Elasticsearch 常用API
1. Elasticsearch 常用API
1.1.数据输入与输出
1.1.1.Elasticsearch 文档
#在Elasticsearch中,术语文档有着特定的含义。它是指最顶层或者根对象,这个根对象被序列化成JSON并存储到Elasticsearch中,指定了唯一ID。
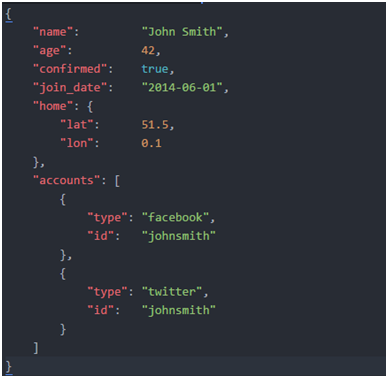
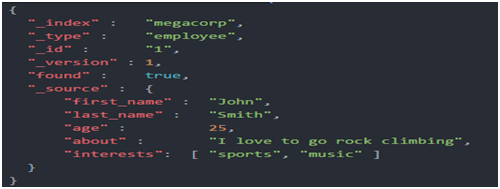
1.1.2.文档元数据
#一个文档不仅仅包含它的数据,也包含元数据——有关文档的信息。三个必须的元数据元素如下:
_index:文档在哪存放
_type:文档表示的对象类别
_id:文档唯一标识
1.1.3.索引文档
#自定义ID索引,使用Kibana中的Devtools工具,进行创建
#模板:
PUT /{index}/{type}/{id}
{
"field": "value",
...
}
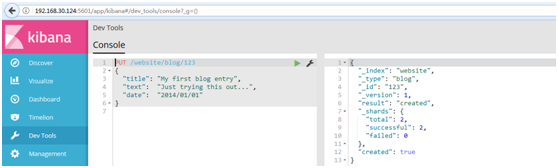
#例如:
PUT /website/blog/
{
"title": "My first blog entry",
"text": "Just trying this out...",
"date": "2014/01/01"
}
#结果如下:
1.1.4.取回文档
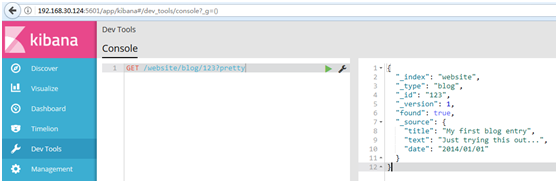
#使用Kibana中的Devtools工具,进行取回
#为了从Elasticsearch中检索出文档,我们仍然使用相同的_index , _type ,和_id,但是HTTP谓词更改为GET :
GET /website/blog/?pretty
#响应体包括目前已经熟悉了的元数据元素,再加上_source字段,这个字段包含我们索引数据时发送给Elasticsearch的原始JSON文档:
3.1.5.检查文档是否存在
#如果只想检查一个文档是否存在--根本不想关心内容--那么用HEAD方法来代替GET方法。HEAD请求没有返回体,只返回一个HTTP请求报头:
curl -i -XHEAD http://localhost:9200/website/blog/123
#如果文档存在,Elasticsearch将返回一个200 ok的状态码:

#若文档不存在,Elasticsearch将返回一个404 Not Found的状态码:
curl -i -XHEAD http://localhost:9200/website/blog/124

1.1.6.更新整个文档
#在Elasticsearch中文档是不可改变的,不能修改它们。相反,如果想要更新现有的文档,需要重建索引或者进行替换,我们可以使用相同的index API进行实现,在索引文档中已经进行了讨论。
#更新语句
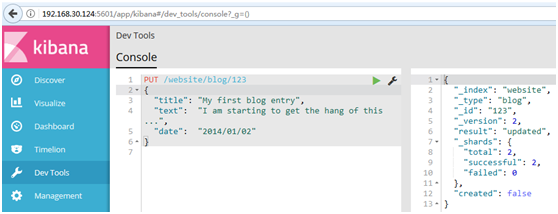
PUT /website/blog/
{
"title": "My first blog entry",
"text": "I am starting to get the hang of this...",
"date": "2014/01/02"
}
#在响应体中,我们能看到Elasticsearch已经增加了_version字段值:
# created标志设置成false,是因为相同的索引、类型和ID的文档已经存在。
1.1.7.创建新文档
#1.当我们索引一个文档,怎么确认我们正在创建一个完全新的文档,而不是覆盖现有的呢?
#请记住,_index、_type和_id的组合可以唯一标识一个文档。所以,确保创建一个新文档的最简单办法是,使用索引请求的POST形式让Elasticsearch自动生成唯一_id :

2.然而,如果已经有自己的_id,那么我们必须告诉Elasticsearch,只有在相同的_index、_type和_id不存在时才接受我们的索引请求。这里有两种方式,他们做的实际是相同的事情。使用哪种,取决于哪种使用起来更方便。
第一种方法使用op_type查询-字符串参数:

第二种方法是在URL末端使用/_create :

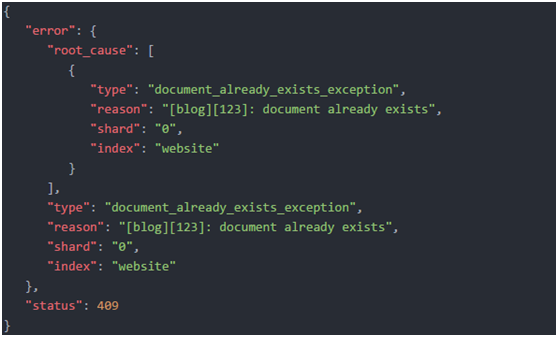
3.如果创建新文档的请求成功执行,Elasticsearch会返回元数据和一个201 Created的HTTP响应码。
另一方面,如果具有相同的_index、_type和_id的文档已经存在,Elasticsearch将会返回409 Conflict响应码,以及如下的错误信息:
1.1.8.删除文档
#删除文档的语法和我们所知道的规则相同,只是使用DELETE方法:
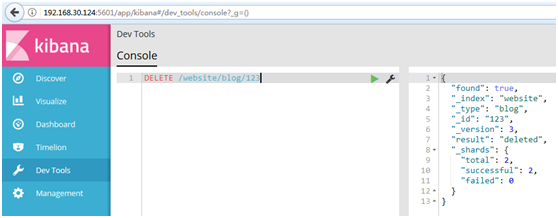
DELETE /website/blog/
#如果找到该文档,Elasticsearch将要返回一个200 ok的HTTP响应码,和一个类似以下结构的响应体。注意,字段_version值已经增加:
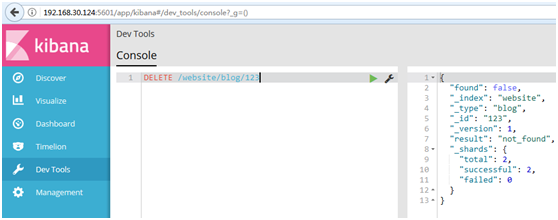
#如果文档没有找到,我们将得到404 Not Found的响应码和类似这样的响应体:
1.1.9.处理冲突(乐观并发控制)
#Elasticsearch利用_version号来确保应用中相互冲突的变更不会导致数据丢失。我们通过指定想要修改文档的version号来达到这个目的。如果该版本不是当前版本号,我们的请求将会失败。
#例如创建一个博客文章
PUT /website/blog//_create
{
"title": "My first blog entry",
"text": "Just trying this out..."
}
#响应体告诉我们,这个新创建的文档_version版本号是1。现在假设我们想编辑这个文档:我们加载其数据到web表单中,做一些修改,然后保存新的版本。
GET /website/blog/
#现在,当我们尝试通过重建文档的索引来保存修改,我们指定version为我们的修改会被应用的版本:
PUT /website/blog/?version=
{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}
#我们想这个在我们索引中的文档只有现在的_version为1时,本次更新才能成功
#此请求成功,并且响应体告诉我们_version已经递增到2:
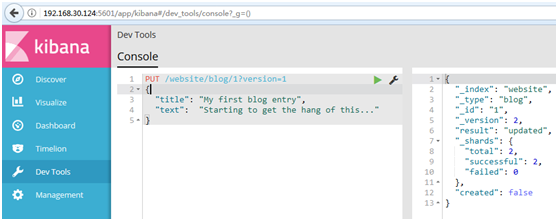
#然而,如果我们重新运行相同的索引请求,仍然指定version=1,Elasticsearch返回409 Conflict HTTP响应码,和一个如下所示的响应体:
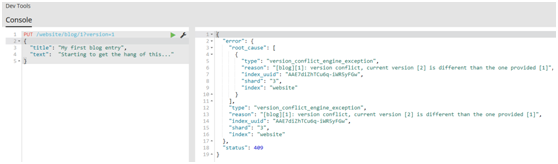
1.1.10.文档部分更新
#get文档
GET /website/blog/
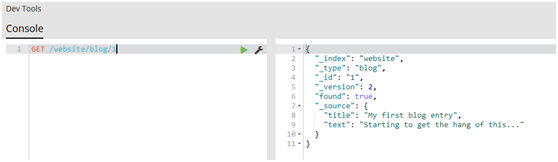
#update请求最简单的一种形式是接收文档的一部分作为doc的参数,它只是与现有的文档进行合并。对象被合并到一起,覆盖现有的字段,增加新的字段。例如,我们增加字段tags和views到我们的博客文章,如下所示
POST /website/blog//_update
{
"doc" : {
"tags" : [ "testing" ],
"views":
}
}
#再次get文档
GET /website/blog/
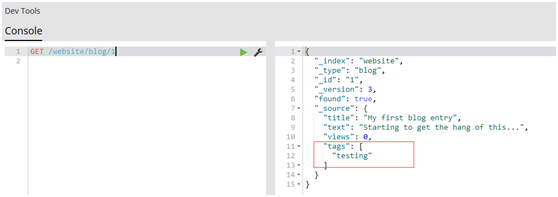
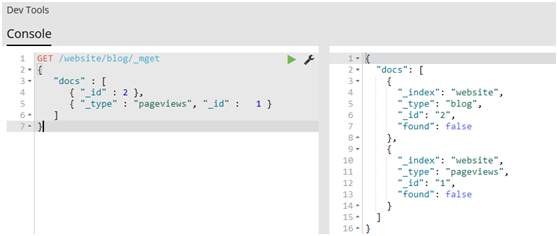
1.1.11.取回多个文档
#Elasticsearch的速度已经很快了,但甚至能更快。将多个请求合并成一个,避免单独处理每个请求花费的网络时延和开销。如果你需要从Elasticsearch检索很多文档,那么使用multi-get或者mget API来将这些检索请求放在一个请求中,将比逐个文档请求更快地检索到全部文档。
#mget API要求有一个docs数组作为参数,每个元素包含需要检索文档的元数据,包括_index、_type和_id。如果你想检索一个或者多个特定的字段,那么你可以通过_source参数来指定这些字段的名字
GET /_mget
{
"docs" : [
{
"_index" : "website",
"_type" : "blog",
"_id" :
},
{
"_index" : "website",
"_type" : "pageviews",
"_id" : ,
"_source": "views"
}
]
}

#如果想检索的数据都在相同的_index中(甚至相同的_type中),则可以在URL中指定默认的/_index或者默认的/_index/_type。
#你仍然可以通过单独请求覆盖这些值:
1.1.12.批量操作(代价较小)
#与mget可以使我们一次取回多个文档同样的方式,bulk API允许在单个步骤中进行多次create、index、update或delete请求。如果你需要索引一个数据流比如日志事件,它可以排队和索引数百或数千批次。
#bulk与其他的请求体格式稍有不同,如下所示:
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
...
#例如,一个delete请求看起来是这样的:
{ "delete": { "_index": "website", "_type": "blog", "_id": "" }}
#request body行由文档的_source本身组成--文档包含的字段和值。它是index和create操作所必需的,这是有道理的:你必须提供文档以索引。
它也是update操作所必需的,并且应该包含你传递给update API的相同请求体:doc、upsert、script等等。删除操作不需要request body行。
{ "create": { "_index": "website", "_type": "blog", "_id": "" }}
{ "title": "My first blog post" }
#如果不指定_id,将会自动生成一个ID:
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
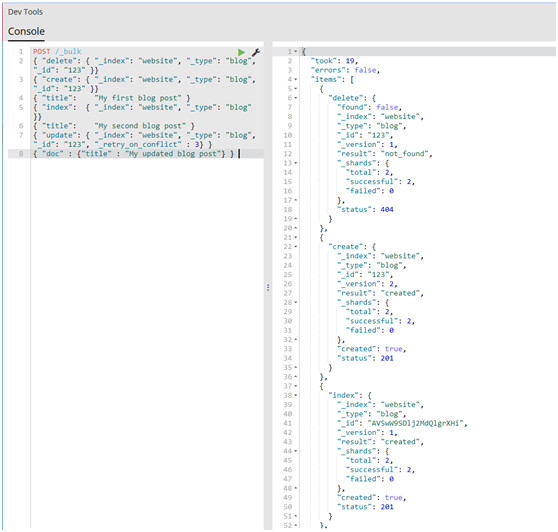
#为了把所有的操作组合在一起,一个完整的bulk请求有以下形式:
POST /_bulk
{ "delete": { "_index": "website", "_type": "blog", "_id": "" }}
{ "create": { "_index": "website", "_type": "blog", "_id": "" }}
{ "title": "My first blog post" }
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "", "_retry_on_conflict" : } }
{ "doc" : {"title" : "My updated blog post"} }
(1)请注意delete动作不能有请求体,它后面跟着的是另外一个操作。
(2)谨记最后一个换行符不要落下。
#注:整个批量请求都需要由接收到请求的节点加载到内存中,因此该请求越大,其他请求所能获得的内存就越少。批量请求的大小有一个最佳值,大于这个值,性能将不再提升,甚至会下降。但是最佳值不是一个固定的值。它完全取决于硬件、文档的大小和复杂度、索引和搜索的负载的整体情况。
通过批量索引典型文档,并不断增加批量大小进行尝试。当性能开始下降,那么你的批量大小就太大了。一个好的办法是开始时将1,000到5,000个文档作为一个批次,如果你的文档非常大,那么就减少批量的文档个数。
密切关注你的批量请求的物理大小往往非常有用,一千个1KB的文档是完全不同于一千个1MB文档所占的物理大小。一个好的批量大小在开始处理后所占用的物理大小约为5-15 MB。
1.2.请求体查询
1.2.1.空查询
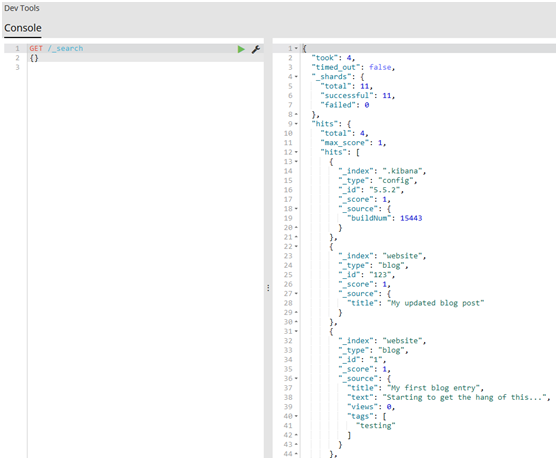
#1.让我们以最简单的search API的形式开启我们的旅程,空查询将返回所有索引库(indices)中的所有文档:
GET /_search
{}
#2.只用一个查询字符串,你就可以在一个、多个或者_all索引库(indices)和一个、多个或者所有types中查询:
GET /index_2014*/type1,type2/_search
{}
#3.分页搜索
GET /_search
{
"from": ,
"size":
}

1.2.2.表达式查询
#1.要使用这种查询表达式,只需将查询语句传递给query参数:
GET /_search
{
"query": YOUR_QUERY_HERE
}
#2.空查询(empty search)—{}—在功能上等价于使用match_all查询,正如其名字一样,匹配所有文档:
GET /_search
{
"query": {
"match_all": {}
}
}
#3.查询语句结构
#一个查询语句的典型结构:
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
#4.如果是针对某个字段,那么它的结构如下:
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}
#举个例子,你可以使用match查询语句来查询tweet字段中包含elasticsearch的tweet:
{
"match": {
"tweet": "elasticsearch"
}
}
#完整的查询请求如下:
GET /_search
{
"query": {
"match": {
"tweet": "elasticsearch"
}
}
}
#5.合并查询语句
#查询语句(Query clauses)就像一些简单的组合块,这些组合块可以彼此之间合并组成更复杂的查询。这些语句可以是如下形式:
(1)叶子语句(Leaf clauses)(就像match语句)被用于将查询字符串和一个字段(或者多个字段)对比。
(2)复合(Compound)语句主要用于合并其它查询语句。比如,一个bool语句允许在你需要的时候组合其它语句,无论是must匹配、must_not匹配还是should匹配,同时它可以包含不评分的过滤器(filters):
{
"bool": {
"must": { "match": { "tweet": "elasticsearch" }},
"must_not": { "match": { "name": "mary" }},
"should": { "match": { "tweet": "full text" }},
"filter": { "range": { "age" : { "gt" : , "lt":}} }
}
}
#例如,以下查询是为了找出信件正文包含business opportunity的星标邮件,或者在收件箱正文包含business opportunity的非垃圾邮件:
{
"bool": {
"must": { "match": { "email": "business opportunity" }},
"should": [
{ "match": { "starred": true }},
{ "bool": {
"must": { "match": { "folder": "inbox" }},
"must_not": { "match": { "spam": true }}
}}
],
"minimum_should_match":
}
}
1.2.3.最重要的查询
#1.match_all查询,简单的匹配所有文档。在没有指定查询方式时,它是默认的查询
{ "match_all": {}}
#它经常与filter结合使用--例如,检索收件箱里的所有邮件。所有邮件被认为具有相同的相关性,所以都将获得分值为1的中性`_score`。
#2.match查询,
#无论你在任何字段上进行的是全文搜索还是精确查询,match查询是你可用的标准查询。
#如果你在一个全文字段上使用match查询,在执行查询前,它将用正确的分析器去分析查询字符串:
{ "match": { "tweet": "About Search" }}
#如果在一个精确值的字段上使用它,例如数字、日期、布尔或者一个not_analyzed字符串字段,那么它将会精确匹配给定的值:
{ "match": { "age": }}
{ "match": { "date": "2014-09-01" }}
{ "match": { "public": true }}
{ "match": { "tag": "full_text" }}
#3.multi_match查询
#multi_match查询可以在多个字段上执行相同的match查询:
{
"multi_match": {
"query": "full text search",
"fields": [ "title", "body" ]
}
}
#4.range查询
#range查询找出那些落在指定区间内的数字或者时间:
{
"range": {
"age": {
"gte": ,
"lt":
}
}
}
#5.terms查询
#terms查询和term查询一样,但它允许你指定多值进行匹配。如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件:
{ "terms": { "tag": [ "search", "full_text", "nosql" ] }}
#和term查询一样,terms查询对于输入的文本不分析。它查询那些精确匹配的值(包括在大小写、重音、空格等方面的差异)。
#6.exists查询和missing查询
exists查询和missing查询被用于查找那些指定字段中有值(exists)或无值(missing)的文档。这与SQL中的IS_NULL (missing)和NOT IS_NULL (exists)在本质上具有共性:
{
"exists": {
"field": "title"
}
}
#这些查询经常用于某个字段有值的情况和某个字段缺值的情况。
1.2.4.组合多查询
#1.现实的查询需求从来都没有那么简单;它们需要在多个字段上查询多种多样的文本,并且根据一系列的标准来过滤。为了构建类似的高级查询,你需要一种能够将多查询组合成单一查询的查询方法。
你可以用bool查询来实现你的需求。这种查询将多查询组合在一起,成为用户自己想要的布尔查询。它接收以下参数:
must 文档必须匹配这些条件才能被包含进来。
must_not 文档必须不匹配这些条件才能被包含进来。
should 如果满足这些语句中的任意语句,将增加_score,否则,无任何影响。它们主要用于修正每个文档的相关性得分。
filter 必须匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
由于这是我们看到的第一个包含多个查询的查询,所以有必要讨论一下相关性得分是如何组合的。每一个子查询都独自地计算文档的相关性得分。一旦他们的得分被计算出来,bool查询就将这些得分进行合并并且返回一个代表整个布尔操作的得分。
下面的查询用于查找title字段匹配how to make millions并且不被标识为spam的文档。那些被标识为starred或在2014之后的文档,将比另外那些文档拥有更高的排名。如果_两者_都满足,那么它排名将更高:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }},
{ "range": { "date": { "gte": "2014-01-01" }}}
]
}
}
注:如果没有must语句,那么至少需要能够匹配其中的一条should语句。但,如果存在至少一条must语句,则对should语句的匹配没有要求。
# 2.增加带过滤器(filtering)的查询
#如果我们不想因为文档的时间而影响得分,可以用filter语句来重写前面的例子:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }},
{ "range": { "date": { "gte": "2014-01-01" }}}
]
}
}
#3.range查询已经从should语句中移到filter语句
#通过将range查询移到filter语句中,我们将它转成不评分的查询,将不再影响文档的相关性排名。由于它现在是一个不评分的查询,可以使用各种对filter查询有效的优化手段来提升性能。
#所有查询都可以借鉴这种方式。将查询移到bool查询的filter语句中,这样它就自动的转成一个不评分的filter了。
#如果你需要通过多个不同的标准来过滤你的文档,bool查询本身也可以被用做不评分的查询。简单地将它放置到filter语句中并在内部构建布尔逻辑:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }},
{ "range": { "date": { "gte": "2014-01-01" }}}
]
}
}
#4.onstant_score查询
#尽管没有bool查询使用这么频繁,constant_score查询也是你工具箱里有用的查询工具。它将一个不变的常量评分应用于所有匹配的文档。它被经常用于你只需要执行一个filter而没有其它查询(例如,评分查询)的情况下。
#可以使用它来取代只有filter语句的bool查询。在性能上是完全相同的,但对于提高查询简洁性和清晰度有很大帮助。
{
"constant_score": {
"filter": {
"term": { "category": "ebooks" }
}
}
}
#term查询被放置在constant_score中,转成不评分的filter。这种方式可以用来取代只有filter语句的bool查询。
#1.查询可以变得非常的复杂,尤其 和不同的分析器与不同的字段映射结合时,理解起来就有点困难了。不过 validate-query API 可以用来验证查询是否合法。1.2.5.验证查询
#1.
GET /gb/tweet/_validate/query
{
"query": {
"tweet" : {
"match" : "really powerful"
}
}
}
#以上validate请求的应答告诉我们这个查询是不合法的:
{
"valid" : false,
"_shards" : {
"total" : ,
"successful" : ,
"failed" :
}
}
#2.理解错误信息
#为了找出查询不合法的原因,可以将explain参数加到查询字符串中:
GET /gb/tweet/_validate/query?explain
{
"query": {
"tweet" : {
"match" : "really powerful"
}
}
}
#explain参数可以提供更多关于查询不合法的信息。
很明显,我们将查询类型(match)与字段名称(tweet)搞混了:
{
"valid" : false,
"_shards" : { ... },
"explanations" : [ {
"index" : "gb",
"valid" : false,
"error" : "org.elasticsearch.index.query.QueryParsingException:
[gb] No query registered for [tweet]"
} ]
}
#3.理解查询语句
#对于合法查询,使用explain参数将返回可读的描述,这对准确理解Elasticsearch是如何解析你的query是非常有用的:
GET /_validate/query?explain
{
"query": {
"match" : {
"tweet" : "really powerful"
}
}
}
#我们查询的每一个index都会返回对应的explanation,因为每一个index都有自己的映射和分析器:
{
"valid" : true,
"_shards" : { ... },
"explanations" : [ {
"index" : "us",
"valid" : true,
"explanation" : "tweet:really tweet:powerful"
}, {
"index" : "gb",
"valid" : true,
"explanation" : "tweet:realli tweet:power"
} ]
}
#从explanation中可以看出,匹配really powerful的match查询被重写为两个针对tweet字段的single-term查询,一个single-term查询对应查询字符串分出来的一个term。
#当然,对于索引us,这两个term分别是really和powerful,而对于索引gb,term则分别是realli和power。之所以出现这个情况,是由于我们将索引gb中tweet字段的分析器修改为english分析器。
Elasticsearch 常用API的更多相关文章
- Elasticsearch常用API
Note:以下API基于ES 5x,6x/7x可能略有不同,具体查看官方文档 ES常用API # 查看集群node curl "http://localhost:9200/_cat/node ...
- Elasticsearch java api 常用查询方法QueryBuilder构造举例
转载:http://m.blog.csdn.net/u012546526/article/details/74184769 Elasticsearch java api 常用查询方法QueryBuil ...
- Elasticsearch java api 基本搜索部分详解
文档是结合几个博客整理出来的,内容大部分为转载内容.在使用过程中,对一些疑问点进行了整理与解析. Elasticsearch java api 基本搜索部分详解 ElasticSearch 常用的查询 ...
- 搜索引擎Elasticsearch REST API学习
Elasticsearch为开发者提供了一套基于Http协议的Restful接口,只需要构造rest请求并解析请求返回的json即可实现访问Elasticsearch服务器.Elasticsearch ...
- ELK常用API使用方法
以下ELK系列文章参考自http://www.tianyiqingci.com/ 总目录: Monitor API ElasticSearch聚合分析API Elasticsearch信息检索API ...
- Elasticsearch-02-入门:集群、节点、分片、索引及常用API
2. 基础入门 2.1 重要概念 2.1.1 集群和节点 1)cluster Elasticsearch集群是由一个或多个节点组成,通过其集群名称来进行唯一标识.节点在搜索到集群之后,通过判断自身的 ...
- html5 canvas常用api总结(一)
1.监听浏览器加载事件. window.addEventListener("load",eventWindowLoaded,false); load事件在html页面加载结束时发生 ...
- compass General 常用api学习[Sass和compass学习笔记]
compass 中一些常用api 包括一些浏览器hack @import "compass/utilities/general" Clearfix Clearfix 是用来清除浮动 ...
- java基础3.0:Java常用API
本篇介绍Java基础中常用API使用,当然只是简单介绍,围绕重要知识点引入,巩固开发知识,深入了解每个API的使用,查看JavaAPI文档是必不可少的. 一.java.lang包下的API Java常 ...
随机推荐
- 关于Android中的ViewTreeObserver
ViewTreeObserver结构 extends Object java.lang.Object ↳ android.view.ViewTreeObserver ViewTreeObserver概 ...
- font not embeded
转自:http://blog.csdn.net/chenyusiyuan/article/details/4078671,感谢分享! 装了半天adobe acrobat distiller 要泪崩,解 ...
- mysql分析慢查询日志工具mysqlsla安装
1 配置perlperl -MCPAN -e shell cpan[1]>install Time:HiRescpan[1]>install File::Tempcpan[1]> ...
- android中View点击和触摸事件的处理
android中的事件类型分为按键事件和屏幕触摸事件,Touch事件是屏幕触摸事件的基础事件,有必要对它进行深入的了解. 一个最简单的屏幕触摸动作触发了一系列Touch事件:ACTION_DOWN-& ...
- ubuntu16.4 修改菜单到下方 错误:GLib-GIO-Message: Using the 'memory' GSettings backend. Your settings will not be saved or shared with other applications.
1.修改命令 #在终端输入 gsettings set com.canonical.Unity.Launcher launcher-position Bottom 2.如果遇错 GLib-GIO-Me ...
- jquery.dataTables列中内容居中问题?求解?
.table > tbody > tr > td { vertical-align: middle; }
- 解决svn中“工作副本已经锁定”,或者svn清理失败的解决方法
刚开始遇到这个问题还以为是没有插网线的原因,客户端和服务器都在我的电脑上,但是更新和提交都执行不了,以为是没有插网线就没把这个小问题放在心上,今早上还是这样,就不得不解决一下了. 更新或者提交前要执行 ...
- Bokeh 学习
这段时间由于在做K-means对文本进行处理,需要进行绘图,实验室编程大哥向我介绍了Bokeh来进行绘图,一直是根据自己的需求来进行对其探索,今儿个看到一篇博文,对Bokeh进行了详细的解说,做个笔记 ...
- Very Deep Convolutional Networks for Large-scale Image Recognition(vggnet)
vggNet是从AlexNet而来,主要探索卷积神经网络的深度与性能之间的关系,通过反复堆叠3x3的卷积核(c中有1x1的卷积核,也只有c中有,c是16层)和2x2的最大池化层,vggNet构筑了16 ...
- 【题解】洛谷P3205【HNOI2010】合唱队
洛谷 P3205:https://www.luogu.org/problemnew/show/P3205 复习区间DPing 思路 把理想队列拆分成 第一个和后面几个 划分成求后面几个的理想队列 最后 ...