Spark Tachyon实战应用(配置启动环境、运行spark和运行mapreduce)
Tachyon实战应用
配置及启动环境
修改spark-env.sh
启动HDFS
启动Tachyon
Tachyon上运行Spark
添加core-site.xml
启动Spark集群
读取文件并保存
Tachyon运行MapReduce
修改core-site.xml
启动YARN
运行MapReduce例子
1 配置及启动环境
1.1.1 修改spark-env.sh
修改$SPARK_HOME/conf目录下spark-env.sh文件:
$cd /app/hadoop/spark-1.1./conf
$vi spark-env.sh
在该配置文件中添加如下内容:
export SPARK_CLASSPATH=/app/hadoop/tachyon-0.5./client/target/tachyon-client-0.5.-jar-with-dependencies.jar:$SPARK_CLASSPATH

1.1.2 启动HDFS
$cd /app/hadoop/hadoop-2.2./sbin
$./start-dfs.sh
1.1.3 启动Tachyon
在这里使用SudoMout参数,需要在启动过程中输入hadoop的密码,具体过程如下:
$cd /app/hadoop/tachyon-0.5./bin
$./tachyon-start.sh all SudoMount
1.2 Tachyon上运行Spark
1.2.1 添加core-site.xml
在Tachyon的官方文档说Hadoop1.X集群需要添加该配置文件(参见http://tachyon-project.org/documentation/Running-Spark-on-Tachyon.html),实际在Hadoop2.2.0集群测试的过程中发现也需要添加如下配置文件,否则无法识别以tachyon://开头的文件系统,具体操作是在$SPARK_HOME/conf目录下创建core-site.xml文件
$cd /app/hadoop/spark-1.1./conf
$touch core-site.xml
$vi core-site.xml
在该配置文件中添加如下内容:
<configuration>
<property>
<name>fs.tachyon.impl</name>
<value>tachyon.hadoop.TFS</value>
</property>
</configuration>

1.2.2 启动Spark集群
$cd /app/hadoop/spark-1.1./sbin
$./start-all.sh
1.2.3 读取文件并保存
第一步 准备测试数据文件
使用Tachyon命令行准备测试数据文件
$cd /app/hadoop/tachyon-0.5./bin
$./tachyon tfs copyFromLocal ../conf/tachyon-env.sh /tachyon-env.sh
$./tachyon tfs ls /

第二步 启动Spark-Shell
$cd /app/hadoop/spark-1.1./bin
$./spark-shell
第三步 对测试数据文件进行计数并另存
对前面放入到Tachyon文件系统的文件进行计数
scala>val s = sc.textFile("tachyon://hadoop1:19998/tachyon-env.sh")
scala>s.count()


把前面的测试文件另存为tachyon-env-bak.sh文件
scala>s.saveAsTextFile("tachyon://hadoop1:19998/tachyon-env-bak.sh")

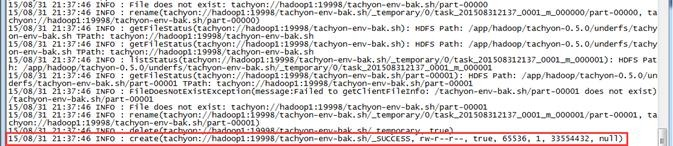
第四步 在Tachyon的UI界面查看
可以查看到该文件在Tachyon文件系统中保存成tahyon-env-bak.sh文件夹
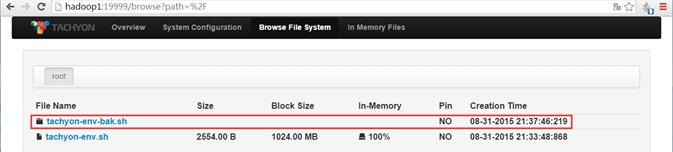
该文件夹中包含两个文件,分别为part-00000和part-00001:

其中tahyon-env-bak.sh/part-0001文件中内容如下:

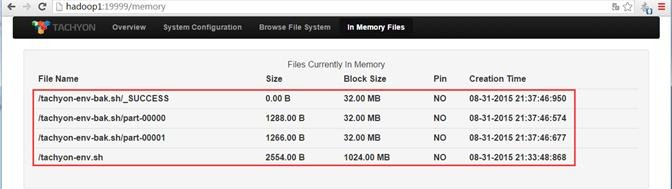
另外通过内存存在文件的监控页面可以观测到,这几个操作文件在内存中:
1.3 Tachyon运行MapReduce
1.3.1 修改core-site.xml
该配置文件为$Hadoop_HOME/conf目录下的core-site.xml文件
$cd /app/hadoop/hadoop-2.2./etc/hadoop
$vi core-site.xml
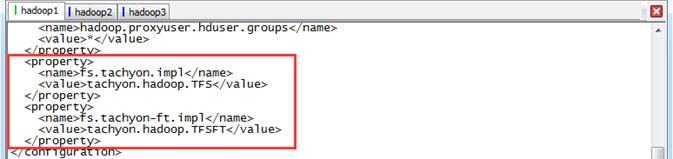
修改core-site.xml文件配置,添加如下配置项:
<property>
<name>fs.tachyon.impl</name>
<value>tachyon.hadoop.TFS</value>
</property>
<property>
<name>fs.tachyon-ft.impl</name>
<value>tachyon.hadoop.TFSFT</value>
</property>
1.3.2 启动YARN
$cd /app/hadoop/hadoop-2.2./sbin
$./start-yarn.sh
1.3.3 运行MapReduce例子
第一步 创建结果保存目录
$cd /app/hadoop/hadoop-2.2./bin
$./hadoop fs -mkdir /class10
第二步 运行MapReduce例子
$cd /app/hadoop/hadoop-2.2./bin
$./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2..jar wordcount -libjars $TACHYON_HOME/client/target/tachyon-client-0.5.-jar-with-dependencies.jar tachyon://hadoop1:19998/tachyon-env.sh hdfs://hadoop1:9000/class10/output
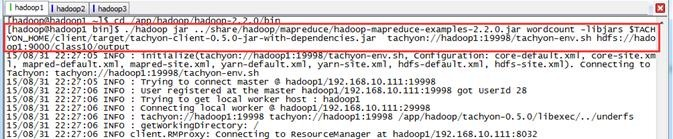

第三步 查看结果
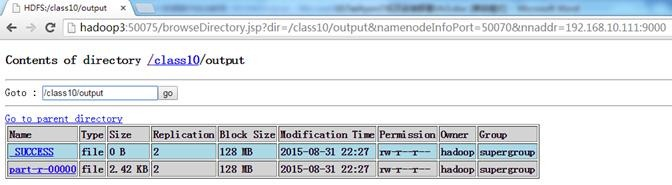
查看HDFS,可以看到在/class10中创建了output目录
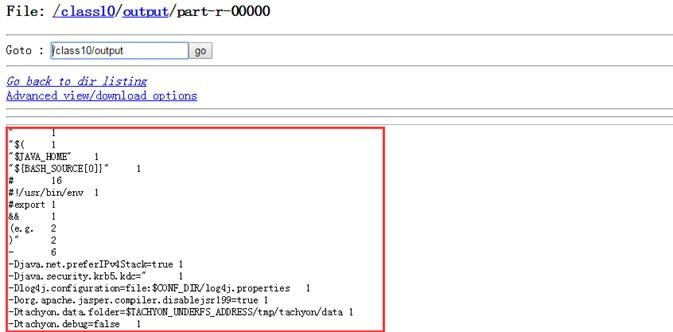
查看part-r-0000文件内容,为tachyon-env.sh单词计数
Spark Tachyon实战应用(配置启动环境、运行spark和运行mapreduce)的更多相关文章
- Spark Standalone Mode 多机启动 -- 分布式计算系统spark学习(二)(更新一键启动slavers)
捣鼓了一下,先来个手动挡吧.自动挡要设置ssh无密码登陆啥的,后面开搞. 一.手动多台机链接master 手动链接master其实上篇已经用过. 这里有两台机器: 10.60.215.41 启动mas ...
- Error while instantiating 'org.apache.spark.sql.hive.HiveSessionStateBuilder': —— windows 开发环境使用spark 无法访问hdfs 问题解决
## 错误: ## 解决方案: 下载 hadoop 的可执行tar包,解压放在windows 本地,并配置环境变量. 在 解压后的文件夹的bin目录下放入两个文件: winutils.exe, had ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- 《大数据Spark企业级实战 》
基本信息 作者: Spark亚太研究院 王家林 丛书名:决胜大数据时代Spark全系列书籍 出版社:电子工业出版社 ISBN:9787121247446 上架时间:2015-1-6 出版日期:20 ...
- Spark记录-spark-env.sh配置
环境变量 含义 SPARK_MASTER_IP master实例绑定的IP地址,例如,绑定到一个公网IP SPARK_MASTER_PORT mater实例绑定的端口(默认7077) SPARK_MA ...
- 在vscode成功配置Python环境
注意:如果您希望在Visual Studio Code中开始使用Python,请参阅教程.本文仅关注设置Python解释器/环境的各个方面. Python中的“环境”是Python程序运行的上下文.环 ...
- xampp本地服务器+HBuilder配置php环境
HBuilder配置PHP环境: 下载,运行HBuilder编辑器 打开右侧小窗口,点击设置图标—>设置web服务器—>外置web服务器 输入你想要浏 ...
- Spark master节点HA配置
Spark master节点HA配置 1.介绍 Spark HA配置需要借助于Zookeeper实现,因此需要先搭建ZooKeeper集群. 2.配置 2.1 修改所有节点的spark-evn.sh文 ...
随机推荐
- HTTP状态码:300\400\500 错误代码
一些常见的状态码为: 200 - 服务器成功返回网页 404 - 请求的网页不存在 503 - 服务不可用 详细分解: 1xx(临时响应) 表示临时响应并需要请求者继续执行操作的状态代码. 代码 说明 ...
- tload---显示系统负载
tload命令以图形化的方式输出当前系统的平均负载到指定的终端.假设不给予终端机编号,则会在执行tload指令的终端机显示负载情形. 语法 tload(选项)(参数) 选项 -s:指定闲时的刻度: - ...
- caioj 1077 动态规划入门(非常规DP1:筷子)
首先可以看出排序之后,最优解肯定是每一对都相邻才是最优的 那么我们就要找构成最优解的相邻组 设f[i][j]是前i个字符,k对的最小值 如果当前这个筷子不取的话,f[i][j] = f[i-1][j] ...
- 【Codeforces Round #423 (Div. 2) B】Black Square
[Link]:http://codeforces.com/contest/828/problem/B [Description] 给你一个n*m的格子; 里面包含B和W两种颜色的格子; 让你在这个格子 ...
- CodeForces 400A Inna and Choose Options
Inna and Choose Options Time Limit: 1000ms Memory Limit: 262144KB This problem will be judged on Cod ...
- 离线安装 Chrome
离线安装 Chrome 在这个帮助网页中最下面切换到中文 https://support.google.com/chrome/answer/95346 在网页的中上部点击 "离线安装 Chr ...
- vue4 属性 class style
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 简单缓存Cache
接口 interface ICache { /// <summary> /// 添加 /// </summary> /// <param name="key&q ...
- BZOJ 3781 莫队
思路:不能再裸的裸题-- //By SiriusRen #include <cmath> #include <cstdio> #include <algorithm> ...
- HBase的单节点集群详细启动步骤(分为Zookeeper自带还是外装)
伪分布模式下,如(weekend110)hbase-env.sh配置文档中的HBASE_MANAGES_ZK的默认值是true,它表示HBase使用自身自带的Zookeeper实例.但是,该实例只能为 ...