论文阅读笔记“Attention-based Audio-Visual Fusion for Rubust Automatic Speech recognition”
关于论文的阅读笔记 论文的题目是“Attention-based Audio-Visual Fusion for Rubust Automatic Speech recognition”,翻译成中文为 基于注意力的视听融合技术实现鲁棒自动语音识别 (这是用谷歌翻译的。。。。。)
摘要
文章介绍提出了一种音-视融合方案,这种方案超越了简单的特征融合,可以实现两种模式的自动对齐,进而实现了不论在嘈杂还是安静环境下识别精度的提高。文章在TCD-TIMIT和LRS2数据集上进行了测试,其中这两个数据集是为了大规模连续语音识别设计的。
引言
主要是提出了两个问题 一、什么是合适的视觉特征来匹配音频中mfcc特征 二、使用什么样的融合特征的方法
3 方法
网络由一个序列编码器,序列解码器,和注意力机制三部分组成。编码器是基于RNN的,输入的是一系列特征向量,输出的是中间潜在表示(被称作memory)和一个表示序列潜在摘要的最终状态。解码器也是一个RNN,用序列摘要进行初始化,其中这个序列摘要预测重点的语言单元(比如:字)。因为在长输入序列中,编码过程会造成一定的损失,所以使用注意力机制是很合适的。关于注意力机制的介绍https://www.zhihu.com/question/68482809/answer/264632289 张俊林大佬做的解释我觉得已经可以了。


3.2输入
文章中的系统同时采用音频和视频输入。音频是整个句子的raw声波信号,视频输入是由对应于音频的视频帧构成,这些视频帧以讲述者的脸部为中心。文中使用OpenFace工具包来检测和对齐人脸,然后在唇部周围标记
3.3 输入预处理
音频信号输入 在22050hz的频率下再次采样,采样过程中可以在不同的信噪比下添加不同的北京噪音。文中计算了输入的对数级的频谱,选择了25ms的采样窗口和10ms的偏移,用于短时傅里叶变换的1024个频率区间,以及80Hz到11025Hz的频率范围,具有30个区间用于梅尔尺度扭曲。最后,我们扩展了对数梅尔特征的一阶和二阶导数,最终得到了每10ms90大小的特征。
视频信号输入 唇部区域是3通道的RGB图片,向下采样到36*36像素的大小。一个具有参差网络的CNN处理这个图片,得到每帧128个单元的特征向量。架构的详细情况在表1中显示
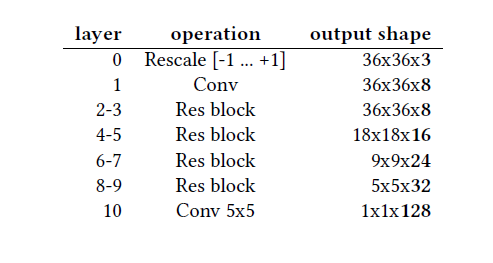
表1 CNN架构 除了最后一个,所有的卷积使用3*3的卷积核。残差块取自[1]的完整预活化变体(full preactivation variant)。
3.4 序列编码
音频和视频的特征序列在长度上是不同的,采样的频率分别是100FPS和30FPS。在训练示例中,序列也具有可变长度。文中使用两个LSTM网络来处理它们。文中收集两个LSTM的顶层(top-layer)输出序列和它们的最终状态分别作为编码记忆和序列摘要。
3.5 音视频融合策略(key part)
文中的前提是卷积双注意力机制,在s2s架构中使解码器负担过重。在单模型中,一个典型的解码器必须承担语言建模和声学建模的。添加另一种注意第二模态的注意机制需要解码器也学习输入模态之间的相关性。
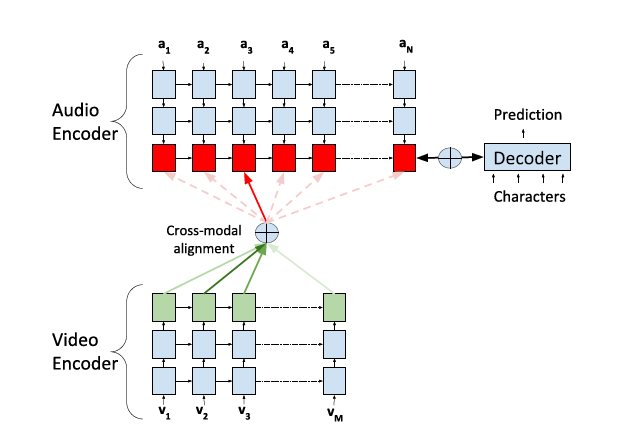
图1 提出的音视频融合策略 音频编码器的顶层单元(红)参加视频编码器的顶层输出(绿)。
在和视频输出融合之后,解码器仅收到了音频编码器的输出。为清楚起见,解码器未完全显示
文中致力于使音视频相关的模拟更加精确,并且和解码器完全的分离。所以,文中的策略是将一种模态与解码器分离,并在耦合模态的顶层引入补充注意机制,该机制参与解耦模态的编码存储器。解码器就像一个标准的单模注意力解码器一样,只接收最终状态和耦合编码器的顶层存储器。前面公式中提到的queries来自于音频解码器顶层的状态,values表示的是视频编码器存储。声学编码器的顶层不再仅表示声学的特征。它们是基于通过注意匹配的两种模态的相应高级特征的融合视听表示。这一层可以被单独的看作是一个操作声学和视频隐藏表示的更高级别的编码器(表1红色层)。
以下的直觉决定了文中给的选择。堆叠的RNN的顶层编码了更高级的特征,这些特征比低级特征更容易相关。这些提供从视觉和声音特征中提取出来的和语音有关的特征。另外,任何时候一个特征流被噪音损坏,那么它的编码可能会被另一个流的编码所纠正。
3.6 解码
解码器是一个单层的有256个单元的LSTM网络。文中使用四个注意力头(four attention head)来提高全局表现,同时仍然关注单个增强内存。解码器预测字符,通过在空白处拆分来推断字级结果
4 训练和评估步骤
文中训练了几个单模和双模s2s系统。单模系统只处理语音输入,输入的语音可能是干净的声音,a)混入白色高斯噪声 b) 咖啡厅噪声 c)街道的噪声。双模网络同时处理音频和视频输入。文中比较了论文提出的方法(AV Align),只有声音的系统和双注意力特征组合(AV Cat)。 在训练中,通过AMSGrad优化器直接优化交叉熵损失值。评估中,测量Levenshtein edit距离。
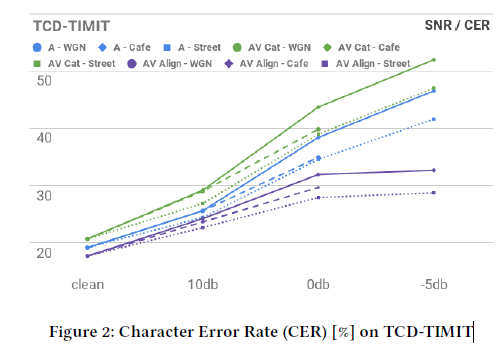
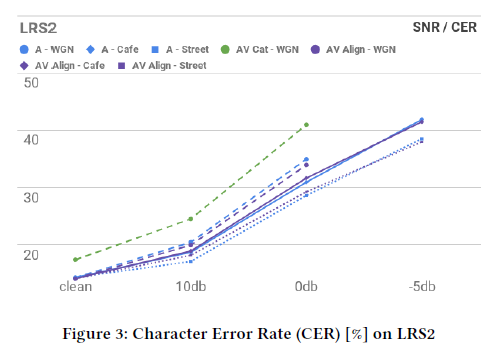
5 讨论
在TCD-TIMITdataset中,在背景噪音清洁的环境下,AV Align的效果比Audio Only方式效果有7%的相对提升,然而,AV Cat的效果比Audio Only方式效果相对下降了。在LRS2的dataset中,AV Align相对于Audio Only方式,在性能方面几乎没有提升。此外,我们在网络中观察到通过几个学习阶段的进展。首先,解码器形成了一个强大的学习正确词汇和短语的语言模型。随后,声音解码的影响增加并且网络学习了从字到声音的规则,像孩子一样过度概括,而且忘记了一些正确单词的拼写。更大规模的LRS2允许重新学习大量的字符,进而使得更加可靠的学习大量字符到声音的规则,它可能成为驱动训练和主管错误率的因素。文中接下来希望进行更长时间的训练,渡过这个阶段进而充分利用在LRS2上的视觉信息。
论文阅读笔记“Attention-based Audio-Visual Fusion for Rubust Automatic Speech recognition”的更多相关文章
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- [论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion
[论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 (1 ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
随机推荐
- 我的Android进阶之旅------> Android为TextView组件中显示的文本加入背景色
通过上一篇文章 我的Android进阶之旅------> Android在TextView中显示图片方法 (地址:http://blog.csdn.net/ouyang_peng/article ...
- 使用Service Bus Topic 实现简单的聊天室
创建Service Bus能够參照: https://azure.microsoft.com/en-gb/documentation/articles/service-bus-dotnet-how-t ...
- 微软ASP.NET网站部署指南(9):部署数据库更新
1. 综述 无论什么时候,程序都有可能像代码更新一样更新数据库.本章节你将进行数据库改动,測试.然后部署到測试环境和生产环境. 提醒:假设依据本章节所做的操作出现错误信息或一些功能不正常的话,请务必 ...
- 2015.04.28,外语,读书笔记-《Word Power Made Easy》 12 “如何奉承朋友” SESSION 36
1. the great and the small 拉丁词语animus(mind的意思),animus和另一个拉丁词根anima(life principle.soul.spirit),是许多单词 ...
- NAS配置Time Machine,在D-Link DNS-320上的配置笔记
今天打算把Time Machine备份的工作交给NAS,曾经是放在一块外置硬盘上的,尽管速度要比NAS快,可是每次插拔外接都有些麻烦.而NAS又具有实时在线.定时关机启动的功能.配合Time Mach ...
- EM无法登录,提示ORA-28001: the password has expired (DBD ERROR: OCISessionBegin)
--查看数据库目前的口令期限 sys@TESTDB11>select * from dba_profiles where profile = 'DEFAULT' and resource_nam ...
- C# Keywords - is
记录一下在日常开发过程中遇到的一些C# 基础编程的知识!希望以后能用的着.知识是在平常的开发过程中去学到的.只有用到了,你才能深入的理解它,并用好它. 本资料来源于:MSND下面是一些相关的code ...
- EF Code First 使用(一)
第一步:创建MVC5项目,添加数据库实体,建立上下文对象. 第二步:创建数据库和添加数据
- layui的多文件列表上传功能前端代码
html页面的代码(注意:引入layui相关的css): <div class="layui-upload" style="margin-left: 130px&q ...
- visio中如何取消跨线和去掉页边距
比较来说,写论文visio和inkscape都不可缺少. 比如visio跨线的问题,已经遇到过两次忘记了.这次截个图作为记录.其实就是在“设计”一栏里,把连接线里面的跨线显示的对勾去掉即可. *** ...