Scrapy——6 APP抓包—scrapy框架下载图片
Scrapy——6
怎样进行APP抓包? 1.连接网络
- 安装fiddler,并且进行配置:
Tools >> options >> connections >> 勾选 allow remote computers to connect
- 查看本机ip地址:
在cmd窗口中,输入 ipconfig ,查看 以太网 ,可以看到
IPv4 地址...............:192.168.0.104
这个192.168.*.***(192.168.0.104) 就是你的本机IP
- 确保手机连接了wifi,并且和电脑是在同一个局域网,
- 设置代理,在WiFi中长按连接的wifi选择设置代理

- 在手机中,打开浏览器,访问
http://10.209.143:1234
IP:是第二步查看到的ip地址,替换成你自己的IP
port:8888是你在fiddler中配置的
注意:有些浏览器会显示打不开,更换其他浏览器就可以了
怎样进行APP抓包? 2.访问网络

打开后点击最后的链接(光标处),进行证书安装就可以了
怎样进行APP抓包? 3.安装证书
- 安装 证书
部分手机可以直接点击 安装
部分手机需要 设置 >> wifi(或WLAN) >> 高级设置 >> 安装证书 >>
选中刚刚下载的 证书文件 FiddlerRoot.cer >> 确定
设置(Settings) >> 更多设置 >> 系统安全 >> 从存储设备安装
为证书命名 , 输入自己喜欢的名字,譬如 fiddler ,确定 , 显示 证书安装完成
安装完成后,在 设置(Settings) >> 更多设置 >> 系统安全 >> 信任的凭证 >>
系统和用户2个tab页 >> 用户 >> 可以查看到 DO_NOT_RUST_FiddlerRoot
PS: 不安装证书,抓取http的数据是没问题的,但是抓取不了https的数据
怎样进行APP抓包? 4.手机抓包
注意:
1、大部分app都可以直接抓包
2、少部分app没办法直接获取,需要 wireshark、反编译、脱壳 等方式去查找加密算法
3、app抓包一般都是抓取到服务器返回的json数据包
scrapy框架抓取APP豆果美食数据
手机打开豆果美食APP,同时打开fiddler,浏览你需要爬取的数据页面,然后就可以在fiddler中分析抓取的网络请求
因为手机数据一般都是json格式的数据,所以多注意网络请求的格式即可

很快就找到了我们需要的请求,接下来就用scrapy模拟请求解析数据
- 创建项目

- Local/Scrapy/douguo/douguo/items.py 设置需要保存的数据(作者、菜名、用时、难度、前言、图片链接)
import scrapy class DouguoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
auth = scrapy.Field()
cook_name = scrapy.Field()
cook_time = scrapy.Field()
cook_difficulty = scrapy.Field()
cook_story = scrapy.Field()
img = scrapy.Field() - Local/Scrapy/douguo/douguo/settings.py 设置爬虫协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False - 根据网络请求数据的方法,进行post请求,自行分析需要的请求头
- scrapy获取json数据,用的是response.body,再用json.dumps()转换
# -*- coding: utf-8 -*-
import scrapy
import json from ..items import DouguoItem class DouguoJiachangSpider(scrapy.Spider):
name = 'douguo_jiachang'
# allowed_domains = ['baidu.com']
# start_urls = ['http://api.douguo.net/recipe/v2/search/0/20']
page = 0 def start_requests(self):
base_url = 'http://api.douguo.net/recipe/v2/search/{}/20'
url = base_url.format(self.page)
data = {
'client': '',
'_session': '',
'keyword': '家常菜',
'order': '',
'_vs': ''
}
self.page += 20
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse) def parse(self, response):
date = json.loads(response.body.decode()) # 将json格式数据转换成字典
t = date.get('result').get('list')
for i in t:
douguo_item = DouguoItem()
douguo_item['auth'] = i.get('r').get('an')
douguo_item['cook_name'] = i.get('r').get('n')
douguo_item['cook_time'] = i.get('r').get('cook_time')
douguo_item['cook_difficulty'] = i.get('r').get('cook_difficulty')
douguo_item['cook_story'] = i.get('r').get('cookstory')
douguo_item['image_url'] = i.get('r').get('p') yield douguo_item
Local/Scrapy/douguo/douguo/spiders/douguojiachang.py 编写代码
结果:

怎样用scrapy框架下载图片
在前面的代码基础上继续更加功能
- Local/Scrapy/douguo/douguo/settings.py 设置图片下载路径,设置下载延迟,激活相应的图片下载管道,调整相应优先级
- 路径IMAGES_STORE是固定写法,后面的DOWNLOAD_DELAT也是,setting里的都是如此
- “.”表示当前路径,属于相对路径的写法,也可以写成绝对路径
- 管道优先级,数字越小,优先级越高
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'douguo.pipelines.DouguoPipeline': 229,
'douguo.pipelines.ImagePipline': 300,
}
.............
.............
.............
IMAGES_STORE = './images/'
DOWNLOAD_DELAY = 1 - Local/Scrapy/douguo/douguo/items.py 设置相应的图片下载链接和下载路径
import scrapy class DouguoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
auth = scrapy.Field()
cook_name = scrapy.Field()
cook_time = scrapy.Field()
cook_difficulty = scrapy.Field()
cook_story = scrapy.Field()
image_url = scrapy.Field()
image_path = scrapy.Field() - Local/Scrapy/douguo/douguo/pipelines.py 设置图片下载管
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem from .settings import IMAGES_STORE class DouguoPipeline(object):
def process_item(self, item, spider):
print(item)
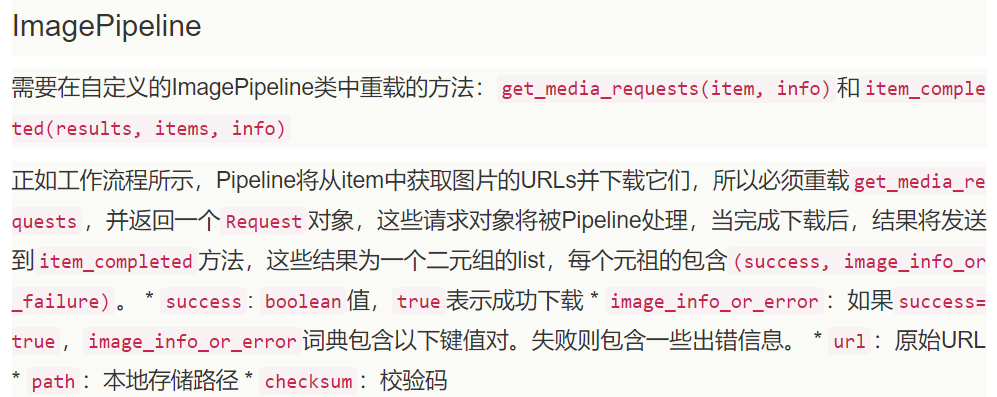
return item class ImagePipline(ImagesPipeline): def get_media_requests(self, item, info):
'''
对图片的地址生成Request请求进行下载
'''
yield scrapy.Request(url=item['image_url']) def item_completed(self, results, item, info):
'''
当图片下载完成之后,调用方法
'''
format = '.' + item['image_url'].split('.')[-1] # 设置图片格式
image_path = [x['path'] for ok, x in results if ok] # 获取图片的相对路径
old_path = IMAGES_STORE + image_path[0] # 老的路径
new_path = IMAGES_STORE + item['cook_name'] + format # 新的路径 路径+菜名+格式
item['image_path'] = new_path # 把新的路径传给item
try:
os.rename(old_path, new_path) # 改变下载的位置
except:
raise DropItem('Image Download Failed')
return item
结果:
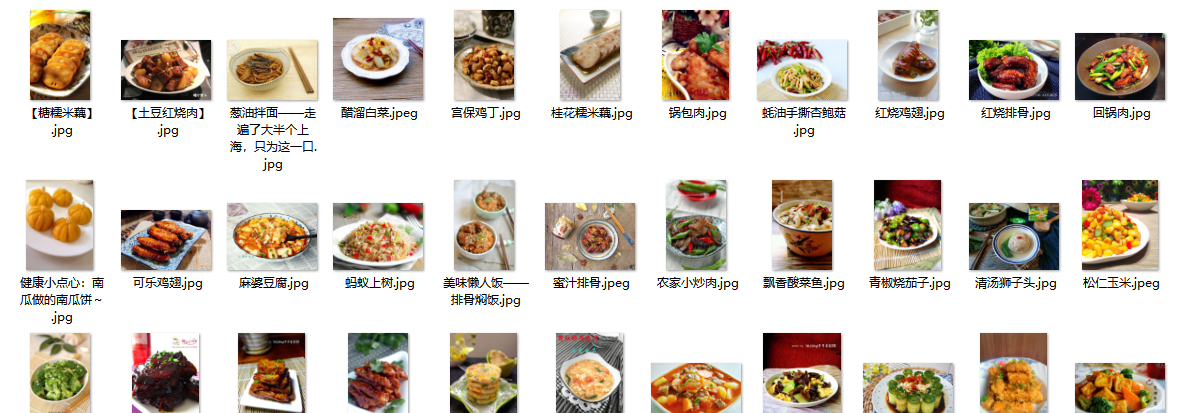
怎样用scrapy框架下载图片
ImagePipeline:
Scrapy用ImagesPipeline类提供一种方便的方式来下载和存储图片。需要PIL库支持。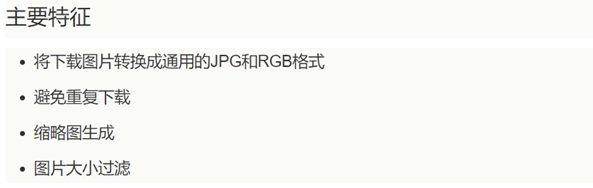

怎样用scrapy框架去下载斗鱼APP的图片?










常见问题


Scrapy——6 APP抓包—scrapy框架下载图片的更多相关文章
- scrapy之手机app抓包爬虫
手机App抓包爬虫 1. items.py class DouyuspiderItem(scrapy.Item): name = scrapy.Field()# 存储照片的名字 imagesUrls ...
- 【破解APP抓包限制】Xposed+JustTrustMe关闭SSL证书验证!
转载:https://www.jianshu.com/p/310d930dd62f 1 前言 这篇文章主要想解决的问题是,在对安卓手机APP抓包时,出现的HTTPS报文通过MITM代理后证书不被信任的 ...
- Fiddler和app抓包
1:请在“运行”,即下面这个地方输入certmgr.msc并回车,打开证书管理. 打开后,请点击操作--查找证书,如下所示: 然后输入“fiddler”查找所有相关证书,如下所示: 可以看到,我们找到 ...
- Fiddler 网页采集抓包利器__手机app抓包
用curl技术开发了一个微信文章聚合类产品,把抓取到的数据转换成json格式,并在android端调用json数据接口加以显示: 基于weiphp做了一个掌上头条插件,也是用的网页采集技术:和一个创业 ...
- APP 抓包-fiddler
App抓包原理 客户端向服务器发起HTTPS请求 抓包工具拦截客户端的请求,伪装成客户端向服务器进行请求 服务器向客户端(实际上是抓包工具)返回服务器的CA证书 抓包工具拦截服务器的响应,获取服务器证 ...
- 抓包工具fiddler下载配置(三):手机设置代理
前言 本篇仅讲解了手机端如何设置代理,是[抓包工具fiddler下载配置(一):下载/安装&信任证书]的后续文章,未下载安装抓包工具的需先参考文章[抓包工具fiddler下载配置(一):下 ...
- fiddler抓包+安卓机 完成手机app抓包的配置 遇到的一些问题
fiddler抓包+安卓模拟器完成手机app抓包的配置:fiddler抓包+雷电模拟器 完成手机app抓包的配置 其实在安卓真机上弄比在虚拟机上弄更麻烦一点,它们的步骤都差不多一样,就是在安卓真机上弄 ...
- Fiddler+雷电模拟器进行APP抓包
1.下载最新版Fiddler,强烈建议在官网下载:https://www.telerik.com/download/fiddler 2. 正常傻瓜式安装,下一步,下一步,安装完毕后,先不用急于打开软件 ...
- APP 抓包(应用层)
0x01 前言: app抓包是逆向协议的前提,也是一个爬虫工程师的基本要求,最近发现这块知识非常欠缺就抓紧补补了(我太菜了) 然后接下来是通过vpn将流量导出到抓包软件的方式,而不是通过wifi设置代 ...
随机推荐
- WebView播放H5课件时,锁屏解锁后,页面重新绘制的问题
难题描述:H5页面播放 ,锁屏,解锁后,重新加载了页面,三星不会出现(onpause onstop ,onresume),但在小米.魅族会调用 onpause onstop ondestroy,onr ...
- hdoj--2073--无限的路(数学规律)
无限的路 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Su ...
- js的时间展示
<script type="text/javascript">$(function() { //方法调用 showtime(); //默认加载首页 ...
- zb的生日-------搜索 和 动态规划
简单的贪心算法 : http://love-oriented.com/pack/P01.html 说实话 我是喜欢 动态规划的.......但是省赛迫在眉睫 , 只好先 学 搜索了 , 赶紧 ...
- 最大正方形 同luogu1387
这道题下面这么写就够了(n<=100)暴力,枚举 #include<bits/stdc++.h> #define ULL unsigned long long #define MAX ...
- BZOJ 3473
思路: CF原题 ZYF有题解 O(nlog^2n) //By SiriusRen #include <bits/stdc++.h> using namespace std; ; ]; i ...
- URI、URL、请求、响应、常见状态代码
URI:路径(统一资源标识符,包括本地地址和网络地址) URL是URI的一种子路径, URI范围比URL范围广. URL (Uniform Resource Locator,统一全球资源定位符): 通 ...
- 警告视图及操作表单在xcode7.0中的使用
警告视图(alert)及操作表单(action sheet)都用于向用户提供反馈.(模态视图) 操作表单:要求用户在两个以上选项之间做出选择.操作表单从屏幕底部出现,显示一系列按钮供用户选择.用户必须 ...
- (转)Vue 爬坑之路(三)—— 使用 vue-router 跳转页面
使用 Vue.js 做项目的时候,一个页面是由多个组件构成的,所以在跳转页面的时候,并不适合用传统的 href,于是 vue-router 应运而生. 官方文档: https://router.vue ...
- Android 从服务器获取时间戳转换为年月日
用JAVA相关类转换.代码如下: Calendar calendar = Calendar.getInstance(); calendar.setTimeInMillis(NumberUtils.ge ...