『高性能模型』轻量级网络ShuffleNet_v1及v2
项目实现:GitHub
参考博客:CNN模型之ShuffleNet
v1论文:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
v2论文:ShuffleNet V2: Practical Guidelines for Ecient CNN Architecture Design
一、分组卷积
Group convolution是将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。因为一般的卷积都是在所有的输入特征图上做卷积,可以说是全通道卷积,这是一种通道密集连接方式(channel dense connection),而group convolution相比则是一种通道稀疏连接方式(channel sparse connection)。
tensorflow和分组卷积的讨论:Feature Request: Support for depthwise convolution by groups
1、分组卷积的矛盾——计算量
使用group convolution的网络有很多,如Xception,MobileNet,ResNeXt等。其中Xception和MobileNet采用了depthwise convolution,这是一种比较特殊的group convolution,此时分组数恰好等于通道数,意味着每个组只有一个特征图。是这些网络存在一个很大的弊端是采用了密集的1x1 pointwise convolution(如下图)。

这个问题可以解决:对1x1卷积采用channel sparse connection 即分组操作,那样计算量就可以降下来了,但这就涉及到另外一个问题。
2、分组卷积的矛盾——特征通信
group convolution层另一个问题是不同组之间的特征图需要通信,否则就好像分了几个互不相干的路,大家各走各的,会降低网络的特征提取能力,这也可以解释为什么Xception,MobileNet等网络采用密集的1x1 pointwise convolution,因为要保证group convolution之后不同组的特征图之间的信息交流。
3、channel shuffle
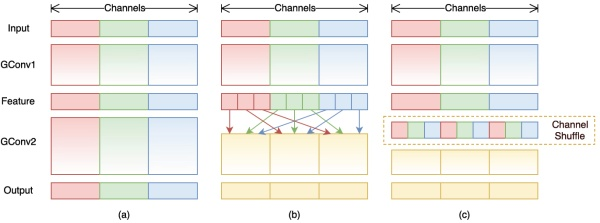
为达到特征通信目的,我们不采用dense pointwise convolution,考虑其他的思路:channel shuffle。如图b,其含义就是对group convolution之后的特征图进行“重组”,这样可以保证接下了采用的group convolution其输入来自不同的组,因此信息可以在不同组之间流转。图c进一步的展示了这一过程并随机,其实是“均匀地打乱”。
在程序上实现channel shuffle是非常容易的:假定将输入层分为 组,总通道数为
,首先你将通道那个维度拆分为
两个维度,然后将这两个维度转置变成
,最后重新reshape成一个维度
。
二、ShuffleNet
ShuffleNet的核心是采用了两种操作:pointwise group convolution和channel shuffle,这在保持精度的同时大大降低了模型的计算量。其基本单元则是在一个残差单元的基础上改进而成。
1、ShuffleNet基本单元
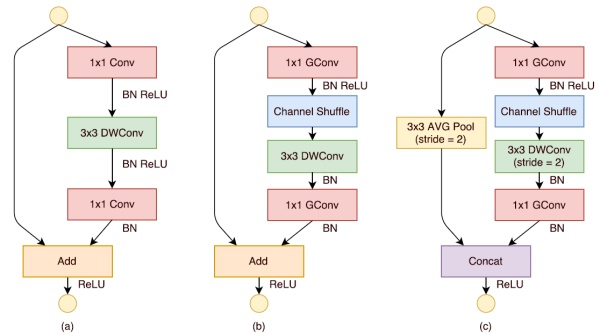
下图a展示了基本ResNet轻量级结构,这是一个包含3层的残差单元:首先是1x1卷积,然后是3x3的depthwise convolution(DWConv,主要是为了降低计算量),这里的3x3卷积是瓶颈层(bottleneck),紧接着是1x1卷积,最后是一个短路连接,将输入直接加到输出上。
下图b展示了改进思路:将密集的1x1卷积替换成1x1的group convolution,不过在第一个1x1卷积之后增加了一个channel shuffle操作。值得注意的是3x3卷积后面没有增加channel shuffle,按paper的意思,对于这样一个残差单元,一个channel shuffle操作是足够了。还有就是3x3的depthwise convolution之后没有使用ReLU激活函数。
下图c展示了其他改进,对原输入采用stride=2的3x3 avg pool,在depthwise convolution卷积处取stride=2保证两个通路shape相同,然后将得到特征图与输出进行连接(concat,借鉴了DenseNet?),而不是相加。极致的降低计算量与参数大小。
2、ShuffleNet网络结构

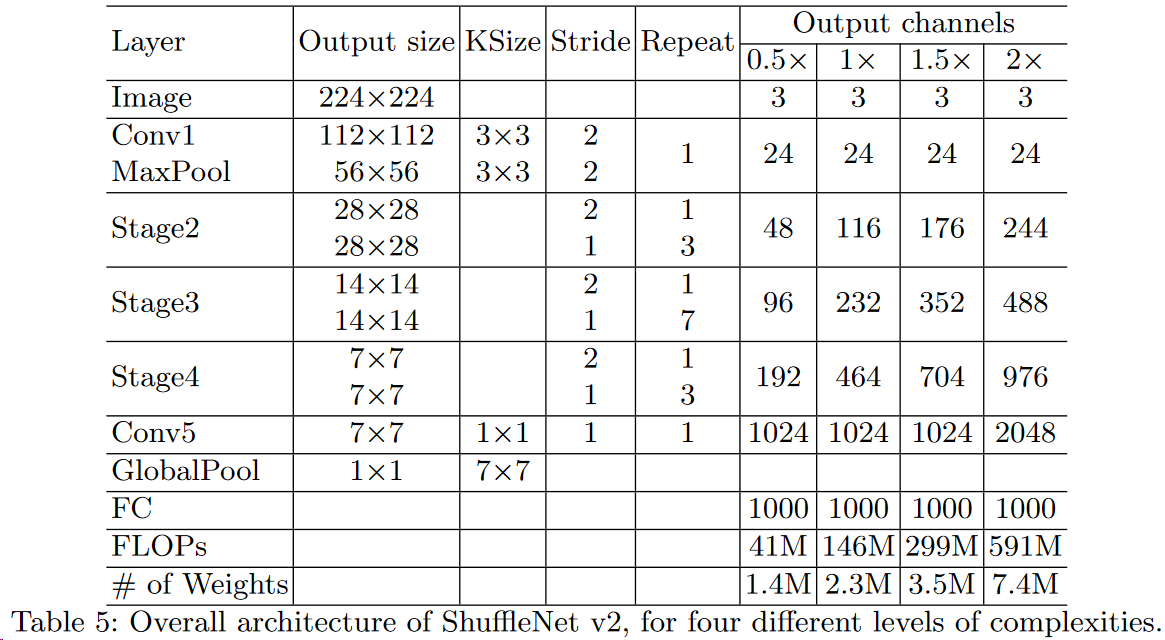
可以看到开始使用的普通的3x3的卷积和max pool层。然后是三个阶段,每个阶段都是重复堆积了几个ShuffleNet的基本单元。对于每个阶段,第一个基本单元采用的是stride=2,这样特征图width和height各降低一半,而通道数增加一倍。后面的基本单元都是stride=1,特征图和通道数都保持不变。对于基本单元来说,其中瓶颈层,就是3x3卷积层的通道数为输出通道数的1/4,这和残差单元的设计理念是一样的。
3、对比实验
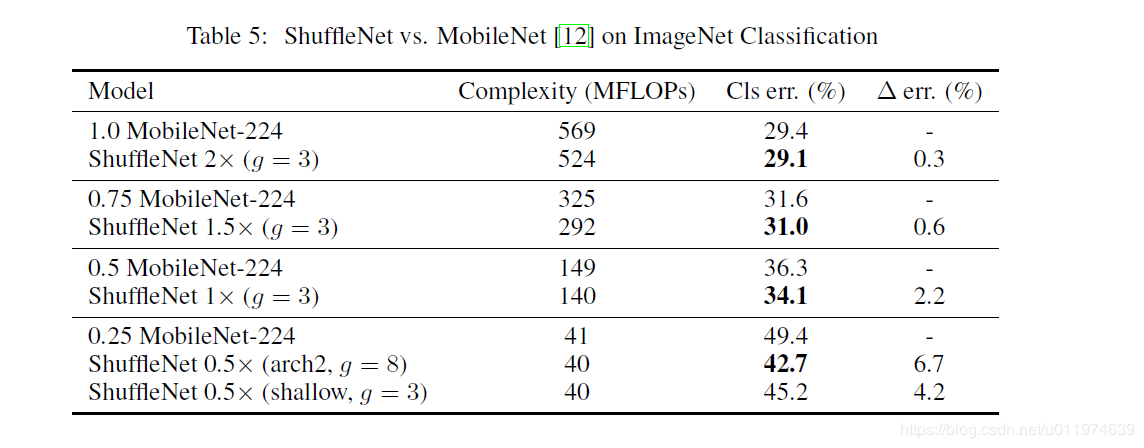
下表给出了不同g值(分组数)的ShuffleNet在ImageNet上的实验结果。可以看到基本上当g越大时,效果越好,这是因为采用更多的分组后,在相同的计算约束下可以使用更多的通道数,或者说特征图数量增加,网络的特征提取能力增强,网络性能得到提升。注意Shuffle 1x是基准模型,而0.5x和0.25x表示的是在基准模型上将通道数缩小为原来的0.5和0.25。
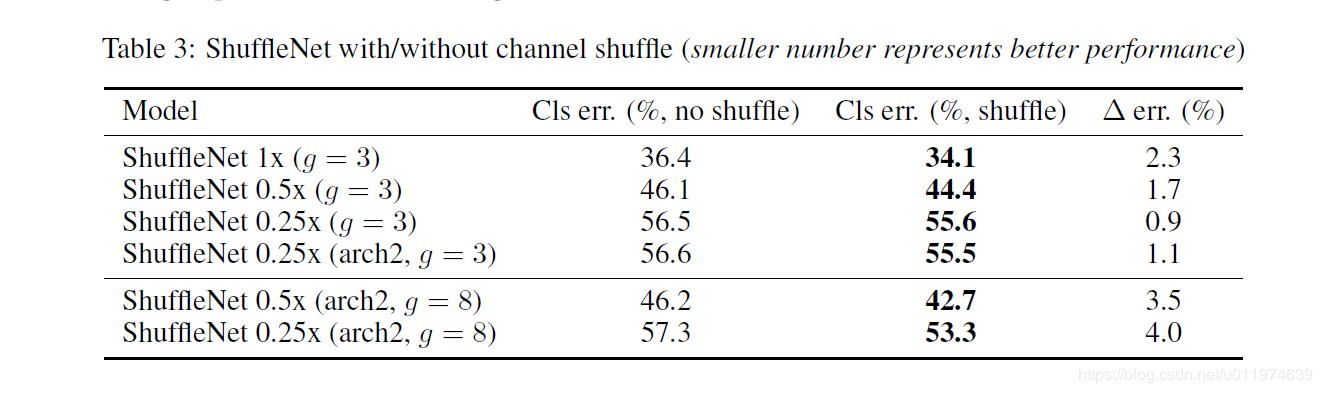
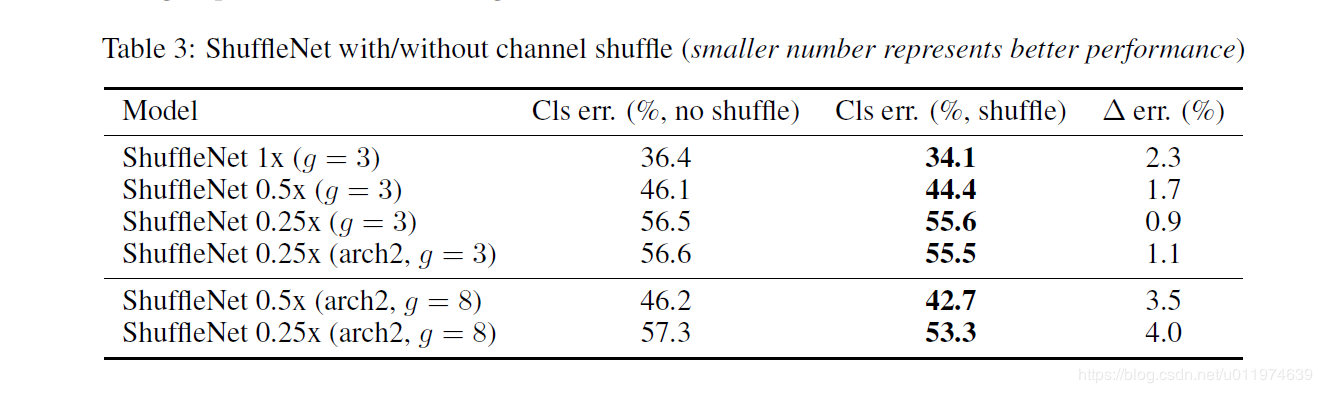
除此之外,作者还对比了不采用channle shuffle和采用之后的网络性能对比,如下表的看到,采用channle shuffle之后,网络性能更好,从而证明channle shuffle的有效性。
然后是ShuffleNet与MobileNet的对比,如下表ShuffleNet不仅计算复杂度更低,而且精度更好。
三、ShuffleNet_v2
我们首先来看v1版本和v2版本的基础单元,(a)和(b)是ShuffleNet v1的两种不同block结构,两者的差别在于后者对特征图尺寸做了缩小,这和ResNet中某个stage的两种block功能类似,同理(c)和(d)是ShuffleNet v2的两种不同block结构:

看点如下:
从(a)和(c)的对比可以看出首先(c)在开始处增加了一个channel split操作,这个操作将输入特征的通道分成c-c’和c’,c’在文章中采用c/2,这主要是和第1点发现对应
然后(c)中取消了1*1卷积层中的group操作,这和第2点发现对应,同时前面的channel split其实已经算是变相的group操作了
channel shuffle的操作移到了concat后面,和第3点发现对应,同时也是因为第一个1*1卷积层没有group操作,所以在其后面跟channel shuffle也没有太大必要
最后是将element-wise add操作替换成concat,这个和第4点发现对应。
多个(c)结构连接在一起的话,channel split、concat和channel shuffle是可以合并在一起的。(b)和(d)的对比也是同理,只不过因为(d)的开始处没有channel split操作,所以最后concat后特征图通道数翻倍,可以结合后面具体网络结构来看:
现在我们查看一个新的概念:内存访问消耗时间(memory access cost),它正比于模型对内存的消耗(特征大小+卷积核大小),在这篇文章中作者使用该指标来衡量模型的速度而非传统的FLOPs(float-point operations),它更多的侧重卷积层的乘法操作,作者认为FLOPs并不能实质的反应模型速度。
现在我们来看一下这四点发现,分别对应了结构中的四点创新:
卷积层的输入和输出特征通道数相等时MAC最小,此时模型速度最快
过多的group操作会增大MAC,从而使模型速度变慢
模型中的分支数量越少,模型速度越快
element-wise操作所带来的时间消耗远比在FLOPs上的体现的数值要多,因此要尽可能减少element-wise操作
至于模型的具体提升,建议之间看原文的图表。
『高性能模型』轻量级网络ShuffleNet_v1及v2的更多相关文章
- 『高性能模型』轻量级网络MobileNet_v2
论文地址:MobileNetV2: Inverted Residuals and Linear Bottlenecks 前文链接:『高性能模型』深度可分离卷积和MobileNet_v1 一.Mobil ...
- 『高性能模型』HetConv: HeterogeneousKernel-BasedConvolutionsforDeepCNNs
论文地址:HetConv 一.现有网络加速技术 1.卷积加速技术 作者对已有的新型卷积划分如下:标准卷积.Depthwise 卷积.Pointwise 卷积.群卷积(相关介绍见『高性能模型』深度可分离 ...
- 『高性能模型』卷积复杂度以及Inception系列
转载自知乎:卷积神经网络的复杂度分析 之前的Inception学习博客: 『TensorFlow』读书笔记_Inception_V3_上 『TensorFlow』读书笔记_Inception_V3_下 ...
- 『高性能模型』Roofline Model与深度学习模型的性能分析
转载自知乎:Roofline Model与深度学习模型的性能分析 在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等 ...
- 『高性能模型』深度可分离卷积和MobileNet_v1
论文原址:MobileNets v1 TensorFlow实现:mobilenet_v1.py TensorFlow预训练模型:mobilenet_v1.md 一.深度可分离卷积 标准的卷积过程可以看 ...
- 『深度应用』NLP机器翻译深度学习实战课程·壹(RNN base)
深度学习用的有一年多了,最近开始NLP自然处理方面的研发.刚好趁着这个机会写一系列NLP机器翻译深度学习实战课程. 本系列课程将从原理讲解与数据处理深入到如何动手实践与应用部署,将包括以下内容:(更新 ...
- ShuffleNetV1/V2简述 | 轻量级网络
ShuffleNet系列是轻量级网络中很重要的一个系列,ShuffleNetV1提出了channel shuffle操作,使得网络可以尽情地使用分组卷积来加速,而ShuffleNetV2则推倒V1的大 ...
- 『Python进阶』专题汇总
基础知识 Python3内置函数 『Python』库安装 『流畅的Python』第1~4章_数据结构.编码 『Python』基础数据结构常见使用方法 『Python CoolBook』数据结构和算法_ ...
- 2017-2018-2 165X 『Java程序设计』课程 助教总结
2017-2018-2 165X 『Java程序设计』课程 助教总结 本学期完成的助教工作主要包括: 编写300道左右测试题,用于蓝墨云课下测试: 发布博客三篇:<2017-2018-2 165 ...
随机推荐
- 如何执行shell命令
可使用 git 命令行来执行shell命令,如 D 盘下的一 shell 脚本 test.sh 如下: echo "Hello world" 打开命令行,输入命令执行: 转载请注明 ...
- CentOS 7 内核优化
[root@DaMoWang ~]# vim /etc/sysctl.conf #关闭ipv6 net.ipv6.conf.all.disable_ipv6 = net.ipv6.conf.def ...
- laravel5.7 前后端分离开发 实现基于API请求的token认证
最近在学习前后端分离开发,发现 在laravel中实现前后台分离是无法无法使用 CSRF Token 认证的.因为 web 请求的用户认证是通过Session和客户端Cookie的实现的,而前后端分离 ...
- ThinkAdmin for PHP后台管理系统
ThinkAdmin for PHP后台管理系统 ThinkAdmin 是一个基于 Thinkphp 5.1.x 开发的后台管理系统,集成后台系统常用功能.基于 ThinkPHP 5.1 基础开发平台 ...
- python函数部分----函数初识
0.来源http://www.cnblogs.com/jin-xin/articles/8241942.html 1.return 返回0个返回值,返回一个返回值.返回多个返回值 None.如果一个变 ...
- C/C++中数据的存储
学java时了解到不同的数据在系统中存储的位置不一样,有的存在栈里,有的存在堆里.学C/C++时没注意过这个,最近学数据结构时遇到了问题:在定义一个结构体的指针时,系统如何给它分配的空间?从而让我想去 ...
- 代码修改WinForm datagridview 样式 及数据绑定
#region 表格设置 /// <summary> /// 调整表格 /// </summary> /// <param name="dataGrid&quo ...
- Sql语法注意事项
#分组 group by 作用:group by 子句可以将结果集按照指定的字段值一样的记录进行分组,配合聚合函数 可以进行组内统计的工作. 注意1:当在select中时,查询的内容中如果包含聚合函数 ...
- 关于javaweb项目红叉报错可但项目可以正常运行的解决办法
有时候导入的项目工程,文件夹左下角永远有一个红叉,但是由于不影响程序运行,所以之前一直忽略了,但是强迫症患者表示不解决巨蓝瘦,网上有些方法没有讲清楚,所以今天做了个总结来教大家如何详细解 ...
- 为input标签绑定事件的几种方式
为input标签绑定事件的几种方式 1.JavaScript原生态的方式,直接复制下面的代码就会有相应的效果 <!DOCTYPE html><html><head> ...