Spark SQL概念学习系列之Spark SQL基本原理
Spark SQL基本原理
1、Spark SQL模块划分
2、Spark SQL架构--catalyst设计图
3、Spark SQL运行架构
4、Hive兼容性
1、Spark SQL模块划分


Spark SQL模块划分为Core、caralyst、hive和hive- ThriftServer四大模块。
Spark SQL依然是读取数据进去,然后你可以执行sql操作,然后你还可以执行其他的结构化操作,不光仅仅是只能sql操作哈!这一点,很多人都没理解到位。
也有数据的输入和输出的工作。
比如,Spark SQL模块里的core模块,就是为了处理数据的输入输出。将查询结果输出成DataFrame。具体见上图。
Spark SQL模块里的catalyst模块。具体见上图。
Spark SQL模块里的hive模块,对hive数据的处理。具体见上图。
Spark SQL模块里的hive -ThriftServer模块,具体见上图。
2、Spark SQL架构--catalyst设计图(这里说Spark SQL模块里的catalyst模块!!)
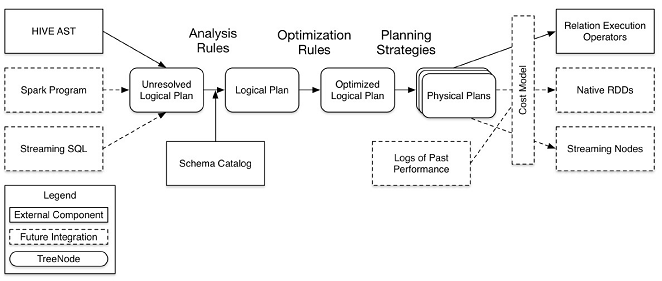
注意:图中的虚线部分是现在未实现或实现不完善的。
其中虚线部分是以后版本要实现的功能,实线部分是已经实现的功能。从上图看,catalyst主要的实现组件有:
sqlParse,完成sql语句的语法解析功能,目前只提供了一个简单的sql解析器;
Analyzer,主要完成绑定工作,将不同来源的Unresolved LogicalPlan和元数据(如hive metastore、Schema catalog)进行绑定,生成resolved LogicalPlan;
optimizer,对resolvedLogicalPlan进行优化,生成optimizedLogicalPlan(OptimizationRules,对resolvedLogicalPlan进行合并、列裁剪、过滤器下推等优化作业而转换成optimized LogicalPlan);
Planner,将LogicalPlan转换成PhysicalPlan;
CostModel,主要根据过去的性能统计数据,选择最佳的物理执行计划。
3、Spark SQL运行架构
类似于关系型数据库,SparkSQL也是语句也是由Projection(a1,a2,a3)、DataSource(tableA)、Filter(condition)组成,分别对应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Result-->Data Source-->Operation的次序来描述的。

执行SparkSQL语句顺序为:
1.对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范;
2.将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、DataSource等都是存在的话,就表示这个SQL语句是可以执行的;
3.一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize);
4.计划执行(Execute),按Operation-->DataSource-->Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
4、Hive兼容性
支持使用hql来写查询语句
兼容metastore
使用Hive的SerDes
对UDFs, UDAFs, UDTFs作了封装。
Spark SQL概念学习系列之Spark SQL基本原理的更多相关文章
- Spark SQL概念学习系列之Spark SQL概述
很多人一个误区,Spark SQL重点不是在SQL啊,而是在结构化数据处理! Spark SQL结构化数据处理 概要: 01 Spark SQL概述 02 Spark SQL基本原理 03 Spark ...
- Spark SQL概念学习系列之Spark SQL 架构分析(四)
Spark SQL 与传统 DBMS 的查询优化器 + 执行器的架构较为类似,只不过其执行器是在分布式环境中实现,并采用的 Spark 作为执行引擎. Spark SQL 的查询优化是Catalyst ...
- Spark SQL概念学习系列之分布式SQL引擎
不多说,直接上干货! parkSQL作为分布式查询引擎:两种方式 除了在Spark程序里使用Spark SQL,我们也可以把Spark SQL当作一个分布式查询引擎来使用,有以下两种使用方式: 1.T ...
- Spark RDD概念学习系列之Spark Hash Shuffle内幕彻底解密(二十)
本博文的主要内容: 1.Hash Shuffle彻底解密 2.Shuffle Pluggable解密 3.Sorted Shuffle解密 4.Shuffle性能优化 一:到底什么是Shuffle? ...
- Spark SQL概念学习系列之Spark SQL的简介(一)
Spark SQL提供在大数据上的SQL查询功能,类似于Shark在整个生态系统的角色,它们可以统称为SQL on Spark. 之前,Shark的查询编译和优化器依赖于Hive,使得Shark不得不 ...
- Spark SQL概念学习系列之Spark SQL 优化策略(五)
查询优化是传统数据库中最为重要的一环,这项技术在传统数据库中已经很成熟.除了查询优化, Spark SQL 在存储上也进行了优化,从以下几点查看 Spark SQL 的一些优化策略. (1)内存列式存 ...
- Spark SQL概念学习系列之Spark SQL入门
前言 第1章 为什么Spark SQL? 第2章 Spark SQL运行架构 第3章 Spark SQL组件之解析 第4章 深入了解Spark SQL运行计划 第5章 测试环境之搭建 第6章 ...
- Spark SQL概念学习系列之Spark SQL入门(八)
前言 第1章 为什么Spark SQL? 第2章 Spark SQL运行架构 第3章 Spark SQL组件之解析 第4章 深入了解Spark SQL运行计划 第5章 测试环境之搭建 第6章 ...
- Spark SQL概念学习系列之Spark生态之Spark SQL(七)
具体,见
随机推荐
- 请允许我成为你的夏季——shiro、jdbcInsertall
这两天总是觉得自己被关进了一个大笼子,日子拮据.生活不就是这样吗,一边觉得自己很差劲,一边又想成为一个更好的自己.可那又有什么办法呢,万物皆有裂痕,但那又怎样,那是光照进来的地方啊. 开始学习shir ...
- Hexo High一下以及压缩排版问题
背景介绍 集成Hight一下以及Gulp-html压缩之后出现的问题: High一下功能多次点击,会创建多个Audio对象,导致同时播放多次音乐,重音.解决办法:判断是否添加Audio对象,如果存在则 ...
- 记一次 Apache HUE 优化之因使用 Python 魔术方法而遇到的坑
最近的工作是基于 Apache HUE 做二次开发.刚接手 HUE 的代码的时候,内心是崩溃的:开源的代码,风格很多种, 代码比较杂乱; 虽是基于 Django 开发的,但是项目的结构改变很大; 很多 ...
- 小米开源便签Notes-源码研究(2)-定时提醒的便签
本篇讲述小米便签中的定时提醒功能. 便签,可以理解为一件事情,一项任务,有个定时提醒的功能,还是蛮不错的~ 小米便签定时功能,是当编辑便签的时候,有个菜单项,选了之后,就弹出一个"日 ...
- Swift学习笔记(2)--元组(Tuples)、Optional(可选值)、(Assertions)断言
1.Tuples(元组) 元组是多个值组合而成的复合值.元组中的值可以是任意类型,而且每一个元素的类型可以是不同的. 1>定义:使用()包含所有元素,用逗号分开,也可以对每个元素做命名 let ...
- /dev/shm和swap差别与联系
1.基本理论 /dev/shm这个文件是寄生虫,寄存在内存中 swap是暂时在硬盘中划分一个区域,把它作为内存使用 2.怎样查看 使用df -lh能够查看/dev/shm 使用free -m能够查看s ...
- POJ 2437 贪心+priority_queue
题意: 思路: 贪心 能不覆盖的就不盖 写得很乱 左闭右开的 temp //By SiriusRen #include <queue> #include <cstdio> #i ...
- 2011年度十大杰出IT博客获奖感言
2011年度十大杰出IT博客获奖感言 在各位评委.网友的支持下,我的博客从前50名中脱颖而出跻身10强,得到这个消息之后心中充满了喜悦.在这里要感谢51CTO为大家提供这样一个良好的展示平台. ...
- HDU 1576 A/B 数论水题
http://acm.hdu.edu.cn/showproblem.php?pid=1576 写了个ex_gcd的模板...太蠢导致推了很久的公式 这里推导一下: 因为 1 = BX + 9973Y ...
- 2017国家集训队作业[agc014d]Black and White Tree
2017国家集训队作业[agc014d]Black and White Tree 题意: 有一颗n个点的树,刚开始每个点都没有颜色.Alice和Bob会轮流对这棵树的一个点涂色,Alice涂白,B ...