【Spark篇】--Spark中的宽窄依赖和Stage的划分
一、前述
RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖。
Spark中的Stage其实就是一组并行的任务,任务是一个个的task 。
二、具体细节
- 窄依赖
父RDD和子RDD partition之间的关系是一对一的。或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的。不会有shuffle的产生。父RDD的一个分区去到子RDD的一个分区。
- 宽依赖
父RDD与子RDD partition之间的关系是一对多。会有shuffle的产生。父RDD的一个分区的数据去到子RDD的不同分区里面。
其实区分宽窄依赖主要就是看父RDD的一个Partition的流向,要是流向一个的话就是窄依赖,流向多个的话就是宽依赖。看图理解:
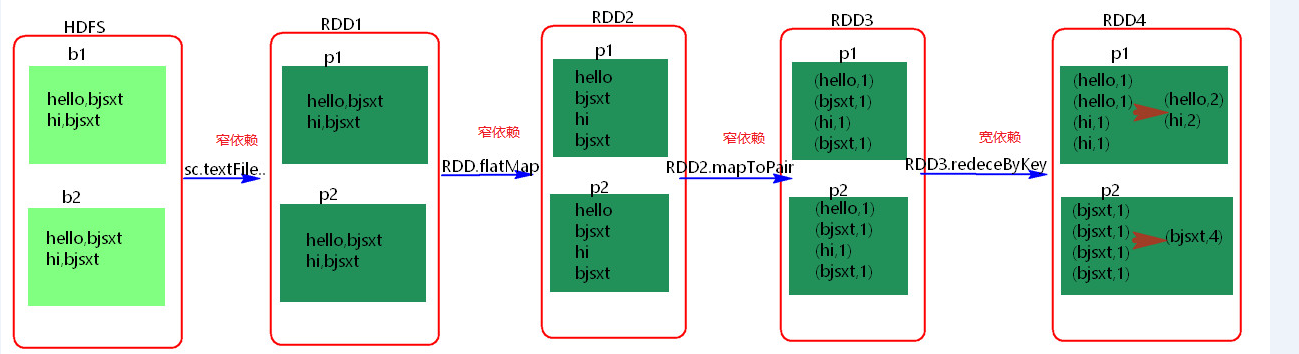
- Stage概念
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。 stage是由一组并行的task组成。
- stage切割规则
切割规则:从后往前,遇到宽依赖就切割stage。
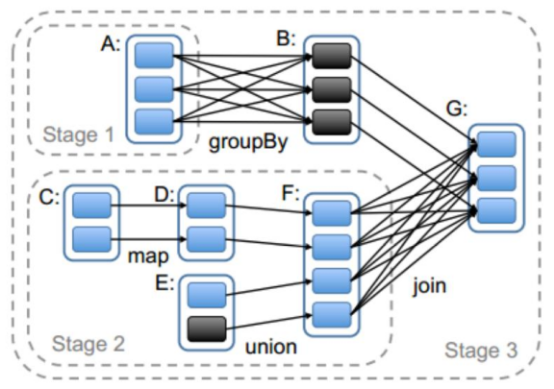
- stage计算模式
pipeline管道计算模式,pipeline只是一种计算思想,模式。

备注:图中几个理解点:
1、Spark的pipeLine的计算模式,相当于执行了一个高阶函数f3(f2(f1(textFile))) !+!+!=3 也就是来一条数据然后计算一条数据,把所有的逻辑走完,然后落地,准确的说一个task处理遗传分区的数据 因为跨过了不同的逻辑的分区。而MapReduce是 1+1=2,2+1=3的模式,也就是计算完落地,然后在计算,然后再落地到磁盘或内存,最后数据是落在计算节点上,按reduce的hash分区落地。所以这也是比Mapreduce快的原因,完全基于内存计算。
2、管道中的数据何时落地:shuffle write的时候,对RDD进行持久化的时候。
3. Stage的task并行度是由stage的最后一个RDD的分区数来决定的 。一般来说,一个partiotion对应一个task,但最后reduce的时候可以手动改变reduce的个数,也就是分区数,即改变了并行度。例如reduceByKey(XXX,3),GroupByKey(4),union由的分区数由前面的相加。
4.、如何提高stage的并行度:reduceBykey(xxx,numpartiotion),join(xxx,numpartiotion)
- 测试验证pipeline计算模式
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import java.util.Arrays object PipelineTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("pipeline");
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Array(1,2,3,4))
val rdd1 = rdd.map { x => {
println("map--------"+x)
x
}}
val rdd2 = rdd1.filter { x => {
println("fliter********"+x)
true
} }
rdd2.collect()
sc.stop()
}
}
可见是按照所有的逻辑将数据一条条的执行。!!!
【Spark篇】--Spark中的宽窄依赖和Stage的划分的更多相关文章
- Spark 宽窄依赖和stage的划分
窄依赖 父RDD和子RDD partition之间的关系是一对一的,或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的 ...
- 【转载】Spark学习——spark中的几个概念的理解及参数配置
首先是一张Spark的部署图: 节点类型有: 1. master 节点: 常驻master进程,负责管理全部worker节点.2. worker 节点: 常驻worker进程,负责管理executor ...
- Spark中文指南(入门篇)-Spark编程模型(一)
前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apache Spark简介 Spark的四种运行模式 Spark基于Standlone的运行流程 Spark ...
- 【原】Spark中Job如何划分为Stage
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Job的提交 http://www.cnblogs.com/yourarebest/p/5342404.html 1.Spark中 ...
- HBase读写的几种方式(二)spark篇
1. HBase读写的方式概况 主要分为: 纯Java API读写HBase的方式: Spark读写HBase的方式: Flink读写HBase的方式: HBase通过Phoenix读写的方式: 第一 ...
- spark在idea中本地如何运行?(处理问题NoSuchFieldException: SHUTDOWN_HOOK_PRIORITY)
spark在idea中本地如何运行? 前几天尝试使用idea在本地运行spark+scala的程序,出现了问题,http://www.cnblogs.com/yjf512/p/7662105.html ...
- Spark 2.x 中 Sort-Based Shuffle 产生的内幕
本课主题 Sorted-Based Shuffle 的诞生和介绍 Shuffle 中六大令人费解的问题 Sorted-Based Shuffle 的排序和源码鉴赏 Shuffle 在运行时的内存管理 ...
- Spark调研笔记第6篇 - Spark编程实战FAQ
本文主要记录我使用Spark以来遇到的一些典型问题及其解决的方法,希望对遇到相同问题的同学们有所帮助. 1. Spark环境或配置相关 Q: Sparkclient配置文件spark-defaults ...
- 【转帖】HBase读写的几种方式(二)spark篇
HBase读写的几种方式(二)spark篇 https://www.cnblogs.com/swordfall/p/10517177.html 分类: HBase undefined 1. HBase ...
随机推荐
- HangFire快速入门 分布式后端作业调度框架服务
安装 NuGet 上有几个可用的Hangfire 的软件包.如果在ASP.NET应用程序中安装HangFire,并使用Sql Server作为存储器,那么请在Package Manager Conso ...
- 蓝桥杯 穿越雷区(bfs)
题目描述 X星的坦克战车很奇怪,它必须交替地穿越正能量辐射区和负能量辐射区才能保持正常运转,否则将报废.某坦克需要从A区到B区去(A,B区本身是安全区,没有正能量或负能量特征),怎样走才能路径最短? ...
- String.length()和String.getBytes().length
1.字符与字节 抛出如下代码: public static void main(String[] args) { String str = "活出自己范儿"; System.out ...
- 8080端口被System占用
System是Windows页面内存管理进程,拥有0级优先权,没有它系统无法启动 就是说,System进程是无法关闭的,所以不要尝试去强行关闭,可能引起电脑异常查看是否是IIS占用的, 进入电脑控制面 ...
- 动态规划——Frog Jump
题目大意就是,给定一个数组,数组中数字从小到大排列,第一个元素一定是0,青蛙的初始位置就在0,后面依次从小到大排列,表示第几个石子,青蛙只有跳到最后一个石子上才算成功过河,而且青蛙第一次从0位置只能跳 ...
- fiddler 抓取 htts 失败
1.清除C:\Users\Administrator\AppData\Roaming\Microsoft\Crypto\RSA 目录下所有文件(首次安装fiddler请忽略) 2.清除电脑上的根证书, ...
- 数据分析——pandas
简介 import pandas as pd # 在数据挖掘前一个数据分析.筛选.清理的多功能工具 ''' pandas 可以读入excel.csv等文件:可以创建Series序列,DataFrame ...
- 编程菜鸟的日记-初学尝试编程-C++ Primer Plus 第6章编程练习9
#include <iostream> #include <fstream> #include <cstdlib> #include <string> ...
- react.JS基础
1.ReactDOM.render() React.render 是 React 的最基本方法,用于将模板转为 HTML 语言,并插入指定的 DOM 节点. <!DOCTYPE html> ...
- vue 登录跳转
前几次做登录处理,都是写一个公用方法,然后在对应的路由页面调用,即判断是不是处于登录状态,如果不是,就返回登录页面. let exit = (vm)=>{ let login = session ...