为什么Kafka速度那么快
Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka的特性之一就是高吞吐率。
即使是普通的服务器,Kafka也可以轻松支持每秒百万级的写入请求,超过了大部分的消息中间件,这种特性也使得Kafka在日志处理等海量数据场景广泛应用。
针对Kafka的基准测试可以参考,Apache Kafka基准测试:每秒写入2百万(在三台廉价机器上)
下面从数据写入和读取两方面分析,为什么为什么Kafka速度这么快。
写入数据
Kafka会把收到的消息都写入到硬盘中,它绝对不会丢失数据。为了优化写入速度Kafka采用了两个技术, 顺序写入 和 MMFile 。
顺序写入
磁盘读写的快慢取决于你怎么使用它,也就是顺序读写或者随机读写。在顺序读写的情况下,磁盘的顺序读写速度和内存持平。
因为硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最讨厌随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
而且Linux对于磁盘的读写优化也比较多,包括read-ahead和write-behind,磁盘缓存等。如果在内存做这些操作的时候,一个是JAVA对象的内存开销很大,另一个是随着堆内存数据的增多,JAVA的GC时间会变得很长,使用磁盘操作有以下几个好处:
- 磁盘顺序读写速度超过内存随机读写
- JVM的GC效率低,内存占用大。使用磁盘可以避免这一问题
- 系统冷启动后,磁盘缓存依然可用
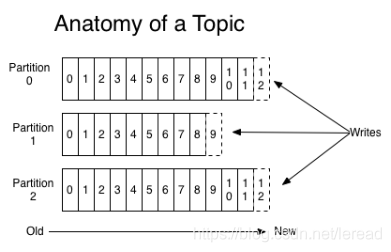
上图就展示了Kafka是如何写入数据的, 每一个Partition其实都是一个文件 ,收到消息后Kafka会把数据插入到文件末尾(虚框部分)。
这种方法有一个缺陷—— 没有办法删除数据 ,所以Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示 读取到了第几条数据 。

两个消费者,Consumer1有两个offset分别对应Partition0、Partition1(假设每一个Topic一个Partition);Consumer2有一个offset对应Partition2。这个offset是由客户端SDK负责保存的,Kafka的Broker完全无视这个东西的存在;一般情况下SDK会把它保存到zookeeper里面。(所以需要给Consumer提供zookeeper的地址)。
如果不删除硬盘肯定会被撑满,所以Kakfa提供了两种策略来删除数据。一是基于时间,二是基于partition文件大小。具体配置可以参看它的配置文档。
Memory Mapped Files
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并 不是实时的写入硬盘 ,它充分利用了现代操作系统 分页存储 来利用内存提高I/O效率。
Memory Mapped Files(后面简称mmap)也被翻译成 内存映射文件 ,在64位操作系统中一般可以表示20G的数据文件,它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。
通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存),也不必关心内存的大小有虚拟内存为我们兜底。
使用这种方式可以获取很大的I/O提升, 省去了用户空间到内核空间 复制的开销(调用文件的read会把数据先放到内核空间的内存中,然后再复制到用户空间的内存中。)也有一个很明显的缺陷——不可靠, 写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。 Kafka提供了一个参数——producer.type来控制是不是主动flush,如果Kafka写入到mmap之后就立即flush然后再返回Producer叫 同步 (sync);写入mmap之后立即返回Producer不调用flush叫 异步 (async)。
读取数据
Kafka在读取磁盘时做了哪些优化?
基于sendfile实现Zero Copy
传统模式下,当需要对一个文件进行传输的时候,其具体流程细节如下:
- 调用read函数,文件数据被copy到内核缓冲区
- read函数返回,文件数据从内核缓冲区copy到用户缓冲区
- write函数调用,将文件数据从用户缓冲区copy到内核与socket相关的缓冲区。
- 数据从socket缓冲区copy到相关协议引擎。
以上细节是传统read/write方式进行网络文件传输的方式,我们可以看到,在这个过程当中,文件数据实际上是经过了四次copy操作:
硬盘—>内核buf—>用户buf—>socket相关缓冲区—>协议引擎
而sendfile系统调用则提供了一种减少以上多次copy,提升文件传输性能的方法。
在内核版本2.1中,引入了sendfile系统调用,以简化网络上和两个本地文件之间的数据传输。 sendfile的引入不仅减少了数据复制,还减少了上下文切换。
sendfile(socket, file, len);
运行流程如下:
- sendfile系统调用,文件数据被copy至内核缓冲区
- 再从内核缓冲区copy至内核中socket相关的缓冲区
- 最后再socket相关的缓冲区copy到协议引擎
相较传统read/write方式,2.1版本内核引进的sendfile已经减少了内核缓冲区到user缓冲区,再由user缓冲区到socket相关缓冲区的文件copy,而在内核版本2.4之后,文件描述符结果被改变,sendfile实现了更简单的方式,再次减少了一次copy操作。
在apache,nginx,lighttpd等web服务器当中,都有一项sendfile相关的配置,使用sendfile可以大幅提升文件传输性能。
Kafka把所有的消息都存放在一个一个的文件中,当消费者需要数据的时候Kafka直接把文件发送给消费者,配合mmap作为文件读写方式,直接把它传给sendfile。
批量压缩
在很多情况下,系统的瓶颈不是CPU或磁盘,而是网络IO,对于需要在广域网上的数据中心之间发送消息的数据流水线尤其如此。进行数据压缩会消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑。
- 如果每个消息都压缩,但是压缩率相对很低,所以Kafka使用了批量压缩,即将多个消息一起压缩而不是单个消息压缩
- Kafka允许使用递归的消息集合,批量的消息可以通过压缩的形式传输并且在日志中也可以保持压缩格式,直到被消费者解压缩
- Kafka支持多种压缩协议,包括Gzip和Snappy压缩协议
总结
Kafka速度的秘诀在于,它把所有的消息都变成一个批量的文件,并且进行合理的批量压缩,减少网络IO损耗,通过mmap提高I/O速度,写入数据的时候由于单个Partion是末尾添加所以速度最优;读取数据的时候配合sendfile直接暴力输出。
为什么Kafka速度那么快的更多相关文章
- 为什么 Kafka 速度那么快?
来源:cnblogs.com/binyue/p/10308754.html Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafk ...
- kafka速度为什么快
1. kafka 使用了 分区.分布式.leader/followere 的方式.分布式让 kafka 排除了单点故障,分区和分区复制让数据不丢失2. kafka 使用 zero copy 技术 (基 ...
- Kafka为什么速度那么快?
Kafka为什么速度那么快? Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka的特性之一就是高吞吐率. 即使是普通的服务器 ...
- Kafka为什么速度那么快?该怎么回答
Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka的特性之一就是高吞吐率.即使是普通的服务器,Kafka也可以轻松支持每秒百 ...
- 【知识点】同样是消息队列,Kafka凭什么速度那么快?
同样是消息队列,Kafka凭什么速度那么快? 作者 | MrZhangxd Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafk ...
- Kafka速度为什么那么快
记录一下 Kafka速度为什么那么快 Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上读写数据是会降低性能的,因为寻址会比较消耗时间,但是实际上,Kafka的特性之一就是高吞吐率. 即使是普通 ...
- Senna.js – 速度极快的单页应用程序引擎
Senna.js 是一个速度超快的单页应用程序引擎,提供了几个低级别的 API,可以帮助你打造现代化的基于 Web 的应用程序.更重要的是,搜索引擎蜘蛛应该能够索引相同的内容. 通过使用 HTML5 ...
- Android解析Json速度最快的库:json-smart
场景描写叙述: 本文仅验证了在安卓环境下使用Json的Key作为反序列化条件的解析速度.结论是解析速度最快的不是阿里的fastjson,也不是Google的Gson,而是json-smart. And ...
- 美国vps哪个比较好,vps国内访问速度最快!
沃网中国是一家成立于2008年的国内idc商,提供基于hyper-v架构的VPS产品,数据中心包括国内电信.美国洛杉矶等,他们采用的是国内访问最快的加州机房ping值,160-180左右相当给力的速度 ...
随机推荐
- [rhel]安装oracle11g
https://www.linuxidc.com/Linux/2017-04/142562.htm
- MySQL架构备份
MySQL Replication 概述 集群的主要类型? 高可用集群(High Available Cluster, HA) 高可用集群是指通过特殊的软件把独立的服务器连接起来,组成一个能够提供故障 ...
- 3d
http://jokerwang.com/diy-3d%E6%89%93%E5%8D%B0%E6%9C%BA1-%E7%A1%AC%E4%BB%B6%E7%AF%87/
- 如何快速上手Mac
网络上关于Mac的教程很多,大部分问题通过百度和谷歌就能搞定了.对于技巧的细节,我将不再过多的重复,看了我的参考资料基本就能够全部了解,他们也比我讲得详细得很多.我这篇文章想做的,是以一个普通的win ...
- kubernetes之管理容器的计算资源
资源类型 CPU 和 memory 都是 资源类型.资源类型具有基本单位.CPU 的单位是 core,memory 的单位是 byte.这些都统称为计算资源. CPU含义: CPU 资源的限制和请求以 ...
- postgreSql 基本操作总结
0. 启动pgsl数据库 pg_ctl -D /xx/pgdata start 1. 命令行登录数据库 1 psql -U username -d dbname -h hostip -p po ...
- 暑假闲着没事第一弹:基于Django的长江大学教务处成绩查询系统
本篇文章涉及到的知识点有:Python爬虫,MySQL数据库,html/css/js基础,selenium和phantomjs基础,MVC设计模式,ORM(对象关系映射)框架,django框架(Pyt ...
- 开放源代码的设计层面框架Spring——day03
spring第三天 一.AOP的相关概念 1.1AOP概述 1.1.1什么是AOP AOP:全称是Aspext Orie ...
- Keras的一些功能函数
摘自: https://www.cnblogs.com/Anita9002/p/8136357.html 1.模型的信息提取 # 节点信息提取 config = model.get_config() ...
- HDU-1028 Ignatius and the Princess III(生成函数)
题意 给出$n$,问用$1$到$n$的数字问能构成$n$的方案数 思路 生成函数基础题,$x^{n}$的系数即答案. 代码 #include <bits/stdc++.h> #define ...