ISLR系列:(4.2)模型选择 Ridge Regression & the Lasso
Linear Model Selection and Regularization
此博文是 An Introduction to Statistical Learning with Applications in R 的系列读书笔记,作为本人的一份学习总结,也希望和朋友们进行交流学习。
该书是The Elements of Statistical Learning 的R语言简明版,包含了对算法的简明介绍以及其R实现,最让我感兴趣的是算法的R语言实现。
【转载时请注明来源】:http://www.cnblogs.com/runner-ljt/
Ljt 勿忘初心 无畏未来
作为一个初学者,水平有限,欢迎交流指正。
当自变量的维度较高时,一方面可能使得样本量偏少(p>n),另一方面自变量之间很可能会出现多重共线性现象。多重共线性会导致最小二乘的
回归系数不稳定,方差较大(这是因为系数矩阵与其转置矩阵的乘积矩阵不可逆)。收缩法/正则化(shrinkage/regularization)主要是建立包含全体
变量的模型的同时加上对估计系数的限制,即使系数的估计向0收缩。
岭回归从矩阵求解的角度看就是修复病态矩阵X'X,多重共线性导致|X'X|趋于0,那么就给X'X加上一个正常数矩阵 kI (k>0),则X'X+kI接近奇异
的程度就会比X'X接近奇异的程度小得多,从而使回归系数的估计稍有偏差,但是估计的稳定性却可能明显提高;从最小二乘的角度看就是加上一个对
回归系数的二范数惩罚项的有偏最小二乘。

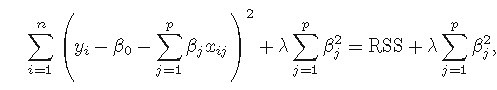
岭回归的一个缺点是在建模时对于引入的全体自变量,罚约束项可以收缩这些变量的待估系数接近0,但并非恰好是0(除非lambda为无穷大),这
对于模型精度影响不大,但给模型的解释造成了困难。(岭回归虽然减少了模型的复杂度,并没有真正解决变量选择的问题)
Lasso回归是引入回归系数的一范数惩罚项的有偏最小二乘回归,Lasso回归能够使得一些变量的系数为零,从而可以实现变量变量选择的问题。
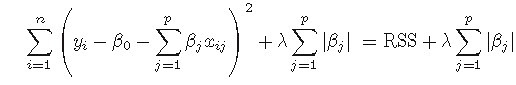
Lasso回归虽然和岭回归的差别在于一个是二范数的约束另一个是一范数的约束,一范数约束能够使得一些变量的回归系数变为0,但是由于其不
连续,求解上便比二范数的要困难的多,Lasso全称为The Least Absolute Shrinkage and Selection Operator,中文翻译为 ‘套索’ ,是目前很多大
牛研究的热门领域。
下图可以解释Lasso回归可以使得一些变量的回归系数为0,而岭回归只能使回归系数趋于0的原因。
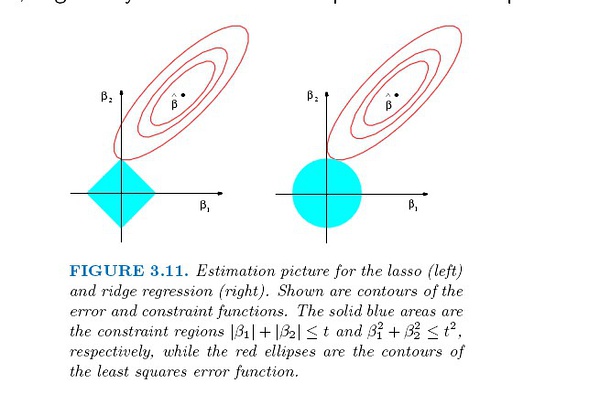
Ridge Regression and the Lasso
glmnet(x, y, family=c("gaussian","binomial","poisson","multinomial"),alpha = 1,nlambda = 100,lambda=NULL)
X:自变量矩阵
Y:因变量
family=c("gaussian","binomial","poisson","multinomial") :
当Y为数值型时,family为 "gaussian" 或 "binomial"
当Y为两水平的因子类型时,family为 "binomial"
当Y为多水平的因子类型时,family为 "multinomial"
alpha: 0<α<1 : (1-α)/2||β||_2^2+α||β||_1. ; alpha=0为岭回归,alpha=1为 Lasso回归
nlambda : lambda的个数,默认为100个
lambda:惩罚系数 λ ,可以人工提供,默认为系统提供
cv.glmnet(x, y, lambda, nfolds):Does k-fold cross-validation for glmnet
predict(object, newx, s = NULL, type=c("link","response","coefficients","nonzero","class"))
object :glmnet类
newx :用于预测的新的X矩阵,该参数不能用于type="coefficients"的情况
s :用于预测的 lambda
type:link,response 返回结果为因变量的预测结果;coefficients 返回结果为模型系数,此时不需要参数newx
> library(ISLR)
> library(glmnet)
> Hitters<-na.omit(Hitters)
>
> #运用交叉验证的方法选择最优的岭回归
> set.seed()
> x<-model.matrix(Salary~.,Hitters)[,-]
> y<-Hitters$Salary
>
> #交叉验证的岭回归
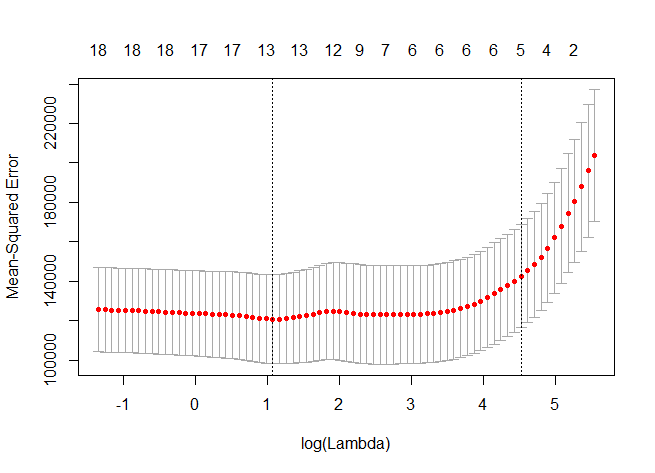
> cv.out<-cv.glmnet(x,y,alpha=)
> plot(cv.out)
>
> names(cv.out)
[] "lambda" "cvm" "cvsd" "cvup" "cvlo" "nzero" "name" "glmnet.fit" "lambda.min" "lambda.1se"
>
> bestlam<-cv.out$lambda.min
> bestlam
[] 238.0769
>
> predict(cv.out,type='coefficients',s=bestlam)
x sparse Matrix of class "dgCMatrix" (Intercept) 10.35569016
AtBat 0.04633830
Hits 0.96376522
HmRun 0.27163149
Runs 1.10118079
RBI 0.87606196
Walks 1.75331031
Years 0.50454900
CAtBat 0.01124891
CHits 0.06274116
CHmRun 0.43896753
CRuns 0.12471202
CRBI 0.13253839
CWalks 0.03672947
LeagueN 25.75710229
DivisionW -88.36043520
PutOuts 0.18483877
Assists 0.03847012
Errors -1.68470904
NewLeagueN 7.91725602
>
> #交叉验证的Lasso回归
> cv.outlas<-cv.glmnet(x,y,alpha=)
> plot(cv.outlas)
> bestlam<-cv.outlas$lambda.min
> bestlam
[] 2.935124
> predict(cv.outlas,type='coefficients',s=bestlam)
x sparse Matrix of class "dgCMatrix" (Intercept) 117.5258439
AtBat -1.4742901
Hits 5.4994256
HmRun .
Runs .
RBI .
Walks 4.5991651
Years -9.1918308
CAtBat .
CHits .
CHmRun 0.4806743
CRuns 0.6354799
CRBI 0.3956153
CWalks -0.4993240
LeagueN 31.6238174
DivisionW -119.2516409
PutOuts 0.2704287
Assists 0.1594997
Errors -1.9426357
NewLeagueN .
>
ISLR系列:(4.2)模型选择 Ridge Regression & the Lasso的更多相关文章
- 机器学习方法:回归(二):稀疏与正则约束ridge regression,Lasso
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. "机器学习方法"系列,我本着开放与共享(open and share)的精神撰写,目的是 ...
- ISLR系列:(4.1)模型选择 Subset Selection
Linear Model Selection and Regularization 此博文是 An Introduction to Statistical Learning with Applicat ...
- ISLR系列:(4.3)模型选择 PCR & PLS
Linear Model Selection and Regularization 此博文是 An Introduction to Statistical Learning with Applicat ...
- 机器学习:模型泛化(岭回归:Ridge Regression)
一.基础理解 模型正则化(Regularization) # 有多种操作方差,岭回归只是其中一种方式: 功能:通过限制超参数大小,解决过拟合或者模型含有的巨大的方差误差的问题: 影响拟合曲线的两个因子 ...
- Spark2.0机器学习系列之2:基于Pipeline、交叉验证、ParamMap的模型选择和超参数调优
Spark中的CrossValidation Spark中采用是k折交叉验证 (k-fold cross validation).举个例子,例如10折交叉验证(10-fold cross valida ...
- [Machine Learning & Algorithm]CAML机器学习系列1:深入浅出ML之Regression家族
声明:本博客整理自博友@zhouyong计算广告与机器学习-技术共享平台,尊重原创,欢迎感兴趣的博友查看原文. 符号定义 这里定义<深入浅出ML>系列中涉及到的公式符号,如无特殊说明,符号 ...
- L1,L2范数和正则化 到lasso ridge regression
一.范数 L1.L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数. L0范数 表示向量xx中非零元素的个数. L1范数 表示向量中非零元素的绝对值之和. L2范数 表 ...
- 岭回归(Ridge Regression)
一.一般线性回归遇到的问题 在处理复杂的数据的回归问题时,普通的线性回归会遇到一些问题,主要表现在: 预测精度:这里要处理好这样一对为题,即样本的数量和特征的数量 时,最小二乘回归会有较小的方差 时, ...
- 线性回归——lasso回归和岭回归(ridge regression)
目录 线性回归--最小二乘 Lasso回归和岭回归 为什么 lasso 更容易使部分权重变为 0 而 ridge 不行? References 线性回归很简单,用线性函数拟合数据,用 mean squ ...
随机推荐
- iOS支付宝,微信,银联支付集成封装(上)
一.集成支付宝支付 支付宝集成官方教程https://docs.open.alipay.com/204/105295/ 支付宝集成官方demo https://docs.open.alipay.com ...
- Java中Semaphore(信号量)的使用
Semaphore的作用: 在java中,使用了synchronized关键字和Lock锁实现了资源的并发访问控制,在同一时间只允许唯一了线程进入临界区访问资源(读锁除外),这样子控制的主要目的是为了 ...
- Ruby 2.x 命名参数特性简介
我以前曾有一个梦想,就是我的爹是李嘉诚-,那个-,不是啦,我的梦想是ruby像ObjC,或是现在的swift那样给方法提供命名参数. 之前的ruby只能用hash来模拟这个行为,不过你没法很容易的定义 ...
- 在Spring Boot中使用数据库事务
我们在前面已经分别介绍了如何在Spring Boot中使用JPA(初识在Spring Boot中使用JPA)以及如何在Spring Boot中输出REST资源(在Spring Boot中输出REST资 ...
- 用豆瓣镜像解决pip安装慢的问题
pip3 install django==1.9 -i http://pypi.douban.com/simple/
- javaweb异常提示信息统一处理(使用springmvc,附源码)
一.前言 后台出现异常如何友好而又高效地回显到前端呢?直接将一堆的错误信息抛给用户界面,显然不合适. 先不考虑代码实现,我们希望是这样的: (1)如果是页面跳转的请求,出现异常了,我们希望跳转到一个异 ...
- Swift类型推测在可选调用中的小提示
我们知道Swift中协议里也有对应于Objc中的可选方法或计算属性,当然协议必须以@objc伪指令修饰否则不可以哦. 如下示例: @objc protocol Transaction{ fun com ...
- iOS学习笔记--数据存储
iOS应用数据存储的常用方式 XML属性列表(plist)归档 Preference(偏好设置) NSKeyedArchiver归档(NSCoding) SQLite3 Core Data 1. XM ...
- 用Python最原始的函数模拟eval函数的浮点数运算功能(2)
这应该是我编程以来完成的难度最大的一个函数了.因为可能存在的情况非常多,需要设计合理的参数来控制解析流程.经验概要: 1.大胆假设一些子功能能够实现,看能否建立整个框架.如果在假设的基础上都无法建立, ...
- Servlet - Upload、Download、Async、动态注册
Servlet 标签 : Java与Web Upload-上传 随着3.0版本的发布,文件上传终于成为Servlet规范的一项内置特性,不再依赖于像Commons FileUpload之类组件,因此在 ...