大数据: 完全分布式Hadoop集群-HBase安装
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库。它是面向列的,并适合于存储超大型松散数据。HBase适合于实时,随机对Big数据进行读写操作的业务环境。
本文基本环境:
Centos 7 Linux Master 3.10.0-229.el7.x86_64
Hadoop-2.7.1 完全分布式 3台机
Hbase-1.1.2 HBase官网下载 hbase-1.1.2-bin.tar.gz
三台虚拟机主机名:
Master 分配2G内存 namenode
Slaver1 分配1G内存 datanode
Slaver2 分配1G内存 datanode
进行软件部署
1. 使用 root 用户将 hbase-1.1.2-bin.tar.gz 包解压并放在 /home/app 下,给予 hadoop 用户权限 。
tar –xvzf hbase-1.1.2-bin.tar.gz
chown –R hadoop:hadoop hbase-1.1.2
添加环境变量
export HBASE_HOME=/home/app/hbase-1.1.2
2. 编辑配置文件
vi /home/app/hbase-1.1.2/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://Master:9000/hbase</value>
</property>
<!-- 完全分布式下为true,单机或伪分布为false -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://Master:60000</value>
</property>
<!-- 此处为连接zookeeper时的默认端口,之前我的zookeeper不是有hbase管理的,所以手工添加这个配置 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
<description>Property fromZooKeeper's config zoo.cfg. The port at which the clients willconnect.</description>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>Master,Slaver1,Slaver2</value>
</property>
<!-- 此处为zookeeper的默认配置目录,不修改的时候hbase默认将目录放在/tem下面 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/app/zookeeper-3.4.6/conf/data</value>
<description>Property from ZooKeeper's config zoo.cfg. The directory where the snapshot is stored. </description>
</property>
<!-- 这是设置hbase的web端 端口 -->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
</configuration>第一个属性指定本机的hbase的存储目录;
第二个属性指定hbase的运行模式,true代表全分布模式;
第四、五、六和第七个属性是关于Zookeeper集群的配置。
第八个属性是Hbase配置的web端访问端口,之前没有配不知道启动的默认端口,一直无法访问。
此处配置需要注意标红部分,然后 hbase.zookeeper.quorum 的value里面写主机名,当然最好是部署奇数个,偶数个不是不可以的,但是zookeeper集群是以宕机个数过半才会让整个集群宕机的,所以奇数个集群更佳。
其中首先需要注意 hdfs://Master:9000/hbase 这里,必须与你的Hadoop集群的 core-site.xml 文件配置保持完全一致才行,如果你Hadoop的 hdfs使用了其它端口,请在这里也修改。
再者就是Hbase该项并不识别机器IP,只能使用机器 hostname才可行,即若使用 Master 的 IP: 10.10.10.10 是会抛出java错误,至于具体的错误这里就不关注了。
修改regionservers,在regionservers文件中添加如下内容:
Slaver1
Slaver2
修改 hbase-env.sh 文件
export JAVA_HOME=/usr/java/jdk1.8.0_60,本处写法 /usr/java/latest 是指向默认安装的jdk的。
还需要添加 HBASE_HOME/HADOOP_HOME,这些框架都无法直接获取本地环境变量,不知是否存在某处错误引起
下面的环境变量解释:
HBASE_MANAGES_ZK:代表由Hbase来启动关闭zookeeper,如果你的zookeeper是有自己手工启动的话,这里配false,且上面配置文件里面关于zookeeper的部分可以不配。
最后的两个环境变量,注释已经解释了 JDK7 需要,JDK8完全可以去掉,我是JDK8,之前没看这个注释,后面出了错误才发现。
所以修改后的为这样:
修改完成后将该配置复制到其他机器
scp -r ./hbase-1.1.2 Slaver1:/home/app
scp -r ./hbase-1.1.2 Slaver2:/home/app
3. 修改hadoop目录下的etc/hadoop/hdfs-site.xml,添加下面参数
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
启动HBase
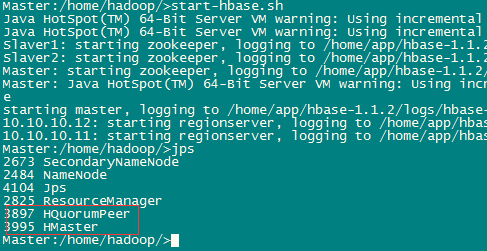
启动hbase时要确保hdfs已经启动。在主节点上执行: start-hbase.sh
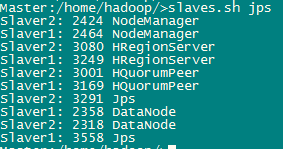
启动成功后集群会多出如下进程:
Namenode:
Datanode:
总结:
这样本次安装Hbase-1.1.2 就完成了。整个过程没有太多难点。只要关注细节还是无脑配置。


Hbase 测试
1. 通过浏览器访问 http://10.10.10.10:60010 ,出现如下界面
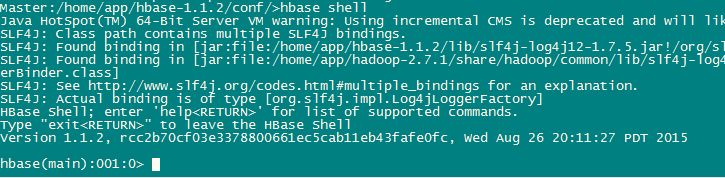
2. 通过Hbase shell 测试
a. 执行 hbase shell 命令
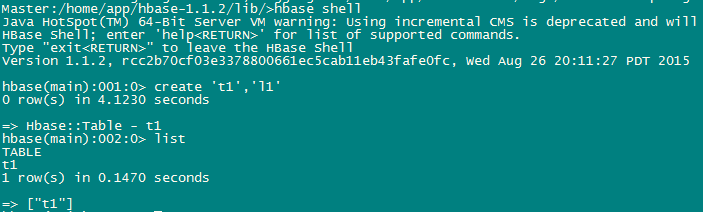
b. 创建一个 test 表 。
此时在执行建表语句时发生一个错误 ERROR: Can't get master address from ZooKeeper; znode data == null,并且HMaster进程掉了
查找资料发现有两种解释:
1. HDFS的格式化存在问题,pid不一致导致的连接错误。
2. 就是没有安装Zookeeper 导致的
经过仔细分析,发现其他人在进行这步操作时没有提到要另外安装Zookeeper,所以先进行第一步测试。经过测试后发现启动后过了一会HMaster 进程还是掉了。查看下hbase的logs里面的Zookeeper日志,发现都是连接Slavers错误,后来想想这个Zookeeper应该要装,别人没提到可能是单机版或是提前就配好了这玩意儿。安装步骤这里就不写了,先去安装Zookeeper,待会再来继续进行测试。
3. 经过一段时间的尝试把zookeeper3.4.6 安装成功后,Hbase 终于可以使用了。顺带解决了上面图片显示 slf4j 报错问题,这是这个jar冲突,选择其中一个删除就行了。然后Hbase 在执行 list 时报错,需要将 hadoop下的相关jar 复制到 hbase的lib下面替换,这一步很重要 !
执行创建表的语句
create ‘t1’,’l1’
在WEB端也可以查看表内容
Hbase数据库常用操作命令
hbase(main):002:0> scan 't1'
ROW COLUMN+CELL
0 row(s) in 1.1780 seconds hbase(main):003:0> put 't1','row1','l1','value1'
0 row(s) in 0.4310 seconds hbase(main):004:0> scan 't1'
ROW COLUMN+CELL
row1 column=l1:, timestamp=1446370889665, value=value1
1 row(s) in 0.1010 seconds hbase(main):005:0> put 't1','exe1','l1','value2'
0 row(s) in 0.1040 seconds hbase(main):006:0> scan 't1'
ROW COLUMN+CELL
exe1 column=l1:, timestamp=1446370960268, value=value2
row1 column=l1:, timestamp=1446370889665, value=value1
2 row(s) in 0.0820 seconds hbase(main):007:0> get 't1','row1'
COLUMN CELL
l1: timestamp=1446370889665, value=value1
1 row(s) in 0.1660 seconds hbase(main):008:0> disable 't1'
0 row(s) in 3.2110 seconds hbase(main):009:0> drop 't1'
0 row(s) in 2.4040 seconds hbase(main):010:0> list
TABLE
0 row(s) in 0.0440 seconds hbase(main):011:0> exit这次全分布下的 Hbase 安装就算完结了...


大数据: 完全分布式Hadoop集群-HBase安装的更多相关文章
- 【大数据系列】hadoop集群设置官方文档翻译
Hadoop Cluster Setup Purpose Prerequisites Installation Configuring Hadoop in Non-Secure Mode Config ...
- 【大数据系列】hadoop集群的配置
一.hadoop的配置文件分类 1.只读类型的默认文件 core-default.xml hdfs-default.xml mapred-default.xml mapred-que ...
- hadoop的基本概念 伪分布式hadoop集群的安装 hdfs mapreduce的演示
hadoop 解决问题: 海量数据存储(HDFS) 海量数据的分析(MapReduce) 资源管理调度(YARN)
- 沉淀,再出发——在Hadoop集群之上安装hbase
在Hadoop集群之上安装hbase 一.安装准备 首先我们确保在ubuntu16.04上安装了以下的产品,java1.8及其以上,ssh,hadoop集群,其次,我们需要从hbase的官网上下载并安 ...
- 高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南
原文:http://my.oschina.net/wstone/blog/365010#OSC_h3_13 (WJW)高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南 [X] ...
- Apache Hadoop集群离线安装部署(三)——Hbase安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Ganglia监控Hadoop集群的安装部署[转]
Ganglia监控Hadoop集群的安装部署 一. 安装环境 Ubuntu server 12.04 安装gmetad的机器:192.168.52.105 安装gmond的机 器:192.168.52 ...
- Apache Hadoop集群离线安装部署(二)——Spark-2.1.0 on Yarn安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS、YARN、MR)安装
虽然我已经装了个Cloudera的CDH集群(教程详见:http://www.cnblogs.com/pojishou/p/6267616.html),但实在太吃内存了,而且给定的组件版本是不可选的, ...
随机推荐
- cnblogs
想注册个博客园来着的,看着大佬们的博客都十分漂亮,但是发现我因为太菜没有办法搞定美化问题. 以后再说吧 写写东西,反正也没人看,但是写的时候尽量按给别人看的格式写吧 2019.3.15 开通博客 计划 ...
- Redis单机多节点集群实验
第一步:安装Redis 前面已经安装过了 不解释, Reids安装包里有个集群工具,要复制到/usr/local/bin里去 cp redis-3.2.9/src/redis-trib.rb /usr ...
- 【Idea】Intellij Idea debug 模式如果发现异常,即添加异常断点在发生异常处
前用eclipse的时候,可以根据所抛出的异常进行调试,比如:出现了空指针异常,我想知道是哪一行抛出的,在eclipse中我只需在debug模式下把空指针异常这个名字设置进去,当遇到空指针异常时,ec ...
- jupyter notebook 动态图显示
直接在import matplotlib.pyplot as plt 后面加%matplotlib,或者%matplotlib auto就可以通过弹出窗口的形式显示图片
- REST framework---基于类的视图
一.程序设计 1.路由设计 from django.conf.urls import url from django.contrib import admin from app import view ...
- Python在终端通过pip安装好包以后,在Pycharm中依然无法使用的解决办法
在终端通过pip装好包以后,在pycharm中导入包时,依然会报错.新手不知道具体原因是什么,我把我的解决过程发出来. pip install 解决方案一: 在Pycharm中,依次打开File--- ...
- 打return
var zz=xx(); alert(zz); zz=yy(); alert(zz); function xx(){ var i=1,j=2; return i+j; } function yy(){ ...
- PyTorch in Action: A Step by Step Tutorial
PyTorch in Action: A Step by Step Tutorial PyTorch in Action: A Step by Step Tutorial Installation ...
- Python中的7种可调用对象
Python中有七种可调用对象,可调用对象可使用内置函数callable来检测 一.用户自定义的函数: 使用def语句或者lambda表达式创建的函数. 二.内置函数: 使用C语言实现的函数,如len ...
- Python数据分析Pandas库之熊猫(10分钟二)
pandas 10分钟教程(二) 重点发法 分组 groupby('列名') groupby(['列名1','列名2',.........]) 分组的步骤 (Splitting) 按照一些规则将数据分 ...