SpringCloud学习之sleuth&zipkin
一。调用链跟踪的必要性
首先我们简单来看一下下单到支付的过程,别的不多说,在业务复杂的时候往往服务会一层接一层的调用,当某一服务环节出现响应缓慢时会影响整个服务的响应速度,由于业务调用层次很“深”,那么在排查问题的时候也会更加困难,如果有一种机制帮我们监控、收集这些服务之间层层调用的时间与逻辑关系是否会助于我们排查问题呢?要解决这个问题。我们就必须借助于分布式服务跟踪系统的力量了
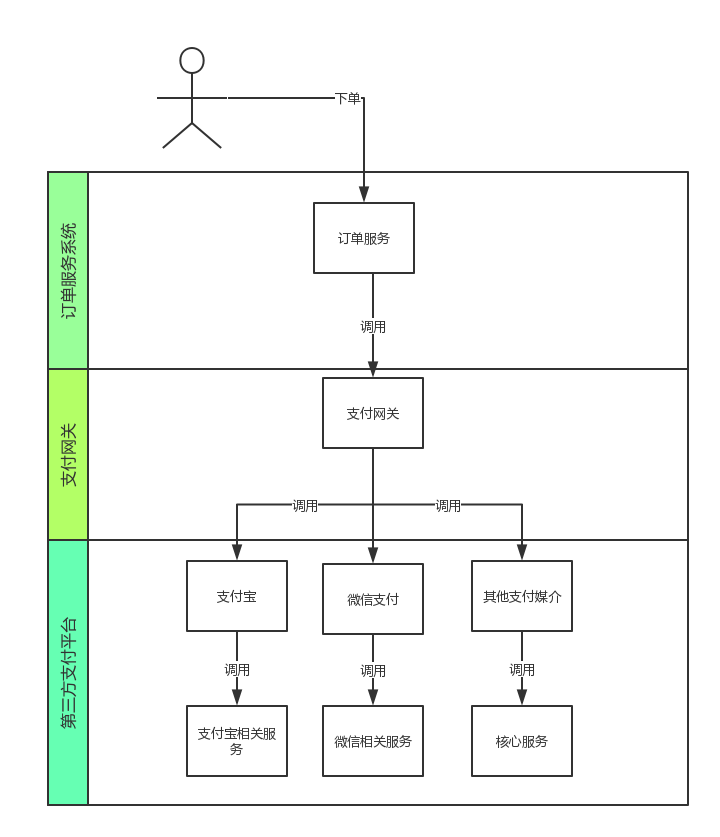
一般的,一个分布式服务跟踪系统,主要有三部分:数据收集、数据存储和数据展示。根据系统大小不同,每一部分的结构又有一定变化。譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分,实时数据用于故障排查(troubleshooting),全量数据用于系统优化。那么我在贴一张图,此图是spring-cloud-sleuth的概念图:
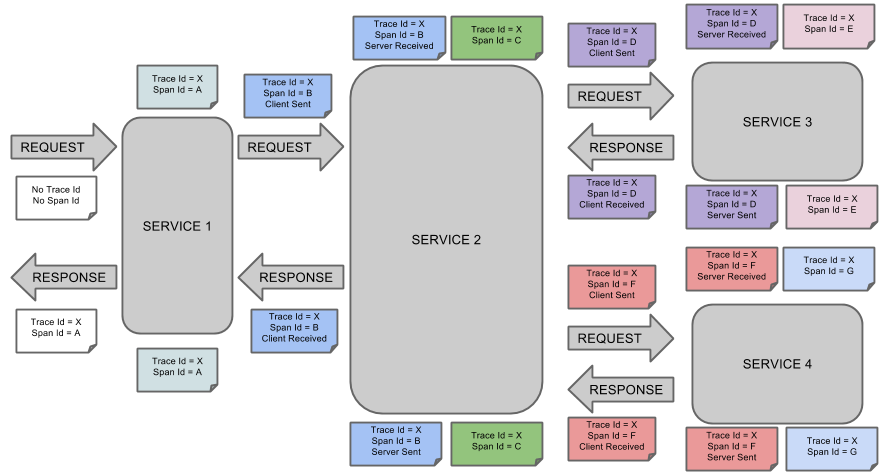
初次看这个图会有点迷糊,因为有一些名词需要大家了解一下
trace:是指我们从服务开始到服务执行的终点的一次完整的请求与相应。
span: 在一次完整的trace过程中,每调用一个服务都会记录调用信息与响应时间,这个就是span
由此我们可以得出一个结论就是:一次trace由若干个span构成,sleuth是用于调用链追踪,通过sleuth我们可以轻易的追踪到trace经过了哪几个服务,每个服务花费的时间等,而zipkin是一个开源的追踪系统,它负责收集,存储数据并展示给用户。Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。
二。spring-cloud-sleuth的快速使用
注意SpringCloud的Finchley M8版本的sleuth和zipkin的包还有点冲突,因此我使用Edgware SR2的版本,此版本对应的SpringBoot的版本是1.5.10.RELEASE,我们还是基于以下项目模块构建:
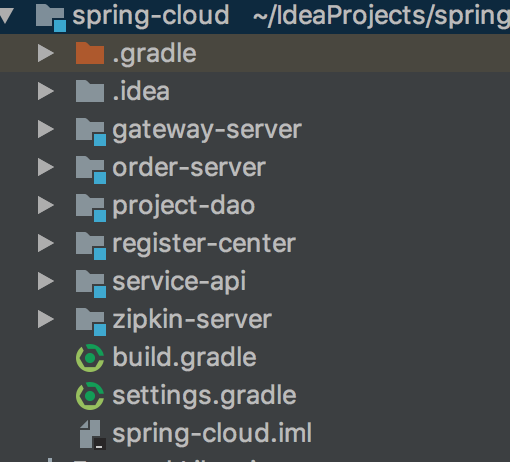
1. 添加启动zipkin服务zipkin-server模块
gradle配置:
dependencies {
compile('org.springframework.cloud:spring-cloud-starter-eureka')
compile('io.zipkin.java:zipkin-server')
compile('io.zipkin.java:zipkin-autoconfigure-ui')
}
application.yml配置
server:
port: 8200
eureka:
client:
service-url:
defaultZone: http://localhost:8000/eureka
spring:
application:
name: zipkin-server
定义启动类:
package com.hzgj.lyrk.zipkin.server; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import zipkin.server.EnableZipkinServer; @EnableZipkinServer
@EnableDiscoveryClient
@SpringBootApplication
public class ZipkinServerApplication { public static void main(String[] args) {
SpringApplication.run(ZipkinServerApplication.class, args);
}
}
当我们启动成功后,访问http://localhost:8200/可以看到如下界面:
由于我们没有配置监控的服务内容,因此在zipkin里并没有统计数据
2.处理要跟踪的服务模块
tips:在这里gateway-server为网关模块使用zuul来实现,通过网关调用order-server。
分别在要进行服务追踪的模块gateway-server里添加如下依赖:
compile('org.springframework.cloud:spring-cloud-starter-eureka-server')
compile('org.springframework.cloud:spring-cloud-sleuth-zipkin')
compile 'org.springframework.cloud:spring-cloud-starter-sleuth'
在application.yml里的配置:
spring:
zipkin:
base-url: http://localhost:8200
sleuth:
sampler:
percentage: 1.0
spring.zipkin.baseUrl是指我们启动的zipkin-server服务地址
spring.sleuth.sampler.percentage 是代表采样率,值越大就代表采样的频率越高 默认为0.1 最大为1.0(即每次请求都进行跟踪)
分别启动gateway-server与order-server并通过gateway-server访问order-server若干次后,我们在通过zipkin查找按钮来访问结果,如下:
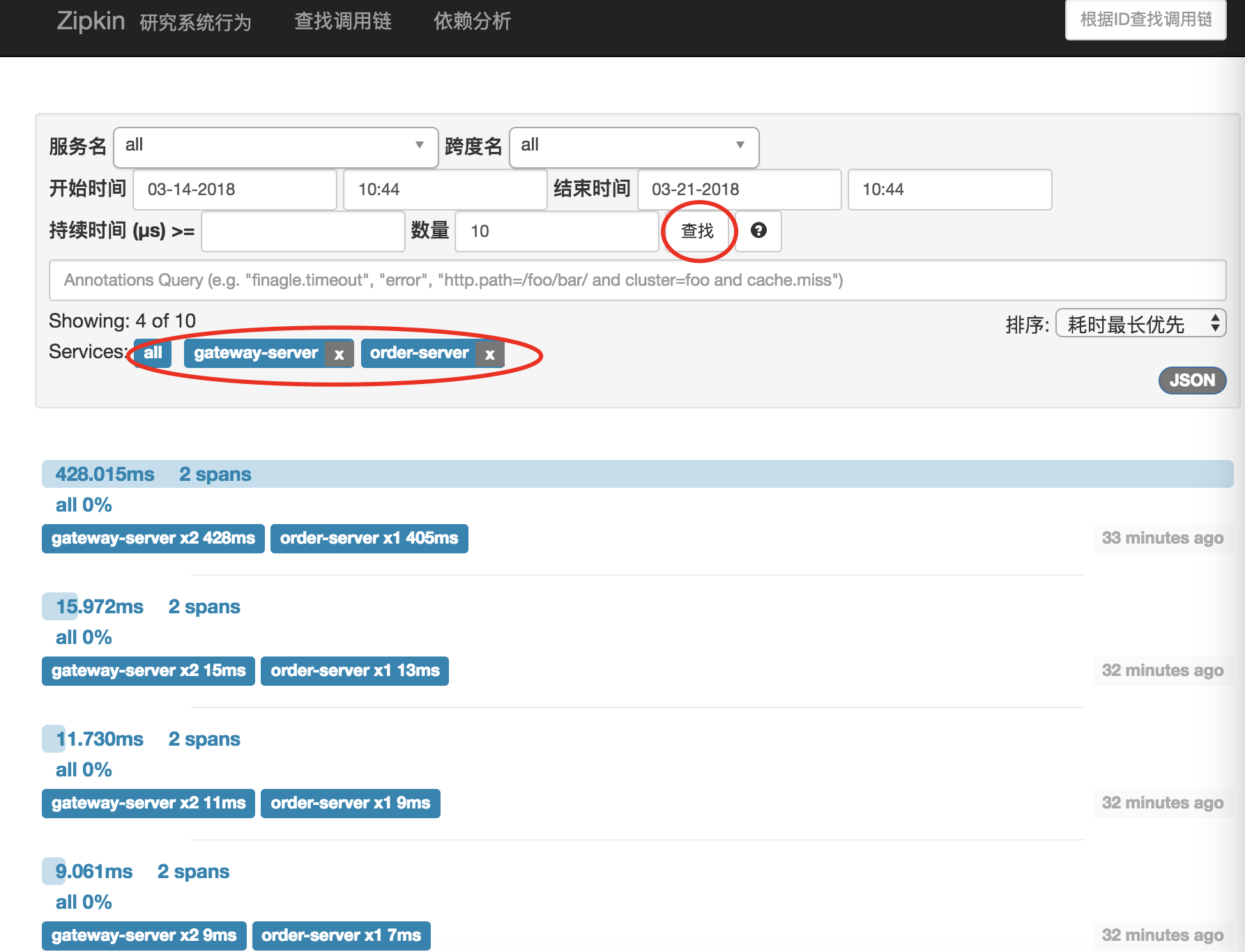
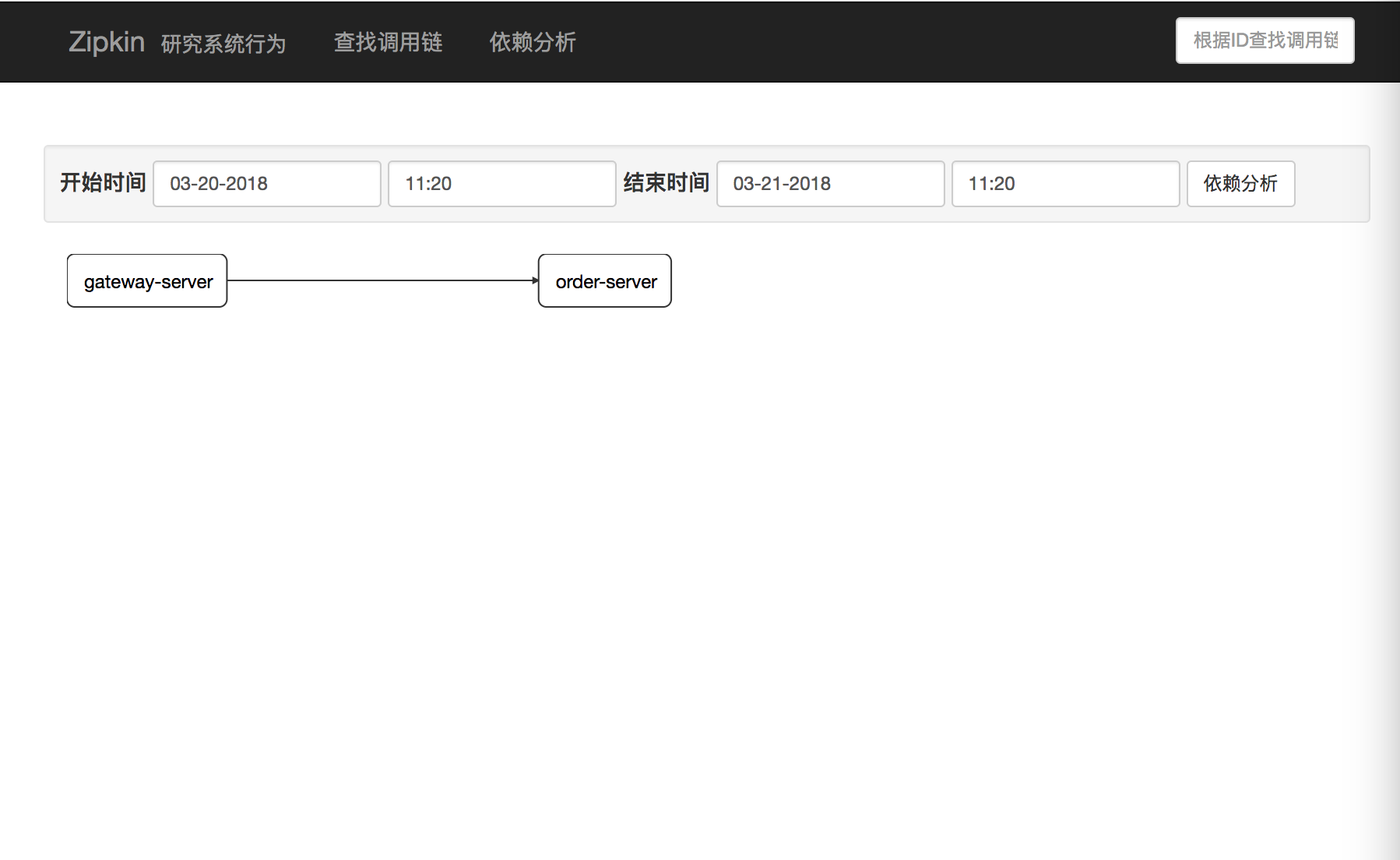
在这里面我们留意几个问题:
1)通过上述的配置,sleuth每次将监控的span通过http请求发送到zipkin-server会浪费一些性能,同时如果zipkin-server出现问题时,数据容易产生丢失
2)在本例当中,数据存到内存当中,数据量过大容易产生OOM错误
在以后的篇幅中会给出这些问题的解决方案。
SpringCloud学习之sleuth&zipkin的更多相关文章
- SpringCloud学习之sleuth&zipkin【二】
这篇文章我们解决上篇链路跟踪的遗留问题 一.将追踪数据存放到MySQL数据库中 默认情况下zipkin将收集到的数据存放在内存中(In-Memeroy),但是不可避免带来了几个问题: 在服务重新启动后 ...
- SpringCloud学习之Sleuth服务链路跟踪(十二)
一.为什么需要Spring Cloud Sleuth 微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元.由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很 ...
- spring cloud 学习(8) - sleuth & zipkin 调用链跟踪
业务复杂的微服务架构中,往往服务之间的调用关系比较难梳理,一次http请求中,可能涉及到多个服务的调用(eg: service A -> service B -> service C... ...
- springcloud微服务实战:Eureka+Zuul+Feign/Ribbon+Hystrix Turbine+SpringConfig+sleuth+zipkin
相信现在已经有很多小伙伴已经或者准备使用springcloud微服务了,接下来为大家搭建一个微服务框架,后期可以自己进行扩展.会提供一个小案例: 服务提供者和服务消费者 ,消费者会调用提供者的服务,新 ...
- springcloud -- sleuth+zipkin整合rabbitMQ详解
为什么使用RabbitMQ? 我们已经知道,zipkin的原理是服务之间的调用关系会通过HTTP方式上报到zipkin-server端,然后我们再通过zipkin-ui去调用查看追踪服务之间的调用链路 ...
- SpringCloud Sleuth + Zipkin 实现链路追踪
一.Sleuth介绍 为什么要使用微服务跟踪? 它解决了什么问题? 1.微服务的现状? 随着业务的发展,单体架构变为微服务架构,并且系统规模也变得越来越大,各微服务间的调用关系也变得越来越复杂 ...
- springcloud --- spring cloud sleuth和zipkin日志管理(spring boot 2.18)
前言 在spring cloud分布式架构中,系统被拆分成了许多个服务单元,业务复杂性提高.如果出现了异常情况,很难定位到错误位置,所以需要实现分布式链路追踪,跟进一个请求有哪些服务参与,参与的顺序如 ...
- Spring Cloud Alibaba学习笔记(23) - 调用链监控工具Spring Cloud Sleuth + Zipkin
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求陷入性能瓶颈或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何 ...
- SpringCloud 2020.0.4 系列之 Sleuth + Zipkin
1. 概述 老话说的好:安全不能带来财富,但盲目的冒险也是不可取的,大胆筹划,小心实施才是上策. 言归正传,微服务的特点就是服务多,服务间的互相调用也很复杂,就像一张关系网,因此为了更好的定位故障和优 ...
随机推荐
- 通过URL传递PDF名称参数显示PDF
1 <%@ page language="java" import="java.util.*,java.io.*" 2 pageEncoding=&quo ...
- linux下安装配置jdk(解压版)
在linux下登录oracle官网,下载解压版jdk 传送门 系统默认下载到"下载"目录中 创建要将该文件解压的文件夹: 其中 -p 参数代表递归创建文件夹(可以创建多级目录 ...
- Python扩展模块——自动化(testlinkAPI的使用)
使用TESTLINKAPI首先要安装TestLink_API_Python_client-0.6.4(当前最新版本) 目前只使用到了通过api获取testlink中的自定义字段and值 url = ' ...
- windbg查找Kernel32.dll基址
一.首先准备好一个程序,运行起来,用windbg进行附加调试,由于每个windows下的程序都会加载kernel32.dll,因此,找基址的过程是一样的: 二.查看PEB地址: 法一.r $peb ...
- kubernetes进阶(04)kubernetes的service
一.service概念 Service是对一组提供相同功能的Pods的抽象,并为它们提供一个统一的入口.借助Service,应用可以方便的实现服务发现与负载均衡,并实现应用的零宕机升级.Service ...
- Spring Security 入门(1-9)国际化的使用
- python/SQLAchemy
python/SQLAchemy SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数 ...
- XSS和CSRF的理解
声明:转自 http://www.cnblogs.com/hyddd/archive/2009/04/09/1432744.html XSS攻击:跨站脚本攻击(Cross Site Scripting ...
- Windows10下的docker安装与入门 (一)使用docker toolbox安装docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化.容器是完全使用沙箱机制,相互之间不会有任何 ...
- POJ-3259 Wormholes---SPFA判断有无负环
题目链接: https://vjudge.net/problem/POJ-3259 题目大意: 农夫约翰在探索他的许多农场,发现了一些惊人的虫洞.虫洞是很奇特的,因为它是一个单向通道,可让你进入虫洞的 ...