SpringCloud学习之sleuth&zipkin【二】
这篇文章我们解决上篇链路跟踪的遗留问题
一、将追踪数据存放到MySQL数据库中
默认情况下zipkin将收集到的数据存放在内存中(In-Memeroy),但是不可避免带来了几个问题:
- 在服务重新启动后,历史数据丢失。
- 在数据量过大的时候容易造成OOM错误
通常做法是与mysql或者ElasticSearch结合使用,那么我们先把收集到的数据先存到Mysql数据库中
1、改造zipkin-server的依赖
gradle配置:
dependencies {
compile('org.springframework.cloud:spring-cloud-starter-eureka')
compile('org.springframework.cloud:spring-cloud-starter-config')
// compile('io.zipkin.java:zipkin-server')
compile 'org.springframework.cloud:spring-cloud-starter-sleuth'
compile('io.zipkin.java:zipkin-autoconfigure-ui')
runtime('mysql:mysql-connector-java')
compile('org.springframework.boot:spring-boot-starter-jdbc')
compile('org.springframework.cloud:spring-cloud-sleuth-zipkin-stream')
compile('org.springframework.cloud:spring-cloud-stream')
compile('org.springframework.cloud:spring-cloud-stream-binder-kafka')
}
这里将原先的 io.zipkin.java:zipkin-server 替换为 spring-cloud-sleuth-zipkin-stream 该依赖项包含了对mysql存储的支持,同时添加spring-boot-starter-jdbc与mysql的依赖,顺便把kafka的支持也加进来
注意:此处脚本最好在数据库中执行一下,当然我们也可以在下面的配置文件中做初始化的相关配置
2、YAML中的关键配置项:
spring:
datasource:
username: root
password: root
url: jdbc:mysql://localhost:3306/myschool?characterEncoding=utf-8&useSSL=false
initialize: true
continue-on-error: true
kafka:
bootstrap-servers: localhost:9092
server:
port: 9000
zipkin:
storage:
type: mysql
注意zipkin.storage.type 指定为mysql
3、更改启动类
package com.hzgj.lyrk.zipkin.server; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer; @EnableZipkinStreamServer
@SpringBootApplication
public class ZipkinServerApplication { public static void main(String[] args) {
SpringApplication.run(ZipkinServerApplication.class, args);
}
}
这里注意将@EnableZipkinServer改成@EnableZipkinStreamServer
二、将收集信息改成异步发送
这步改造主要用以提高性能与稳定性,服务将收集到的span无脑的往消息中间件上丢就可以了,不用管zipkin的地址在哪里。
1、改造Order-Server依赖:
gradle:
compile('org.springframework.cloud:spring-cloud-starter-eureka-server')
// compile('org.springframework.cloud:spring-cloud-sleuth-zipkin')
compile 'org.springframework.cloud:spring-cloud-starter-sleuth'
compile 'org.springframework.cloud:spring-cloud-sleuth-stream'
compile('org.springframework.cloud:spring-cloud-starter-config')
compile('org.springframework.cloud:spring-cloud-stream')
compile('org.springframework.cloud:spring-cloud-stream-binder-kafka')
compile('org.springframework.kafka:spring-kafka')
compile('org.springframework.cloud:spring-cloud-starter-bus-kafka')
这里把原先的spring-cloud-sleuth-zipkin改成spring-cloud-sleuth-stream,不用猜里面一定是基于spring-cloud-stream实现的
2、YAML关键属性配置:
server:
port: 8100
logging:
level:
org.springframework.cloud.sleuth: DEBUG
spring:
sleuth:
sampler:
percentage: 1.0
注意:这里设置低采样率会导致span的丢弃。我们同时设置sleuth的日志输出为debug
3、同理改造其他的微服务
三、验证结果
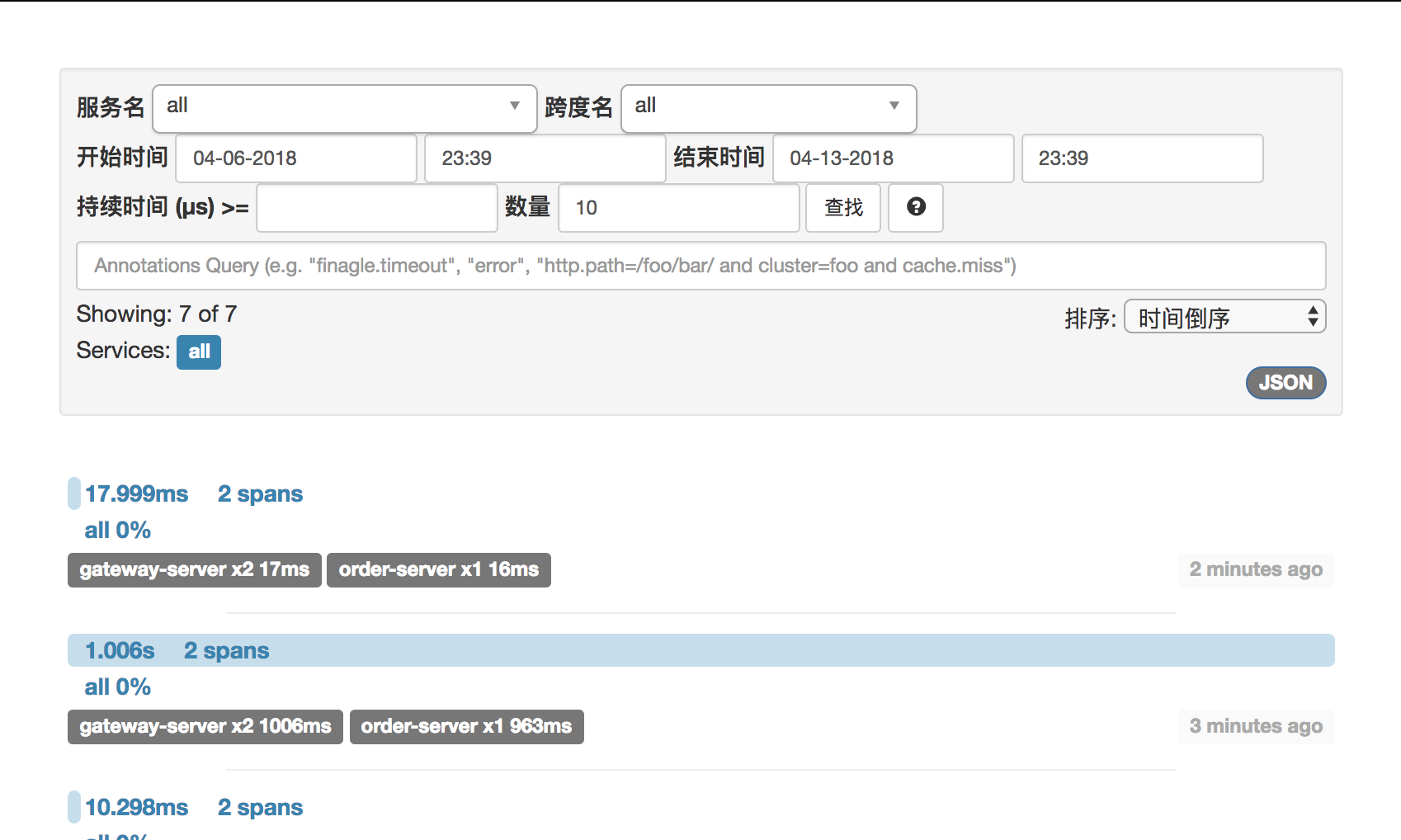
数据库里的相关数据:

SpringCloud学习之sleuth&zipkin【二】的更多相关文章
- SpringCloud学习之sleuth&zipkin
一.调用链跟踪的必要性 首先我们简单来看一下下单到支付的过程,别的不多说,在业务复杂的时候往往服务会一层接一层的调用,当某一服务环节出现响应缓慢时会影响整个服务的响应速度,由于业务调用层次很“深”,那 ...
- SpringCloud学习之Sleuth服务链路跟踪(十二)
一.为什么需要Spring Cloud Sleuth 微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元.由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很 ...
- spring cloud 学习(8) - sleuth & zipkin 调用链跟踪
业务复杂的微服务架构中,往往服务之间的调用关系比较难梳理,一次http请求中,可能涉及到多个服务的调用(eg: service A -> service B -> service C... ...
- SpringCloud学习成长之十二 断路器监控
在我的第四篇文章断路器讲述了如何使用断路器,并简单的介绍了下Hystrix Dashboard组件,这篇文章更加详细的介绍Hystrix Dashboard. 一.Hystrix Dashboard简 ...
- SpringCloud学习成长之路二 服务客户端(rest+ribbon)
在微服务架构中,业务都会被拆分成一个独立的服务,服务与服务的通讯是基于http restful的. Spring cloud有两种服务调用方式,一种是ribbon+restTemplate,另一种是f ...
- springcloud微服务实战:Eureka+Zuul+Feign/Ribbon+Hystrix Turbine+SpringConfig+sleuth+zipkin
相信现在已经有很多小伙伴已经或者准备使用springcloud微服务了,接下来为大家搭建一个微服务框架,后期可以自己进行扩展.会提供一个小案例: 服务提供者和服务消费者 ,消费者会调用提供者的服务,新 ...
- SpringCloud Sleuth + Zipkin 实现链路追踪
一.Sleuth介绍 为什么要使用微服务跟踪? 它解决了什么问题? 1.微服务的现状? 随着业务的发展,单体架构变为微服务架构,并且系统规模也变得越来越大,各微服务间的调用关系也变得越来越复杂 ...
- SpringCloud学习(二):微服务入门实战项目搭建
一.开始使用Spring Cloud实战微服务 1.SpringCloud是什么? 云计算的解决方案?不是 SpringCloud是一个在SpringBoot的基础上构建的一个快速构建分布式系统的工具 ...
- springcloud -- sleuth+zipkin整合rabbitMQ详解
为什么使用RabbitMQ? 我们已经知道,zipkin的原理是服务之间的调用关系会通过HTTP方式上报到zipkin-server端,然后我们再通过zipkin-ui去调用查看追踪服务之间的调用链路 ...
随机推荐
- Android类加载机制及热修复实现
Android类加载机制 Dalvik虚拟机如同其他Java虚拟机一样,在运行程序时首先需要将对应的类加载到内存中.而在Java标准的虚拟机中,类加载可以从class文件中读取,也可以是其他形式的二进 ...
- vue 手机端开发 小商铺 添加购物车 以及结算 功能
这个功能绕了我一天!!! 对 就是这个功能 一系列相关联的 四处相关联 现在加班 没时间更 过两天在更
- JAVA_SE基础——19.数组的定义
数组是一组相关数据的集合,数组按照使用可以分为一维数组.二维数组.多维数组 本章先讲一维数组 不同点: 不使用数组定义100个整形变量:int1,int2,int3;;;;;; 使用数组定义 int ...
- 一个诚实的孩纸选Python的原因
我之所以会选择python语言程序设计这门课,是因为我一开始预选选的选修课都没选上,然后在补选的时候,在别人选剩的课里面选择了python. 上了两节课之后,我发现python还挺有意思的,挺喜欢py ...
- Python内置函数(47)——vars
英文文档: vars([object]) Return the __dict__ attribute for a module, class, instance, or any other objec ...
- Python内置函数(1)——abs
英文文档: abs(x) Return the absolute value of a number. The argument may be an integer or a floating poi ...
- Delphi Web开发连载 --ThinkDelphi (序)
如果把Delphi比作男人,那他曾经独步天下,笑傲江湖过: 如果把Delphi比作女子,那她曾经貌美如花,倾国倾城过! 但那只是历史,那只是曾经, 弹指一挥间,Delphi却似乎英雄迟暮,美人已老.. ...
- PHP常用函数集合
PHP常用函数总结 数学函数 1.abs(): 求绝对值 $abs = abs(-4.2); //4.2 数字绝对值数字 2.ceil(): 进一法取整 echo ceil(9.999); // 10 ...
- 推荐几个IDEA插件,Java开发者撸码利器。
这里只是推荐一下好用的插件,具体的使用方法不一一详细介绍. JRebel for IntelliJ 一款热部署插件,只要不是修改了项目的配置文件,用它都可以实现热部署.收费的,破解比较麻烦.不过功能确 ...
- 南京邮电大学java程序设计作业在线编程第三次作业
王利国的"Java语言程序设计第3次作业(2018)"详细 作业结果详细 总分:100 选择题得分:60 1. 设有如下定义语句: String s1="My cat& ...