3.orm之peewee
peewee是一款orm框架,为什么选择peewee,是因为它比较简单和Django比较类似,而且还有一个async-peewee,可以进行异步化。
如何定义model和生成表
'''
我们要定义两张表,一张商品,一张商品供应商。商品表里面有一个外键对应商品供应商
'''
import peewee
# 第一个参数是我们数据库的名字,其他的参数则跟pymysql一样
db = peewee.MySQLDatabase("satori", host="localhost", port=3306, user="root", password="zgghyys123")
# 定义供应商
class Supplier(peewee.Model):
# max_length:最大长度。verbose_name:注释信息。index:是否设置为索引
name = peewee.CharField(max_length=100, verbose_name="供应商名称", index=True)
address = peewee.CharField(max_length=200, verbose_name="供应商地址")
phone = peewee.CharField(max_length=11, verbose_name="联系电话")
class Meta:
# 和Django比较类似,绑定一个数据库实例
database = db
# 设置表名
table_name = "supplier"
class Goods(peewee.Model):
# 我们这里没有指定主键,那么会默认创建一个id列作为主键,如果SQLAlchemy的话必须要自己指定
name = peewee.CharField(max_length=100, verbose_name="商品名称", index=True)
click_num = peewee.IntegerField(default=0, verbose_name="点击数")
goods_num = peewee.IntegerField(default=0, verbose_name="库存")
price = peewee.FloatField(default=0.0, verbose_name="价格")
brief = peewee.TextField(verbose_name="商品简介")
# 绑定外键,和Django一样
# backref:反向引用。既然定义了外键,我们可以在Goods可以通过supplier访问到Supplier。
# 那么如何通过Supplier访问到Goods呢?那么就可以通过backref指定的goods来访问。这个SQLAlchemy也是一样的
# 但SQLAlchemy中,我们不仅要自己指定外键,并且定义反向引用的时候还要导入一个relationship
supplier = peewee.ForeignKeyField(Supplier, verbose_name="供应商", backref="goods")
class Meta:
database = db
table_name = "goods"
if __name__ == '__main__':
# 以上表便定义完成了,下面映射到数据库
# 直接使用db.create_tables即可,将要映射成表的模型放在列表里传进去
db.create_tables([Goods, Supplier])
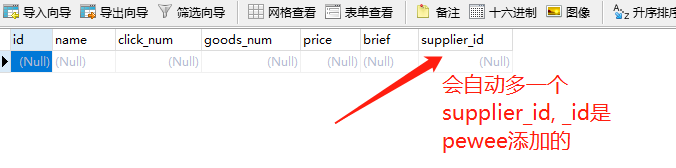
model的数据保存
# 导入模型
from model import Goods, Supplier
supplier_list = [
{
"name": "淘宝",
"address": "杭州",
"phone": "15548452158"
},
{
"name": "天猫",
"address": "杭州",
"phone": "15422584552"
},
{
"name": "京东",
"address": "北京",
"phone": "15424896324"
},
{
"name": "蘑菇街",
"address": "上海",
"phone": "15545221485"
}
]
goods_list = [
{
"name": "护舒宝",
"click_num": 100,
"goods_num": 666,
"price": 10,
"brief": "防侧漏",
"supplier": 1,
},
{
"name": "苏菲",
"click_num": 120,
"goods_num": 874,
"price": 8,
"brief": "双面侧翼,安心无忧",
"supplier": 2,
},
{
"name": "毓婷",
"click_num": 60,
"goods_num": 541,
"price": 30,
"brief": "有毓婷,放心爱",
"supplier": 3
},
{
"name": "冈本001",
"click_num": 5800,
"goods_num": 1500,
"price": 60,
"brief": "冈本超薄,给您最极致的体验",
"supplier": 4
}
]
def save_model():
# 添加单个元素直接这样添加即可, 然后使用save保存
'''
supplier = Supplier()
supplier.name = "淘宝"
supplier.address = "杭州"
supplier.phone = "15841259841"
supplier.save()
'''
# 添加多个元素的话
for data in supplier_list:
supplier = Supplier()
supplier.name = data["name"]
supplier.address = data["address"]
supplier.phone = data["phone"]
supplier.save()
for data in goods_list:
'''
也可以这样添加
goods = Goods(name=data["name"], click_num=data["click_num"], goods_num=data["goods_num"], price=data["price"], brief=data"brief"])
'''
# data里的key要和Goods模型定义的列名保持一致
goods = Goods(**data)
goods.save()
if __name__ == '__main__':
save_model()


peewee查询数据
from model import Goods
import peewee
# 获取某条数据,可以通过get方式查询,模型里面虽然没有定义id,但是表里面有,这个查找会映射到表里面去查找
good1 = Goods.get(Goods.id == 1)
# 虽然显示的是1,因为我们是按照id查找的,所以默认显示id
print(good1) # 1
# 但其实是一个<Model: Goods>
print(type(good1)) # <Model: Goods>
# 可以用这个good1查找其它属性
print(good1.name, " T_T ", good1.brief) # 护舒宝 T_T 防侧漏
# 同理也可以根据其它字段查询
good2 = Goods.get(Goods.name == "冈本001")
print(good2.brief) # 冈本超薄,给您最极致的体验
# 如果是通过id获取的话,那么有两个专门的方式
good3 = Goods.get_by_id(2)
print(good3) # 2
print(good3.name, " --- ", good3.brief) # 苏菲 --- 双面侧翼,安心无忧
# 还可以像列表一样传值,但是里面的值并不是索引,而是id
good4 = Goods[3]
print(good4, type(good4)) # 3 <Model: Goods>
print(good4.name, " --- ", good4.brief) # 毓婷 --- 有毓婷,放心爱
'''
为什么可以使用Goods[3]这种方式,看一下源码,会发现peewee.Model继承的父类有这么一段
def __getitem__(self, key):
return self.get_by_id(key)
实际上是实现了__getitem__这个魔法方法,而底层还是使用了get_by_id
'''
# 获取所有数据
'''
这句话等价于select * from goods,但是这是一个懒执行,类似于spark里面的transform,或者python里面的迭代器
像get,get_by_id等方法,使用之后会立即组成sql语句然后去查询,但是select返回的是<class 'peewee.ModelSelect'>这个类
会组成sql语句,但不会立即执行,而是当我们使用for循环迭代的时候,才会执行.
如何实现,实际上是底层实现了迭代协议
'''
good5 = Goods.select()
for good in good5:
# 即便在循环的时候,打印good默认还是打印id
print(good, type(good), good.name, good.click_num, good.brief)
'''
1 <Model: Goods> 护舒宝 100 防侧漏
2 <Model: Goods> 苏菲 120 双面侧翼,安心无忧
3 <Model: Goods> 毓婷 60 有毓婷,放心爱
4 <Model: Goods> 冈本001 5800 冈本超薄,给您最极致的体验
'''
# 此外如果我们想看执行的sql语句,可以使用good5.sql()进行查看
print(good5.sql()) # ('SELECT `t1`.`id`, `t1`.`name`, `t1`.`click_num`, `t1`.`goods_num`, `t1`.`price`, `t1`.`brief`, `t1`.`supplier_id` FROM `goods` AS `t1`', [])
# 关于select,如果我们不想选择所有的字段呢?那么可以传入想获取的字段名
good6 = Goods.select(Goods.name, Goods.price)
for good in good6:
# good虽然是<Model: Goods>,但是打印good默认还是打印id,但是我们查询的没有id只有name和price。
# 因此good为None,good.brief也为None
print(good, good.name, good.price, good.brief)
'''
None 护舒宝 10.0 None
None 苏菲 8.0 None
None 毓婷 30.0 None
None 冈本001 60.0 None
'''
# 根据条件获取
# select * from goods where price > 8.0
good7 = Goods.select().where(Goods.price > 8.0)
for good in good7:
print(good.name)
'''
护舒宝
毓婷
冈本001
'''
# select * from goods where price > 8.0 and price < 60.0 ,同理or的话就用|
good8 = Goods.select().where((Goods.price > 8.0) & (Goods.price < 60.0))
for good in good8:
print(good.name)
'''
护舒宝
毓婷
'''
# select * from goods where name is like "%宝"
good9 = Goods.select().where(Goods.name.contains("宝"))
'''
也可以这么写
good9 = Goods.select().where(Goods.name % "%宝")
'''
for good in good9:
print(good.name)
'''
护舒宝
'''
# 同理Goods.name.startswith和Goods.name.endswith也是支持的
# select * from goods where id in (1, 3)
good10 = Goods.select().where(Goods.id.in_([1, 3])) # 这里可以用in_,也可以用<<
'''
good10 = Goods.select().where(Goods.id << [1, 3])
'''
for good in good10:
print(good.name, good)
'''
护舒宝 1
毓婷 3
'''
# select * from goods where id between 1 and 3
good11 = Goods.select().where(Goods.id.between(1, 3))
for good in good11:
print(good.name, good.id)
'''
护舒宝 1
苏菲 2
毓婷 3
'''
# 还可以使用正则,注意这里的正则是mysql里面的正则,不是python里面的正则
'''
^a:以a开头的字符
a$:以a结尾的字符
.:匹配除了\n之外的任意字符
[....]:匹配包含在[....]里面的字符
[^....]:匹配不包含在[....]里面的字符
a|b|c:匹配a或b或c
*:重复零次或多次
?:重复零次或一次
+:重复一次或多次
需要注意:
1.like和regexp不要混用,like模式不支持正则,正则也不认识_,%
2.mysql里的正则没有贪婪非、贪婪匹配啥的
3.这里是mysql的正则,不是python的正则,所以不要出现\d,\w之类的
'''
good12 = Goods.select().where(Goods.name.regexp(r"宝$"))
for good in good12:
print(good, good.name)
'''
1 护舒宝
'''
# 忽略大小写,由于是中文,因此结果是一样的
good13 = Goods.select().where(Goods.name.iregexp(r"宝$"))
for good in good13:
print(good, good.name)
'''
1 护舒宝
'''
# 选出click_num大于goods_num的
good14 = Goods.select().where(Goods.click_num > Goods.goods_num)
for good in good14:
print(good.click_num, good.goods_num, good.name)
'''
5800 1500 冈本001
'''
# 选出click_num小于goods_num的
good14 = Goods.select().where(Goods.click_num < Goods.goods_num)
for good in good14:
print(good.click_num, good.goods_num, good.name)
'''
100 666 护舒宝
120 874 苏菲
60 541 毓婷
'''
# 排序
# select * from goods order by click_num desc
good15 = Goods.select().order_by(Goods.click_num.desc()) # 同理还有升序asc, 如果是输入字段名那么默认升序
for good in good15:
print(good.name, good.click_num)
'''
冈本001 5800
苏菲 120
护舒宝 100
毓婷 60
'''
# 这个orm是仿照Django的,而且Django支持使用+表示升序,-表示降序
good16 = Goods.select().order_by(+Goods.click_num)
for good in good16:
print(good.click_num, good.name)
'''
60 毓婷
100 护舒宝
120 苏菲
5800 冈本001
'''
good17 = Goods.select().order_by(-Goods.click_num)
for good in good17:
print(good.click_num, good.name)
'''
5800 冈本001
120 苏菲
100 护舒宝
60 毓婷
'''
# 使用count查询表中共有多少条数据
good18 = Goods.select().count()
print(good18)
# 分组,聚合
'''
from peewee import fn
fn.COUNT
fn.SUM
'''
# 分页
# 表示从第二行开始取两行数据,索引是从零开始的
good19 = Goods.select().group_by(Goods.price).paginate(1, 2)
for good in good19:
print(good.name, good.price)
'''
苏菲 8.0
护舒宝 10.0
'''
peewee更新数据和删除数据
from model import Goods
good1 = Goods.get_by_id(1)
print(good1.name, good1.price) # 护舒宝 10.0
# 获取id=1的记录,就像添加数据一样进行修改.
good1.price = 11.0
good1.save()
print(good1.name, good1.price) # 护舒宝 11.0
# 数据修改还可以使用update
good2 = Goods.get_by_id(4)
print(good2.name) # 冈本001
# 注意:update里面不需要模型了,直接输入字段名就可以了,因为在where中已经知道表名了
# 必须要execute才会生效
Goods.update(name="冈本002").where(Goods.id == 4).execute()
print(Goods.get_by_id(4).name) # 冈本002
# 但是
print(Goods.get_by_id(4).price) # 60.0
# 如果是这样更新的话, 右边必须加上模型名,否则报错
Goods.update(price=Goods.price+10).where(Goods.id == 4).execute()
print(Goods.get_by_id(4).price) # 70.0
# 删除一条记录
good3 = Goods.get_by_id(2)
# 这样获取到的id=2的记录便被删除了
good3.delete_instance()
try: # select方法,如果没数据,那么为空,但是get或者get_by_id如果获取不到数据会抛异常,GOODS.DoseNotExist
Goods.get_by_id(2)
except Exception:
import traceback
print(traceback.format_exc())
'''
Traceback (most recent call last):
File "D:/龙卷风/chapter1/update_delete_data.py", line 29, in <module>
Goods.get_by_id(2)
File "C:\python37\lib\site-packages\peewee.py", line 5629, in get_by_id
return cls.get(cls._meta.primary_key == pk)
File "C:\python37\lib\site-packages\peewee.py", line 5618, in get
return sq.get()
File "C:\python37\lib\site-packages\peewee.py", line 6021, in get
(clone.model, sql, params))
model.GoodsDoesNotExist: <Model: Goods> instance matching query does not exist:
SQL: SELECT `t1`.`id`, `t1`.`name`, `t1`.`click_num`, `t1`.`goods_num`, `t1`.`price`, `t1`.`brief`, `t1`.`supplier_id` FROM `goods` AS `t1` WHERE (`t1`.`id` = %s) LIMIT %s OFFSET %s
Params: [2, 1, 0]
'''
# delete from goods where price > 0.0 # 这个同样需要execute,否则是不会执行的,这下估计会把数据全部清空 Goods.delete().where(Goods.price > 0.0).execute()

peewee-async
首先还是要pip install --pre peewee-async,为什么要加上--pre,因为目前不支持python3.7,如果是python3.6的话直接安装即可
3.orm之peewee的更多相关文章
- orm之peewee
peewee是一款orm框架,为什么选择peewee,是因为它比较简单和Django比较类似,而且还有一个async-peewee,可以进行异步化. 如何定义model和生成表 ''' 我们要定义两张 ...
- python轻量级orm框架 peewee常用功能速查
peewee常用功能速查 peewee 简介 Peewee是一种简单而小的ORM.它有很少的(但富有表现力的)概念,使它易于学习和直观的使用. 常见orm数据库框架 Django ORM peewee ...
- Python:轻量级 ORM 框架 peewee 用法详解(二)——增删改查
说明:peewee 中有很多方法是延时执行的,需要调用 execute() 方法使其执行.下文中不再特意说明这个问题,大家看代码. 本文中代码样例所使用的 Person 模型如下: class Per ...
- Python初学者之网络爬虫(二)
声明:本文内容和涉及到的代码仅限于个人学习,任何人不得作为商业用途.转载请附上此文章地址 本篇文章Python初学者之网络爬虫的继续,最新代码已提交到https://github.com/octans ...
- Python框架、库以及软件资源汇总
转自:http://developer.51cto.com/art/201507/483510.htm 很多来自世界各地的程序员不求回报的写代码为别人造轮子.贡献代码.开发框架.开放源代码使得分散在世 ...
- [转载] ORMs under the hood
原文: http://www.vertabelo.com/blog/technical-articles/orms-under-the-hood It often happens that if so ...
- python模块 - 常用模块推荐
http://blog.csdn.net/pipisorry/article/details/47185795 python常用模块 压缩字符 当谈起压缩时我们通常想到文件,比如ZIP结构.在Pyth ...
- python 基础部分重点复习整理2
把这里的题目争取刷一遍 博客记录 python的ORM框架peewee SQLAlchemy psycopg2 Django 在1 的基础上,重点突出自己以前没注意的,做到精而不杂!!! Python ...
- python web需要了解哪些
1. socket.tcp/ip.http(cookie.session.token).https.ssl 2. wsgi:https://www.python.org/dev/peps/pep-33 ...
随机推荐
- NO4——并查集
int find(int x) { int r = x; while(father[r]!=r) r = father[r]; return r; } /* int find(int x) { if( ...
- weak_ptr打破环状引用
转自:http://blog.csdn.net/malong777/article/details/48974559 weak_ptr是一种不控制对象生存周期的智能指针,它指向一个shared_ptr ...
- Ext.Net中如何获取组件
我们在编写函数function的时候,常常需要用到页面上的组件.这时候就需要调用组件. 在Ext.net中,调用组件可以用.App.ID.(ID指的是想要调用的组件的ID). 例如: 我写一个函数需要 ...
- 从零开始配置Jenkins(二)——常见问题及排错思路
[前言] 一年多以前就听说Jenkins了,那时知道是它可以完成自动构建,感觉蛮强大的.后来,很多人都说它很恶心.最近,公司需要搭建新的服务器,小编就负责从头开始配置并且发布部署成功每一条线每一个项目 ...
- Ubuntu desktop基本操作
2018-03-03 11:48:52 ubuntu16 lts 更换源,系统安装的时候可以跳过语言包的安装 打开software & updates应用,Other software选项页, ...
- 时间戳转换成日期的js
在项目开发过程中,我们常常需要把时间戳转换成日期.下面这个是我一直使用的js方法,希望能帮助到有需要的朋友.大家如果有更好的方法,请多多指教! js代码如下: //时间戳转换成日期 function ...
- .Net com组件操作excel(不建议采用Com组件操作excel)
添加"Microsoft Office 12.0 Object Library" com组件 1 using System; using System.Data; using Sy ...
- JavaScript内置对象常用
Math 提供了数学中常用的属性和方法,使用时直接用Math.属性/方法,而不需要new一个Math对象 Date 使用Date对象来对日期和时间进行操作.使用时,必须用new创建一个实例 windo ...
- mysql yearweek修改开始日期
MySQL 的yearweek函数默认是从周日~周六,需求需要从周一到周日,看了MySQL的文档后,按照如下使用即可更改开始日期. http://dev.mysql.com/doc/refman/5. ...
- [Leetcode] remove element 删除元素
Given an array and a value, remove all instances of that value in place and return the new length. T ...