Shell编程—控制脚本
1处理信号 1.1信号表 编号 信号名称 缺省操作 解释 1 SIGHUP Terminate 挂起控制终端或进程 2 SIGINT Terminate 来自键盘的中断 3 SIGQUIT Dump ...
- YOLO v3算法介绍
图片来自https://towardsdatascience.com/yolo-v3-object-detection-with-keras-461d2cfccef6 数据前处理 输入的图片维数:(4 ...
- 在使用postman中操作api接口测试403解决方法
在向Jenkins发送请求时收到了这样的403错误信息: No valid crumb was included in the request 后来通过google找到了解决方案. http://st ...
- 使用intellij IDEA远程连接服务器部署项目
由于不想每次打开上传的文件软件,故研究使用intellij IDEA集成 ,下面是我使用的过程的一些记录. 使用intellij 远程连接服务器连接Linux服务器部署项目,方便我们开发测试. 本人使 ...
- laravel发送邮件配置
1.设置发送方,即邮件服务器,可以使用163邮箱,设置smtp,开启后获取授权码 2.在env文件配置 MAIL_DRIVER=smtpMAIL_HOST=smtp.163.com //邮箱服务器M ...