Spark SQL概念学习系列之Spark SQL基本原理
Spark SQL基本原理
1、Spark SQL模块划分
2、Spark SQL架构--catalyst设计图
3、Spark SQL运行架构
4、Hive兼容性
1、Spark SQL模块划分


Spark SQL模块划分为Core、caralyst、hive和hive- ThriftServer四大模块。
Spark SQL依然是读取数据进去,然后你可以执行sql操作,然后你还可以执行其他的结构化操作,不光仅仅是只能sql操作哈!这一点,很多人都没理解到位。
也有数据的输入和输出的工作。
比如,Spark SQL模块里的core模块,就是为了处理数据的输入输出。将查询结果输出成DataFrame。具体见上图。
Spark SQL模块里的catalyst模块。具体见上图。
Spark SQL模块里的hive模块,对hive数据的处理。具体见上图。
Spark SQL模块里的hive -ThriftServer模块,具体见上图。
2、Spark SQL架构--catalyst设计图(这里说Spark SQL模块里的catalyst模块!!)
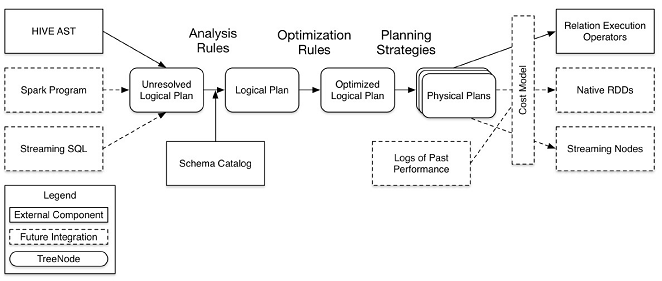
注意:图中的虚线部分是现在未实现或实现不完善的。
其中虚线部分是以后版本要实现的功能,实线部分是已经实现的功能。从上图看,catalyst主要的实现组件有:
sqlParse,完成sql语句的语法解析功能,目前只提供了一个简单的sql解析器;
Analyzer,主要完成绑定工作,将不同来源的Unresolved LogicalPlan和元数据(如hive metastore、Schema catalog)进行绑定,生成resolved LogicalPlan;
optimizer,对resolvedLogicalPlan进行优化,生成optimizedLogicalPlan(OptimizationRules,对resolvedLogicalPlan进行合并、列裁剪、过滤器下推等优化作业而转换成optimized LogicalPlan);
Planner,将LogicalPlan转换成PhysicalPlan;
CostModel,主要根据过去的性能统计数据,选择最佳的物理执行计划。
3、Spark SQL运行架构
类似于关系型数据库,SparkSQL也是语句也是由Projection(a1,a2,a3)、DataSource(tableA)、Filter(condition)组成,分别对应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Result-->Data Source-->Operation的次序来描述的。

执行SparkSQL语句顺序为:
1.对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范;
2.将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、DataSource等都是存在的话,就表示这个SQL语句是可以执行的;
3.一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize);
4.计划执行(Execute),按Operation-->DataSource-->Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
4、Hive兼容性
支持使用hql来写查询语句
兼容metastore
使用Hive的SerDes
对UDFs, UDAFs, UDTFs作了封装。
Spark SQL概念学习系列之Spark SQL基本原理的更多相关文章
- Spark SQL概念学习系列之Spark SQL概述
很多人一个误区,Spark SQL重点不是在SQL啊,而是在结构化数据处理! Spark SQL结构化数据处理 概要: 01 Spark SQL概述 02 Spark SQL基本原理 03 Spark ...
- Spark SQL概念学习系列之Spark SQL 架构分析(四)
Spark SQL 与传统 DBMS 的查询优化器 + 执行器的架构较为类似,只不过其执行器是在分布式环境中实现,并采用的 Spark 作为执行引擎. Spark SQL 的查询优化是Catalyst ...
- Spark SQL概念学习系列之分布式SQL引擎
不多说,直接上干货! parkSQL作为分布式查询引擎:两种方式 除了在Spark程序里使用Spark SQL,我们也可以把Spark SQL当作一个分布式查询引擎来使用,有以下两种使用方式: 1.T ...
- Spark RDD概念学习系列之Spark Hash Shuffle内幕彻底解密(二十)
本博文的主要内容: 1.Hash Shuffle彻底解密 2.Shuffle Pluggable解密 3.Sorted Shuffle解密 4.Shuffle性能优化 一:到底什么是Shuffle? ...
- Spark SQL概念学习系列之Spark SQL的简介(一)
Spark SQL提供在大数据上的SQL查询功能,类似于Shark在整个生态系统的角色,它们可以统称为SQL on Spark. 之前,Shark的查询编译和优化器依赖于Hive,使得Shark不得不 ...
- Spark SQL概念学习系列之Spark SQL 优化策略(五)
查询优化是传统数据库中最为重要的一环,这项技术在传统数据库中已经很成熟.除了查询优化, Spark SQL 在存储上也进行了优化,从以下几点查看 Spark SQL 的一些优化策略. (1)内存列式存 ...
- Spark SQL概念学习系列之Spark SQL入门
前言 第1章 为什么Spark SQL? 第2章 Spark SQL运行架构 第3章 Spark SQL组件之解析 第4章 深入了解Spark SQL运行计划 第5章 测试环境之搭建 第6章 ...
- Spark SQL概念学习系列之Spark SQL入门(八)
前言 第1章 为什么Spark SQL? 第2章 Spark SQL运行架构 第3章 Spark SQL组件之解析 第4章 深入了解Spark SQL运行计划 第5章 测试环境之搭建 第6章 ...
- Spark SQL概念学习系列之Spark生态之Spark SQL(七)
具体,见
随机推荐
- 清空/var/adm/wtmp 文件内容
清/var/adm/wtmp 文件内容 用于显示登录系统和重启机器的情况 /var/adm/wtmp文件过大. 可用du -sm /var/adm/wtmp查看 cat /dev/null>/v ...
- 学习《Python金融实战》中文版PDF+英文版PDF+源代码
学习python处理金融数据,建议学习<Python金融实战>,比较实用,只不过Yahoo财经的API改了,书里的方法不再有效要改一改,还有就是会有一些代码缩进小问题,总体上对金融分析很实 ...
- 学习参考《TensorFlow深度学习》高清中文版PDF+英文版PDF+源代码
我们知道,TensorFlow是比较流行的深度学习框架,除了看手册文档外,推荐大家看看<Tensorflow深度学习>,共分5方面内容:基础知识.关键模块.算法模型.内核揭秘.生态发展.前 ...
- 51nod 矩阵取数问题
一个N*N矩阵中有不同的正整数,经过这个格子,就能获得相应价值的奖励,从左上走到右下,只能向下向右走,求能够获得的最大价值. f[i][j] = max(f[i-1][j], f[i][j-1]) + ...
- PHP和js判断访问终端是否是微信浏览器
http://www.sucaihuo.com/php/813.html http://www.thinkphp.cn/extend/767.html http://blog.csdn.net/gf7 ...
- 检查类型是否包含iterator
- WebCollector爬取百度搜索引擎样例
使用WebCollector来爬取百度搜索引擎依照关键字搜索的结果页面,解析规则可能会随百度搜索的改版而失效. 代码例如以下: package com.wjd.baidukey.crawler; im ...
- Linux中 ps aux 命令
$ ps aux USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND root 11 100.0 0.0 0 16 ?? RL 4Dec09 ...
- poj Transferring Sylla(怎样高速的推断一个图是否是3—连通图,求割点,割边)
Transferring Sylla 首先.什么是k连通图? k连通图就是指至少去掉k个点使之不连通的图. 题目: 题目描写叙述的非常裸.就是给你一张图要求你推断这图是否是3-连通图. 算法分析: / ...
- CRSF Defense Using Content Injection Support By ModSecurity
The most advanced and imaginative use of the content injection feature is that devised byRyan C. Bar ...