C#使用Selenium+PhantomJS抓取数据
手头项目需要抓取一个用js渲染出来的网站中的数据。使用常用的httpclient抓回来的页面是没有数据。上网百度了一下,大家推荐的方案是使用PhantomJS。PhantomJS是一个没有界面的webkit浏览器,能够和浏览器效果一致的使用js渲染页面。Selenium是一个web测试框架。使用Selenium来操作PhantomJS绝配。但是网上的例子多是Python的。无奈,下载了python按照教程搞了一下,卡在了Selenium的导入问题上。遂放弃,还是用自己惯用的c#吧,就不信c#上没有。经过半个小时的折腾,搞定(python折腾了一个小时)。记录下这篇博文,让我等搞c#的新手能用上PhantomJS。
第一步:打开visual studio 2017 新建一个控制台项目,打开nuget包管理器。
第二部:搜索Selenium,安装Selenium.WebDriver。注意:如果要使用代理的话最好安装3.0.0版本。

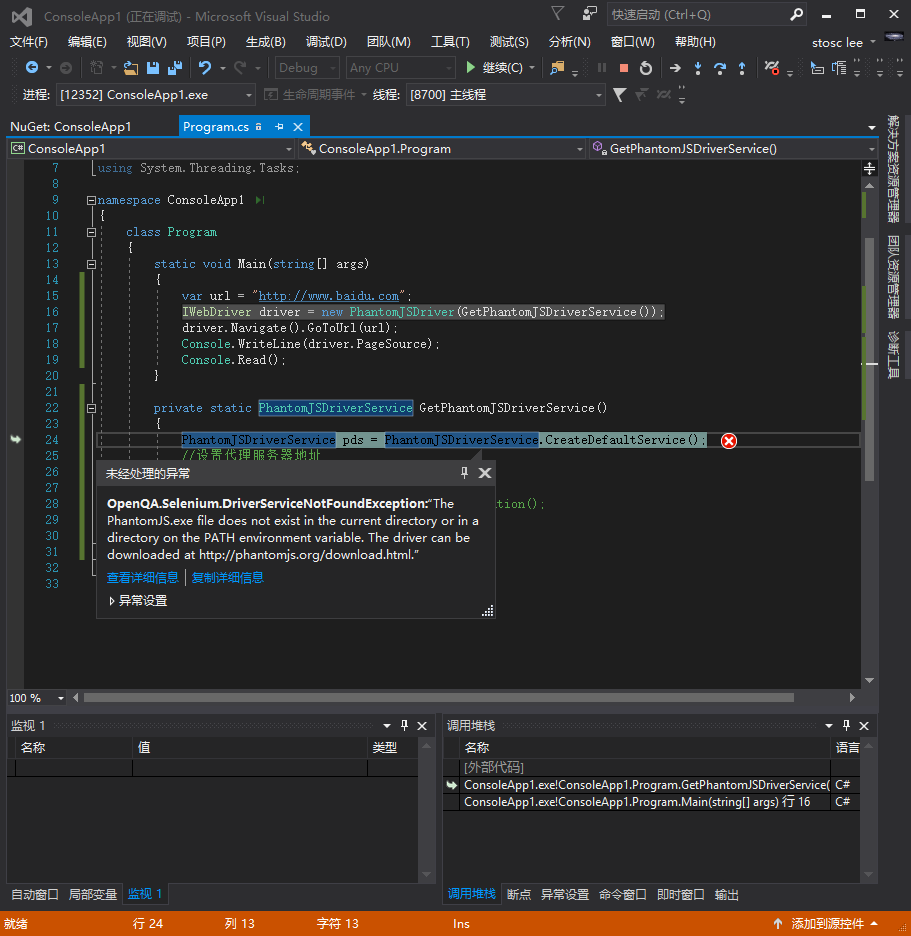
第三步:写下如下图所示的代码。但是执行的时候会报错。原因是找不到PhantomJS.exe。这时候可以去下载一个,也可以继续看第四步。
using OpenQA.Selenium;
using OpenQA.Selenium.PhantomJS;
using System;
namespace ConsoleApp1
{
class Program
{
static void Main(string[] args)
{
var url = "http://www.baidu.com";
IWebDriver driver = new PhantomJSDriver(GetPhantomJSDriverService());
driver.Navigate().GoToUrl(url);
Console.WriteLine(driver.PageSource);
Console.Read();
}
private static PhantomJSDriverService GetPhantomJSDriverService()
{
PhantomJSDriverService pds = PhantomJSDriverService.CreateDefaultService();
//设置代理服务器地址
//pds.Proxy = $"{ip}:{port}";
//设置代理服务器认证信息
//pds.ProxyAuthentication = GetProxyAuthorization();
return pds;
}
}
}
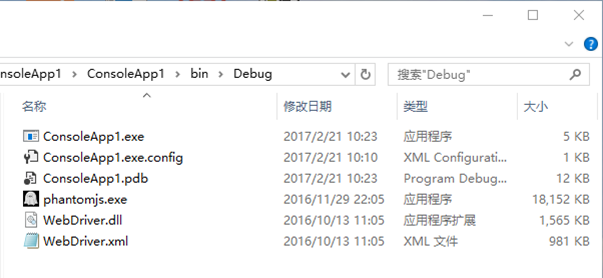
第四步:打开nuget安装Selenium.PhantomJS.WebDriver包。

第五步:运行。可以看到phantomjs.exe被自动下载了。
好了,这样就可以开始你的数据抓取大业了。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持脚本之家!
C#使用Selenium+PhantomJS抓取数据的更多相关文章
- [Python爬虫] 之九:Selenium +phantomjs抓取活动行中会议活动(单线程抓取)
思路是这样的,给一系列关键字:互联网电视:智能电视:数字:影音:家庭娱乐:节目:视听:版权:数据等.在活动行网站搜索页(http://www.huodongxing.com/search?city=% ...
- [Python爬虫] 之十二:Selenium +phantomjs抓取中的url编码问题
最近在抓取活动树网站 (http://www.huodongshu.com/html/find.html) 上数据时发现,在用搜索框输入中文后,点击搜索,phantomjs抓取数据怎么也抓取不到,但是 ...
- selenium+PhantomJS 抓取淘宝搜索商品
最近项目有些需求,抓取淘宝的搜索商品,抓取的品类还多.直接用selenium+PhantomJS 抓取淘宝搜索商品,快速完成. #-*- coding:utf-8 -*-__author__ =''i ...
- selenium+chrome抓取数据,运行js
某些特殊的网站需要用selenium来抓取数据,比如用js加密的,破解难度大的 selenium支持linux和win,前提是必须安装python3,环境配置好 抓取代码: #!/usr/bin/en ...
- [Python爬虫] 之八:Selenium +phantomjs抓取微博数据
基本思路:在登录状态下,打开首页,利用高级搜索框输入需要查询的条件,点击搜索链接进行搜索.如果数据有多页,每页数据是20条件,读取页数 然后循环页数,对每页数据进行抓取数据. 在实践过程中发现一个问题 ...
- [Python爬虫] 之十三:Selenium +phantomjs抓取活动树会议活动数据
抓取活动树网站中会议活动数据(http://www.huodongshu.com/html/index.html) 具体的思路是[Python爬虫] 之十一中抓取活动行网站的类似,都是用多线程来抓取, ...
- [Python爬虫] 之十四:Selenium +phantomjs抓取媒介360数据
具体代码如下: # coding=utf-8import osimport refrom selenium import webdriverimport selenium.webdriver.supp ...
- [Python爬虫] 之十一:Selenium +phantomjs抓取活动行中会议活动信息
一.介绍 本例子用Selenium +phantomjs爬取活动行(http://www.huodongxing.com/search?qs=数字&city=全国&pi=1)的资讯信息 ...
- [Python爬虫] 之十:Selenium +phantomjs抓取活动行中会议活动
一.介绍 本例子用Selenium +phantomjs爬取活动树(http://www.huodongshu.com/html/find_search.html?search_keyword=数字) ...
随机推荐
- CentOS 7 系统下 GitLab 搭建
参考地址:https://blog.csdn.net/t748588330/article/details/79915003 1. 安装:使用 GitLab 提供仓库在线安装 curl -sS htt ...
- Python总结(二)
学习一门语言,首先就要学习它的数据类型和语法.这里与JS进行对比学习. 1.数据类型 python的数据类型有:数字(int).浮点(float).字符串(str),列表(list).元组(tuple ...
- 【spring源码分析】IOC容器初始化(五)
前言:前几篇文章已经将BeanDefinition的加载过程大致分析完成,接下来继续分析其他过程. AbstractApplicationContext#refresh public void ref ...
- 【vue】使用vue+element搭建项目,Tree树形控件使用
1.依赖安装 本例中,使用render-content进行树节点内容的自定义,因此需要支持JSX语法.(见参考资料第3个) 在Git bash中运行一下指令 cnpm install\ babel-p ...
- Batch Normalization的解释
输入的标准化处理是对图片等输入信息进行标准化处理,使得所有输入的均值为0,方差为1 normalize = T.Normalize([0.485, 0.456, 0.406],[0.229, 0.22 ...
- easyUI的常见属性
datagrid (数据表格) $("#tg").datagrid({url:"TaskList",//请求的地址fit: false, //当true时设置他 ...
- 类ArrayList
什么是ArrayList类 Java提供了一个容器 java.util.ArrayList 集合类,他是大小可变的数组的实现,存储在内的数据称为元素.此类提供一些方法来操作内部存储的元素. Array ...
- vue学习初探
一.环境的搭建安装 VS Code vue开发环境的搭建 理解vue的脚手架 合适的cnpm版本
- Google SRE
SRE_百度百科 https://baike.baidu.com/item/SRE/1141123 我们离Google SRE还有多远? - 简书https://www.jianshu.com/p/6 ...
- Spark报错
1. Exception in thread "main" java.lang.OutOfMemoryError: Java heap space at com.mysql.jdb ...