Django-F,Q查询,Templatetags,session,中间件
内容总览
1.ORM的多对多的使用
1>语法与实例
2>聚合与分组
3>F与Q查询
4>事务
2.模板之自定义
1>初始化
2>filter
3>simple_tag
4>inclusion_tag
3.cookie和session--原理与比较,方法,无cookie时访问需要登陆页面的跳转处理
4.django中间件--请求流程,5种方法的使用与流程图
1.ORM的多对多的使用
1>ORM多对多的语法
#正向查询(表里有外键字段):获取作者对象,对多对多关系表中的book_id做操作 author_obj = models.Author.objects.last() #设置多对多关系 #方式一: author_obj.books.set([1,2]) #方式二: ret= models.Book.objects.filter(id__in=[1, 4, 16]) # author_obj.books.set(ret) author_obj.books.set([*ret]) #清空多对多关系 author_obj.books.set([])
#增删多对多的关系 #方式一:删IDauthor_obj.books.remove(4)author_obj.books.add(4) #方式二:删对象author_obj.books.remove(models.Book.objects.get(id=4))author_obj.books.add(models.Book.objects.get(id=16)) #清空所有多对多的关系author_obj.books.clear()
#创建一个新的书籍对象,并且和当前的作者做关联 author_obj.books.create(title='高等英语',publisher_id=3,price=150) #反向查询(表里无外键字段) 获取书籍对象,对多对多关系表中的author_id进行操作 book_obj = models.Book.objects.last() print(book_obj.author_set,book_obj.author_set.all()) #app01.Author.None <QuerySet [<Author: <作者:森,booksapp01.Book.None>>]> book_obj.author_set.add(4)
2>ORM的实例操作
models.py
class Book(models.Model):
title=models.CharField(max_length=32) #创建的属性是字符串 ---> title字段
price=models.IntegerField()
publisher = models.ForeignKey('Publisher') #创建的属性是一个主表Publisher对象 -->publiserh_id字段
def __str__(self):
return f'<书籍:{self.title} - 价格:{self.price}-出版社:{self.publisher}>'
class Author(models.Model):
author_name=models.CharField(max_length=32)
books=models.ManyToManyField(to='Book') #django自动生成第三张表
def __str__(self):
return f'<作者:{self.author_name},books{self.books}>'
views.py
def author_list(request):
author_obj = models.Author.objects.all()
return render(request,'author_list.html',{'author_obj':author_obj})
class Addauthor(View):
def get(self,request):
books = models.Book.objects.all()
return render(request,'author_add.html',{'base':'base.html','books':books})
def post(self,request):
new_name=self.request.POST.get('author_name')
# bood_id =self.request.POST.get('book')
bood_id =self.request.POST.getlist('book') # getlist:键值对应的是一个列表的时候需要用getlist
print(bood_id)
#['1', '2', '3']
#创建作者对象
author_obj=models.Author.objects.create(author_name=new_name)
#建立作者和书籍得关系
#print(models.Author.books,type(models.Author.books))
#<django.db.models.fields.related_descriptors.ManyToManyDescriptor object at 0x00000204EC7E9DA0> <class 'django.db.models.fields.related_descriptors.ManyToManyDescriptor'>
#通过关联对象设置第三张表,可以一次性设置多个关系
author_obj.books.set(bood_id)
return self.get(request)
class Editauthor(View):
def get(self,request,edit_id):
books = models.Book.objects.all()
author_obj = models.Author.objects.filter(id=edit_id).first()
return render(request,'author_edit.html',{'books':books,'author_obj':author_obj,'base':'base.html'})
def post(self,request,edit_id):
#获取修改的对象
new_name = self.request.POST.get('author_name')
book_id = self.request.POST.getlist('book')
author_obj = models.Author.objects.filter(id=edit_id).first()
#方式一
author_obj.author_name =new_name
author_obj.save()
#方式二
# author_obj = models.Author.objects.filter(id=edit_id)
# author_obj.update(author_name=new_name)
#author_obj.first().books.set(book_id)
author_obj.books.set(book_id)
return redirect(reverse('author'))
3>ORM的聚合和分组
from django.db.models import Sum,Avg,Max,Min,Count
#聚合 aggregate终止语句
ret = models.Book.objects.aggregate(Sum('price'),Count('price'),max=Max('price'))
print(ret,type(ret))
#{'max': 255, 'price__sum': 1928, 'price__count': 11} <class 'dict'>
#Book与author对象是多对多的关系
#查Book的对象的所有内容,拼接一个Count('author')字段,相当于把聚合结果放到对象中
ret = models.Book.objects.annotate(Count('author')).values()
for i in ret:
print(i)
#每个出版社价格最低的书
ret2 = models.Publisher.objects.annotate(Min('bk__price')).values()
print(ret2)
#values按指定字段去分组
ret3=models.Book.objects.values('publisher__name').annotate(min=Min('price')).values('publisher__name','min')
# ret3=models.Book.objects.values('publisher__name').annotate(min=Min('price')).values() 错误 ,分组之后只能取分组相关的字段
for i in ret3:
print(i)
#SELECT `app01_publisher`.`name`, MIN(`app01_book`.`price`) AS `min` FROM `app01_book` INNER JOIN `app01_publisher`
# ON (`app01_book`.`publisher_id` = `app01_publisher`.`id`) GROUP BY `app01_publisher`.`name` ORDER BY NULL;
#查询大于一个作者的书
ret = models.Book.objects.annotate(count=Count('author')).filter(count__gt=1).values()
for i in ret:
print(i)
#根据作者的数量排序
ret =models.Book.objects.annotate(count=Count('author')).order_by('count')
#查询每个作者出书的总价格
ret = models.Author.objects.annotate(Sum('books__price')).values()
4>ORM的F,Q查询和事务
from django.db.models import F,Q
#F 用来取表中动态的字段
#查询库存小于销量的书籍 比较动态的字段
ret = models.Book.objects.filter(inventory__lt=F('sale')).values()
# print(ret)
ret1 = models.Book.objects.update(sale=F('sale')*2)
#Q 可以将查询条件变成 或的 关系
#逗号连接的条件都是 and的关系
ret = models.Book.objects.filter(id__gte=7,title='史记').values()
print(ret)
#使用Q查询可以 使用 与 或 非三种关系
ret2 = models.Book.objects.filter(Q(id__lt=2)|Q(id__gte=13)).values()
print(ret2)
ret3 = models.Book.objects.filter(Q(id__lt=2) & Q(id__gte=13)).values()
print(ret3)
ret4=models.Book.objects.filter(~Q(Q(id__lt=2)|Q(id__gte=13))).values()
for i in ret4:
print(i)
#事务 出现异常数据库不进行任何操作
from django.db import transaction
try:
with transaction.atomic():
models.Book.objects.update(price=F('price')+50)
models.Book.objects.get(id=100) #异常
models.Book.objects.update(price=F('price')-30)
except Exception as e:
print(e)
2.模板之自定义filter,simple_tag,inclusion_tag
1>初始化步骤
a.在app下创建一个名为templatetags(名字不可变)的python包
b. 在templatetags下创建python文件 名字可随意 my_tags
c.导入并实例化
my_tags.py from django import template register=template.Library() #register 固定的名字
2>filter的使用
my_tags.py
@register.filter(name='ddb')
def add_str(value,arg):
ret=f'{value}_{arg}'
return ret
html#加载文件
{% load my_tags %}
{#{{ 'alex'|add_str:'xxxb' }}#}
#使用文件定义的函数{{ 'alex'|ddb:'xxxb' }}
#浏览器:alex_xxxb
views.py
def tag_test(request):
return render(request,'tag_test.html')
3>simple_tag的使用
my_tags.py#装饰器后面要加括号,否则在pychram中可以使用但是会漂黄
@register.simple_tag()
def string_join(*args,**kwargs):
ret = '_'.join(args) + '*'.join(kwargs.values())
return ret
html{% load my_tags %} {% string_join ' %}#浏览器:dddd_sdfsdferwer*2131
4>inclusion_tag的使用
my_tags.py
@register.inclusion_tag('pagination.html')
def pagination(total,page):
return {'total':range(1,total+1),'page':page}
author_list.html
#需要使用代码段的页面
{% load my_tags %}
{% pagination 6 1%}
pagination.html
#代码段的渲染
{% for num in total %}
{% if num == page %}
<li class="active"><a href="#">{{ num }}</a></li>
{% else %}
<li><a href="#">{{ num }}</a></li>
{% endif %}
{% endfor %}
流程演示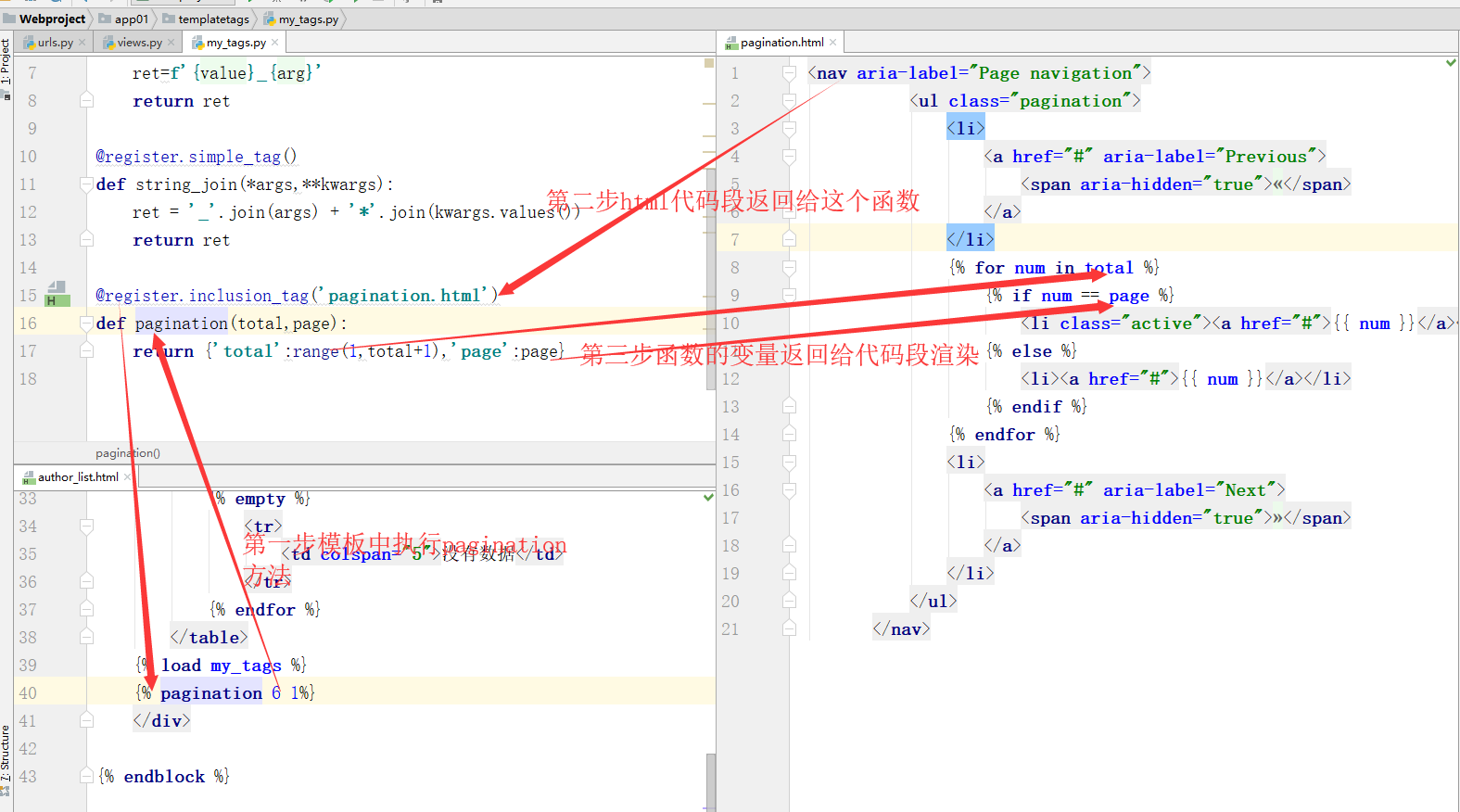
3.cookie和session
1>cookie
保存在浏览器本地的一组键值对,是服务器让浏览器进行设置的,由服务器决定是否设置,浏览器访问服务器的时候有cookie可以自动登陆
cookie的本质:用来保持服务器与客户端的会话状态
设置cookie:服务器对请求的url(例如http://127.0.0.1:8000/app01/login/) 设置了一个响应头的键值对 Set-Cookie: is_login=1; Path=/,随后访问的url都会在request请求头中携带这个设置的cookie值
删除cookie:服务器对请求的url(例如http://127.0.0.1:8000/app01/logout)设置了一个响应头的键值对 Set-Cookie is_login=""; expires=Thu, 01-Jan-1970 00:00:00 GMT; Max-Age=0; Path=/,随后访问的url的request请求头将没有cookie值
cookie的方法普通cookie ret是httpresponse对象设置:ret.set_cookie(key,value='',max_age=None path='/')字段解释:key:cookie键 value:cookie值 ,max_age:x秒 cookie超时时间 ,path:cookie生效的路径取cookie:request.COOKIES.get('键')
加密cookie
设置:ret.set_signed_cookie('is_login','abc',salt='xxxx')
salt:加密盐
取cookie:request.get_signed_cookie('is_login',salt='xxxx',default='',max_age=5)
删除cookie
#对浏览器中的cookie 键与值进行删除
ret.delete_cookie('is_login')
#实例def login_required(func):
def inner(request,*args,**kwargs):
# is_login = request.COOKIES.get('is_login')
is_login = request.get_signed_cookie('is_login',salt='xxxx',default='',max_age=5)
# 对于加密的来说,不加default参数会获取不到cookie的值而抛出异常KeyError at / app01 / publisher_list /
'is_login'
print(is_login)
if is_login !='abc':
returnurl=request.path_info
if returnurl:
return redirect((f'{reverse("login")}?return_url={returnurl}'))
return redirect(reverse('login'))
else:
ret = func(request,*args,**kwargs)
return ret
return inner
def login(request):
error_msg=''
if request.method == 'POST':
username = request.POST.get('username','')
password = request.POST.get('password','')
':
return_url=request.GET.get('return_url')
if return_url:
ret = redirect(return_url)
else:
ret = redirect(reverse('publisher'))
# ret.set_cookie('is_login','1',max_age=5,path='/app01/pub_list/')#不加密的cookie 超时时间5秒,cookie生效的路径
ret.set_signed_cookie('is_login','abc',salt='xxxx') #加密的cookie
return ret
error_msg = '用户名或密码错误'
return render(request,'login.html',{'error_msg':error_msg})
def logout(request): #删除cookie ret = redirect(reverse('login')) ret.delete_cookie('is_login') return ret
2>session
cookie的缺陷:本身最大支持4096的字节,本身的键值全都保存在客户端不安全
session:浏览器只保存服务器分发的sessionid,也就是键, session_data(值)保存在服务器中,没有长度限制.服务器根据sessionid识别用户和保持会话时间
session的设置#request.session.setdefault('is_login',1)
request.session['
request.session.set_expiry(5) #只删除浏览器的cookie 每次新连接的时候都使用新的cookie,数据库中的数据还保存,相当于一个新的客户端取连接
session的获取print(request.session)#<django.contrib.sessions.backends.db.SessionStore object at 0x00000169A9610390>is_login = request.session.get('is_login')#request.session['is_login']
session的删除 del request.session['is_login'] #浏览器和数据库session值都在,只是在程序逻辑中删除了KEY request.session.delete()#删除数据库session值,不删除浏览器的cookie(sessionid),但每次重新访问url的时候都会重新得到一个新的sessionid,数据库也会有此ID相对应的值 request.session.flush() #同时删除浏览器的cookie(sessionid)和数据库session值
session的配置SESSION_ENGINE = 'django.contrib.sessions.backends.db'SESSION_COOKIE_AGE = 1209600
4.django的中间件
1>django的请求流程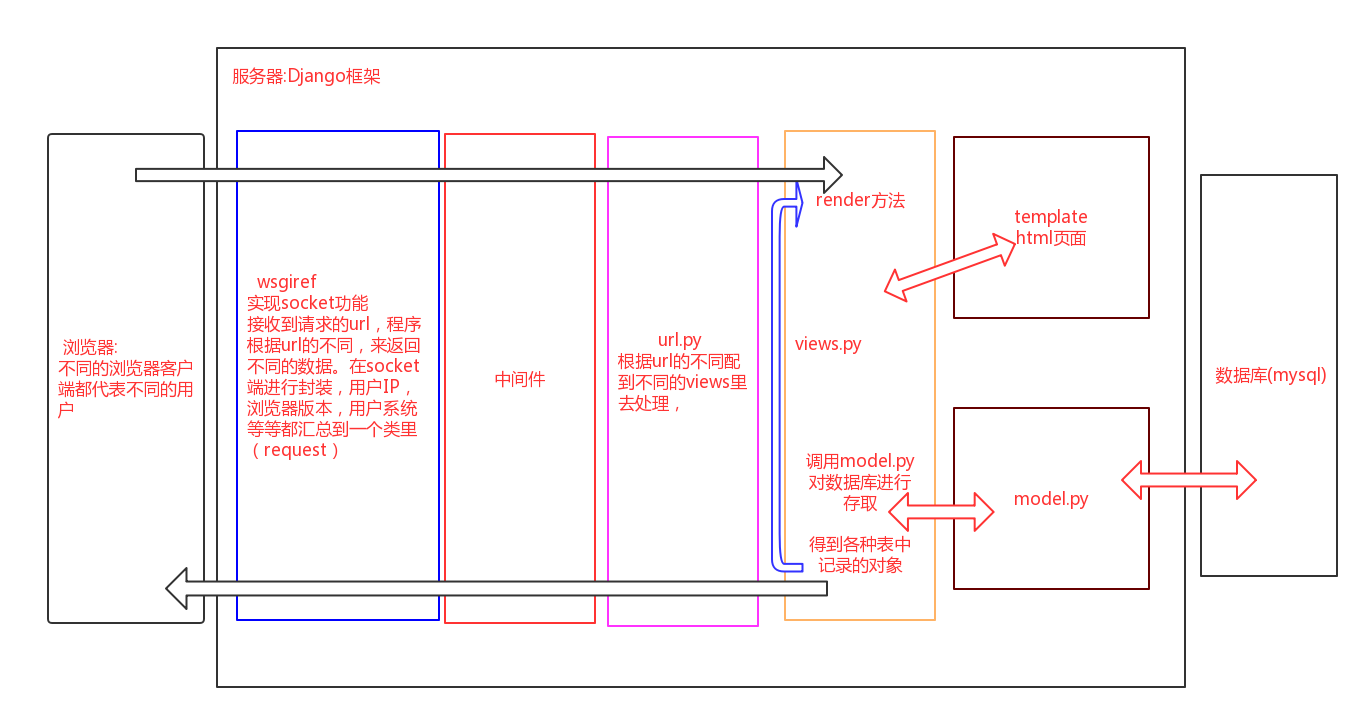
2>django中间件的5种方法
a.process_request
#注册自定义的中间件
#settings.py
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'app01.middlewares.mymiddleware.MD1',
'app01.middlewares.mymiddleware.MD2',
]
#mymiddleware.py
from django.utils.deprecation import MiddlewareMixin
from django.shortcuts import HttpResponse
class MD1(MiddlewareMixin):
def process_request(self,request):
print('MD1 reuqest内存地址',id(request))
print('MD1的process_request')
# return HttpResponse('MD1的process_request') 如果返回,后面的流程不执行了 包括MD2中的process_request
class MD2(MiddlewareMixin):
def process_request(self,request):
print('MD2的process_request')
# return HttpResponse('MD2的process_request')
#views.py
def index(request):
print('index request内存地址',id(request))
print('这是index视图')
return HttpResponse('视图index中的ok')
#执行时间
在视图函数执行之前
#参数
request(请求对象) 与视图中的request是一个对象
#执行顺序
按照settings中注册的顺序, 顺序执行
#返回值
正常流程:返回一个None
response对象,哪个process_request 只要return response对象之后 直接不执行后面的流程,按照注册顺序决定返回顺序
#无返回值的执行结果
'''
MD1 reuqest内存地址 1815873977760
MD1的process_request
MD2的process_request
index request内存地址 1815873977760
这是index视图
'''
#当MD1与MD2都有返回值时的执行结果'''
MD1 reuqest内存地址 2104042671576
MD1的process_reques
'''
#当MD2有返回值,MD1无返回值时的执行结果'''MD1 reuqest内存地址 2118239296984MD1的process_requestMD2的process_request
'''
b.process_response
class MD1(MiddlewareMixin):
def process_request(self,request):
# print('MD1 reuqest内存地址',id(request))
print('MD1的process_request')
# return HttpResponse('MD1的process_request')
def process_response(self,request,response):
print('MD1 response内存地址',id(response))
print('MD1的process_response')
return response
class MD2(MiddlewareMixin):
def process_request(self,request):
print('MD2的process_request')
# return HttpResponse('MD2的process_request')
def process_response(self,request,response):
print('MD2 response内存地址', id(response))
print('MD2的process_response')
return response
#执行时间
在视图函数执行之后
#参数
request(请求对象),与视图中的request时一个对象
response(响应对象):视图返回的响应对象
#执行顺序
按照注册的顺序 倒叙返回response对象
#返回值
response对象:必须返回
#正常流程的执行结果
'''
MD1的process_request
MD2的process_request
这是index视图
视图 2103546390848
MD2 response内存地址 2103546390848
MD2的process_response
MD1 response内存地址 2103546390848
MD1的process_response
'''
process_request与process_response流程图
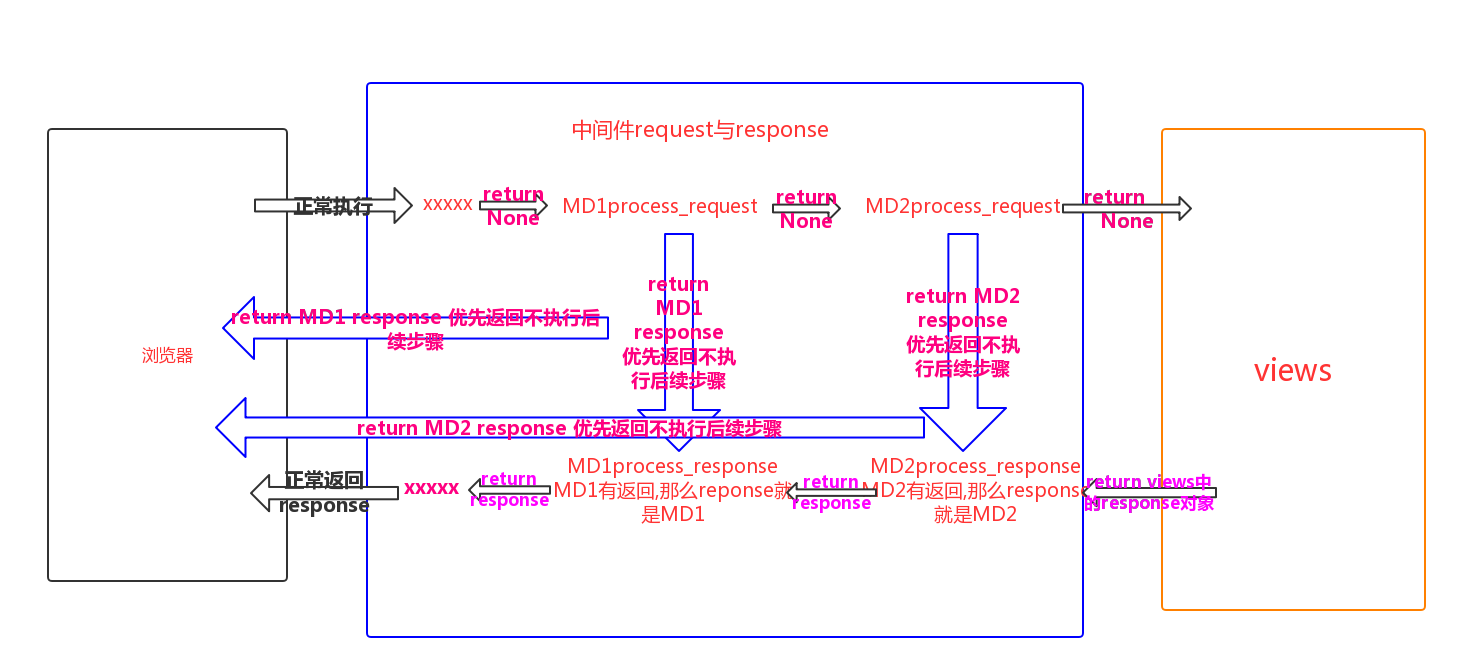
c.process_view
class MD1(MiddlewareMixin):
def process_request(self,request):
print('MD1的process_request')
def process_response(self,request,response):
print('MD1的process_response')
return response
def process_view(self,request,view_func,view_args,view_kwargs):
print(view_func)
print(view_args)
print(view_kwargs)
print('MD1的process_view')
# return HttpResponse('MD1 process view')
class MD2(MiddlewareMixin):
def process_request(self,request):
print('MD2的process_request')
def process_response(self,request,response):
print('MD2的process_response')
return response
def process_view(self,request,view_func,view_args,view_kwargs):
print('MD2的process_view')
#执行时间
在视图函数执行之前,在process_request之后,在路由匹配之后
#参数
request :
请求对象 和视图的参数是一个
view_func:视图函数
view_args:视图函数的位置参数
view_kwargs:视图函数的关键字参数
#执行顺序
按照中间件注册顺序,顺序执行
#返回值
None:正常流程
response对象 : 如果中间件中的process_view有return response对象,后续的process_view 以及视图都不执行, 直接按照process_response倒叙返回
#正常流程执行结果
'''
MD1的process_request
MD2的process_request
<function index at 0x000002A28153D840>
('1',)
{'xxx': 222}
MD1的process_view
MD2的process_view
这是index视图
MD2的process_response
MD1的process_response
'''
process_request,process_response与process_views流程图
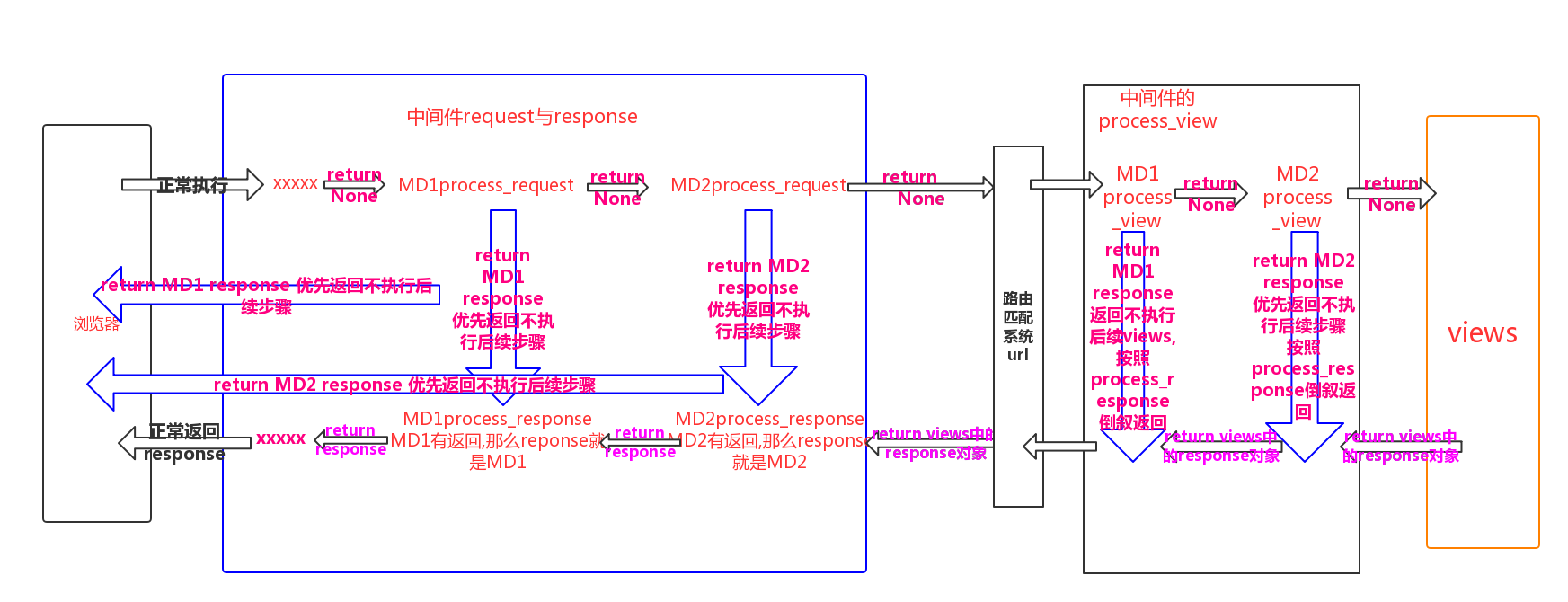
d.process_template_response
mymiddleware.py
class MD1(MiddlewareMixin):
def process_request(self,request):
print('MD1的process_request')
def process_response(self,request,response):
print('MD1的process_response')
return response
def process_view(self,request,view_func,view_args,view_kwargs):
print('MD1的process_view')
def process_template_response(self,request,response):
print('MD1的process_template_response')
return response
class MD2(MiddlewareMixin):
def process_request(self,request):
print('MD2的process_request')
def process_response(self,request,response):
print('MD2的process_response')
return response
def process_view(self,request,view_func,view_args,view_kwargs):
print('MD2的process_view')
def process_template_response(self, request, response):
print('MD2的process_template_response')
return response
views
def index(request,*args,**kwargs):
print('这是index视图')
ret = HttpResponse('视图index中的ok')
def pro_template():
return HttpResponse('这是xxxx')
ret.render =pro_template
return ret
#执行时间
在视图执行之后
触发条件:视图返回响应对象之后有一个render的方法
#参数
request(请求对象),与视图中的request时一个对象
response(响应对象):视图返回的响应对象
#执行顺序
按注册顺序倒叙执行
#返回值
必须返回response对象
#正常流程执行结果
'''
MD1的process_request
MD2的process_request
MD1的process_view
MD2的process_view
这是index视图
MD2的process_template_response
MD1的process_template_response
MD2的process_response
MD1的process_response
'''
e.process_exception
class MD1(MiddlewareMixin):
def process_request(self,request):
print('MD1的process_request')
def process_response(self,request,response):
print('MD1的process_response')
return response
def process_view(self,request,view_func,view_args,view_kwargs):
print('MD1的process_view')
def process_template_response(self,request,response):
print('MD1的process_template_response')
return response
def process_exception(self,request,exception):
print(exception)
print('MD1的process_exception')
class MD2(MiddlewareMixin):
def process_request(self,request):
print('MD2的process_request')
def process_response(self,request,response):
print('MD2的process_response')
return response
def process_view(self,request,view_func,view_args,view_kwargs):
print('MD2的process_view')
def process_template_response(self, request, response):
print('MD2的process_template_response')
return response
def process_exception(self, request, exception):
print(exception)
print('MD2的process_exception')
return HttpResponse(str(exception))
#执行时间
触发条件:视图层面有错误之后去执行
#参数
request(请求对象和视图的参数一样)
exception:错误对象
#执行顺序
按照中间件注册顺序倒叙执行
#返回值
None:正常报错
response对象:之后的中间件的process_excetion方法都不行了,之后倒叙执行所有中间件的process_response
#执行结果
'''
MD1的process_request
MD2的process_request
MD1的process_view
MD2的process_view
这是index视图
invalid literal for int() with base 10: 'aaa'
MD2的process_exception
MD2的process_response
MD1的process_response
'''
五种方法完整的中间件的流程图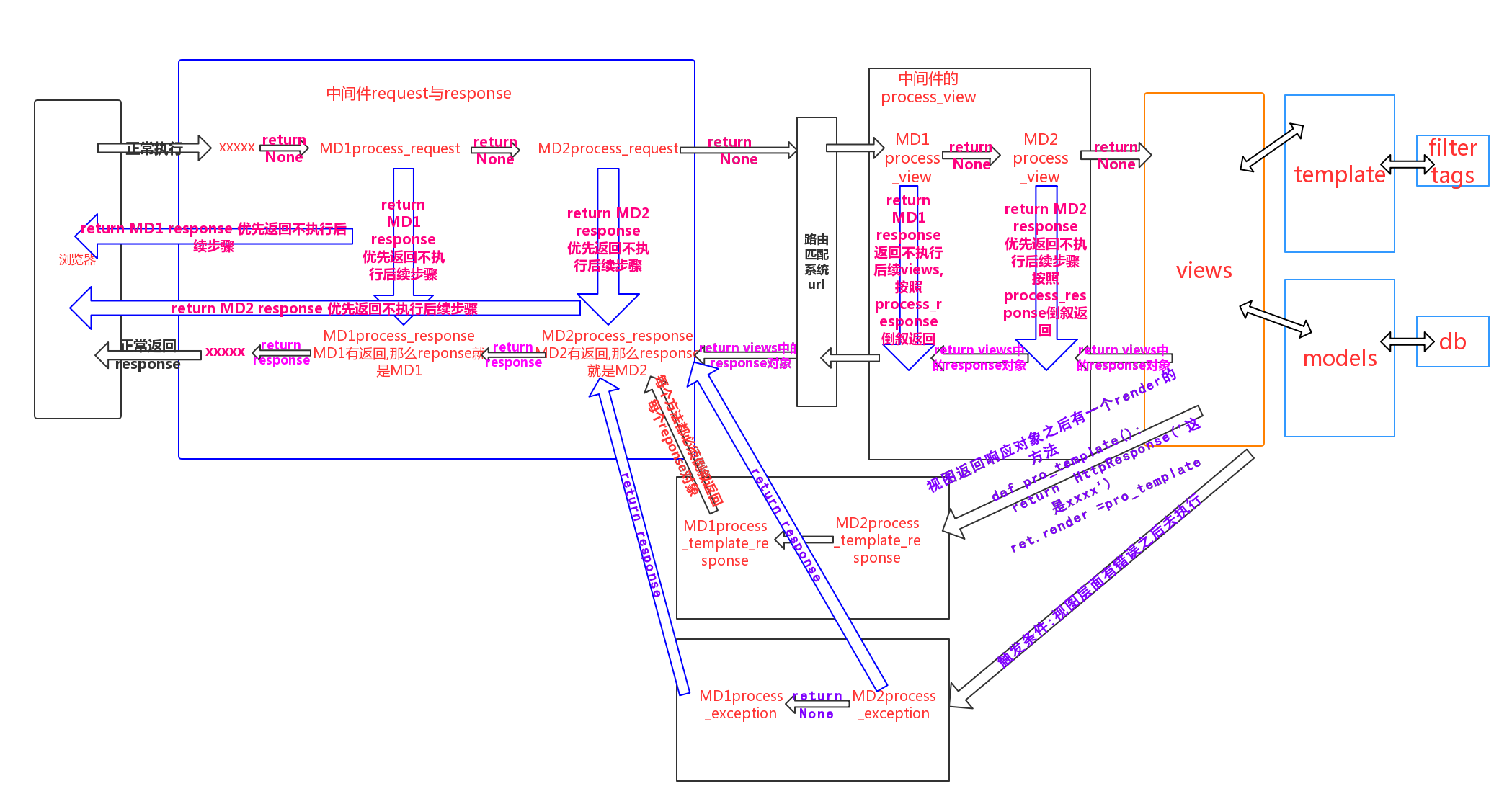
3>django的生命周期
'''
1.浏览器发起url请求,wsgi接收请求的url进行socket封装(用户IP,浏览器版本,用户系统等等汇总到一个request类中)
2.经过所有的中间件(5种方法都存在的情况):
a.顺序执行每个注册的中间件的process_request,正常流程返回None,一旦有某个process_request返回了response后面的流程都不走,
直接返回给浏览器.
b.路由系统匹配url之后,顺序执行每个process_view,正常流程返回None,一旦某个process_view返回了None,后面的流程都不走,
直接倒叙执行每个process_response,最后返回浏览器.
c.views视图与model(db处理)和template(filter和tags处理)进行交互之后,拿到对象用httpresponse对象返回给 process_reponse ,
倒叙执行每个process_response,最后返回给浏览器
d.如果视图返回对象之后有一个render方法,可以触发process_template_response,倒叙执行每个process_template_response,
必须返回一个response给process_response,倒叙执行每个process_response,最后返回给浏览器
f.如果视图层面有异常会触发process_exception且不会去执行process_template_response,倒叙执行每个process_exception,
一但有一个process_exception返回了response,后续的process_exception都不执行,直接返回给process_response去倒叙执行
每个process_response,最后返回给浏览器.
'''
Django-F,Q查询,Templatetags,session,中间件的更多相关文章
- Django ORM (四) annotate,F,Q 查询
annotate 可以通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合. from django.shortcuts import re ...
- Django框架08 /聚合查询、分组、F/Q查询、原生sql相关
Django框架08 /聚合查询.分组.F/Q查询.原生sql相关 目录 Django框架08 /聚合查询.分组.F/Q查询.原生sql相关 1. 聚合查询 2. 分组 3. F查询和Q查询 4. o ...
- Django day08 多表操作 (五) 聚合,分组查询 和 F,Q查询
一:聚合,分组查询 二:F, Q查询
- $Django 聚合函数、分组查询、F,Q查询、orm字段以及参数
一.聚合函数 from django.db.models import Avg,Sum,Max,Min,Count,F,Q #导入 # .查询图书的总价,平均价,最大价,最小价 ...
- Python数据库查询之组合条件查询-F&Q查询
F查询(取字段的值) 关于查询我们知道有filter( ) ,values( ) , get( ) ,exclude( ) ,如果是聚合分组,还会用到aggregate和annotate,甚至还有万能 ...
- 分组\聚合\F\Q查询
一.分组和聚合查询 1.aggregate(*args,**kwargs) 聚合函数 通过对QuerySet进行计算,返回一个聚合值的字典.aggregate()中每一个参数都指定一个包含在字典中的 ...
- python-day71--django多表双下划线查询及分组聚合及F/Q查询
#====================================双下划线的跨表查询===============# 前提 此时 related_name=bookList 属性查询: # 查 ...
- 聚合查询、分组查询、F&Q查询
一.聚合查询和分组查询 1.aggregate(*args, **kwargs): 通过对QuerySet进行计算,返回一个聚合值的字典.aggregate()中每个参数都指定一个包含在字典中的返回值 ...
- orm中的聚合函数,分组,F/Q查询,字段类,事务
目录 一.聚合函数 1. 基础语法 2. Max Min Sum Avg Count用法 (1) Max()/Min() (2)Avg() (3)Count() (4)聚合函数联用 二.分组查询 1. ...
随机推荐
- Google Chrome即将开始警告—停止支持Flash Player
Adobe 计划在 2020 年让 Flash Player 彻底退休,整个科技行业都在为这个关键时刻做准备,包括浏览器开发机构,Google 作为最主要的一员,试图尽可能顺利地完成 Flash Pl ...
- ionic3创建选项卡
html页面 <ion-content padding> <ion-segment [(ngModel)]="tabs"> <ion-segment- ...
- oracle篇 之 单行函数
一.分类 1.单行函数:需要处理的行数和返回结果的行数相等(单行进单行出) 2.多行函数(组函数):返回结果的行数少于要处理的行数(多行进单行出) 二.字符处理相关函数 1.lower:字符串转换成小 ...
- Monte Carlo Method(蒙特·卡罗方法)
0-故事: 蒙特卡罗方法是计算模拟的基础,其名字来源于世界著名的赌城——摩纳哥的蒙特卡罗. 蒙特卡罗一词来源于意大利语,是为了纪念王子摩纳哥查理三世.蒙特卡罗(MonteCarlo)虽然是个赌城,但很 ...
- Nginx从入门到实践(二)
静态资源web服务 静态资源类型 CDN CDN的基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问相对集中的地区或网络中,在用户访问网站时,利用全局负载技术将用户的访问指向距离最近的工 ...
- python学习日记(异常)
异常和错误 错误 1.语法错误 这种错误,根本过不了python解释器的语法检测,必须在程序执行前就改正 #语法错误示范一 if #语法错误示范二 def test: pass #语法错误示范三 pr ...
- .Net Core实践3 配置文件
环境 .netcore2.1 / vs2017 / win10 / centos7 在.netcore项目中读取配置文件,先添加应用程序配置文件App.config.这个是类库项目的配置文件名. Sy ...
- DFA确定有限状态自动机
DFA 在计算理论中,确定有限状态自动机或确定有限自动机(英语:deterministic finite automaton, DFA)是一个能实现状态转移的自动机.对于一个给定的属于该自动机的状态和 ...
- 第四十一篇-android studio 关闭自动保存功能
此方法不可用. 第一步:取消自动保存功能 File > Settings > Appearance & Behavior > System Settings > Syn ...
- 用js提取字符串中的某一段字符
String.prototype.getQuery = function(name){var reg = new RegExp("(^|&)"+ name +"= ...