JDK源码分析(2)之 Array 相关
在深入了解 Array 之前,一直以为 Array 比较简单,但是深入了解后才发现其实挺复杂的。所以我把重要的写在最前面,但凡遇到和语言本身相关的问题,都可以查阅 Java Language and Virtual Machine Specifications
一、Array 是一个是对象吗?
首先可以肯定的是,数组是一个对象;但是在推导的过程中还是有些难以理解的问题,比如对于任意一个引用对象A,
- 数组是协变的,所以
Object[]是A[]的父类,即Object[] o = A[]; - 数组是一个对象,所以数组的父类是
Object,即Object oo = o; - 那么
A[]、Object[]和Object是什么关系呢?
是这样吗?
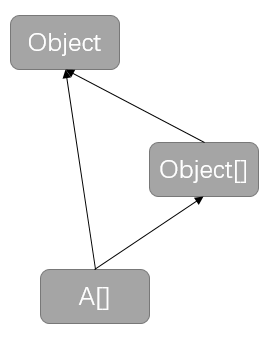
我们可以通过反射来观察一下:
private static void test05() {
Object[] o = new String[2];
System.out.println(o.getClass().getName());
System.out.println(o.getClass().getSuperclass().getName());
String[] s = (String[]) o;
System.out.println(s.getClass().getSuperclass().getName());
Object oo = s;
}
打印:
[Ljava.lang.String;
java.lang.Object
java.lang.Object
可以看见A[]和Object[]的直接父类都是Object,所以他们之间的关系也一定不是上图中的多继承关系,那么数组协变产生的关系一定不同于extends关键字产生的关系;
extends关键字产生的继承关系是怎么定义呢?
这里我们可以从《Virtual Machine Specifications》中找到答案:
// ClassFile 结构
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attribute_count;
attributes_info; attributes[attributes_count];
}
可以看到extends关键字产生的继承关系是记录在class文件中的super_class里面的。我这里还没有在 JDK 源码里面找到数组协变关系的产生,但是可以猜想这个应该是后来加的类似语法关系的结构。这里先留着以后看源码的时候确认吧。
二、Array 的 length 域相关
在准备看Array源码的时候,我直接就点开了java.lang.reflect.Array,后来才知道这根本不是Array的源码,看包名就知道,这是使用反射操作数组的一些方法。Array的class是在运行过程中动态生成的。
那么在Array的class中到底包含了什么呢?在很多的资料中都写了,Array中有类似public final int length的成员变量。但是在《Java Language Specifications》10.1. Array Types中明确写了,length不是类型的一部分;
- An array's length is not part of its type.
private static void test06() {
String[] s = new String[2];
System.out.println(s.length);
System.out.println(s.getClass().getDeclaredFields().length);
try {
System.out.println(s.getClass().getDeclaredField("length"));
} catch (NoSuchFieldException e) {
System.out.println(e.toString());
}
}
打印:
2
0
java.lang.NoSuchFieldException: length
可以看到length并不是Array的成员变量,那么length是从哪里来的呢?
同样我们可以从ClassFile结构中找打答案;
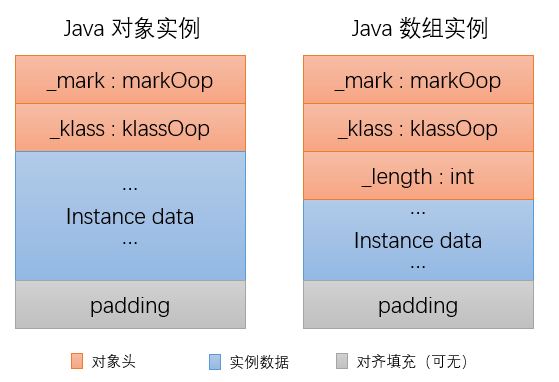
可以看到Array的length信息是记录在对象头中的,而读取length信息的时候,是使用的arraylength字节码指令来读取的。
三、Array 的创建流程
// 数组创建的几种形式
String[] s = {"a", "b", "c"}; // 初始化器
String[] s1 = new String[3]; // 有维度表达式
String[] s2 = (String[]) Array.newInstance(String.class, 3); // 有维度表达式
数组创建流程
是否有维度表达式:
无:
创建的时候每个元素递归深入初始化,失败则退出
变量类型检查 -> 与数组类型不兼容 -> 编译错误
不是可具化类型(如:null) -> 编译错误
空间不足 -> OutOfMemoryError
有:
创建的时候,从左向右地计算,任意维度表达式计算失败则退出
检查所有维度值,有小于0 -> NegativeArraySizeException
分配空间,若空间不足 -> OutOfMemoryError
只有一个维度表达式,创建一维数组,每个元素初始化化为初始值
有n个维度表达式,执行深度为n-1的循环
四、协变数组
1. 逆变与协变
逆变与协变用来描述类型转换(type transformation)后的继承关系
如果A、B表示类型,f(⋅)表示类型转换,≤表示继承关系(比如,A≤B表示A是由B派生出来的子类)
- f(⋅)是逆变的,当A≤B时有f(B)≤f(A)成立;
- f(⋅)是协变的,当A≤B时有f(A)≤f(B)成立;
- f(⋅)是不变的,当A≤B时上述两个式子均不成立,即f(A)与f(B)相互之间没有继承关系。
正因为数组是协变的,所以Object[] o = new A[];
2. 为什么要设计为协变数组
有种看法认为这是在泛型产生之前的妥协产物,比如在 JDK5 之前还没有泛型,但是很多地方需要用泛型来解决,比如:
// java.util.Arrays
public static boolean equals(Object[] a, Object[] a2) {
if (a==a2)
return true;
if (a==null || a2==null)
return false;
int length = a.length;
if (a2.length != length)
return false;
for (int i=0; i<length; i++) {
Object o1 = a[i];
Object o2 = a2[i];
if (!(o1==null ? o2==null : o1.equals(o2)))
return false;
}
return true;
}
最后调用的是Object.equals()方法,但是不想全部都重写equals,这里最简单的就是让数组实现协变的特性;
3. 为什么不能使用泛型数组
这里简单的讲是因为泛型是不变的,而数组是协变的,所以不能使用泛型数组;
// 如果泛型也是协变的
private static void test07() {
List<Object> list = new ArrayList<String>(); // 原本会编译出错
list.add(123);
List<String> list1 = list;
String s = list1.get(0); // 类型错误
}
可以看到如果泛型也是协变的,那么Collection 在存取数据的时候,就会产生类型转换错误;
4. 为什么数组可以是协变的
private static void test07() {
Object[] o = new String[2];
o[0] = 123;
}
运行时:
Exception in thread "main" java.lang.ArrayStoreException: java.lang.Integer
可以看到数组,在存数据的时候,还会检查数据类型是否兼容,所以数组可以是协变的。
五、数组在 java 和 c++ 中的区别
- C++ 中的数组只是一个指针,java 中的数组是一个对象
- java 中访问数组会有额外的范围检查
- java 中会确保数组被初始化
六、Array 和 ArrayList的效率对比
private static final int SIZE = 50000;
private static final Random RANDOM = new Random();
private static void test_array() {
System.out.println("Array:");
long start = System.currentTimeMillis();
String[] s = new String[SIZE];
for (int i = 0; i < SIZE; i++) {
s[i] = i + "";
}
System.out.println("insert:" + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
for (int i = 0, len = SIZE * 10; i < len; i++) {
String ss = s[RANDOM.nextInt(SIZE)];
}
System.out.println("get:" + (System.currentTimeMillis() - start));
}
private static void test_list() {
System.out.println("ArrayList:");
long start = System.currentTimeMillis();
List<String> list = new ArrayList<>(SIZE);
for (int i = 0; i < SIZE; i++) {
list.add(i + "");
}
System.out.println("insert:" + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
for (int i = 0, len = SIZE * 10; i < len; i++) {
String s = list.get(RANDOM.nextInt(SIZE));
}
System.out.println("get:" + (System.currentTimeMillis() - start));
}
打印:
Array:
insert:13
get:10
ArrayList:
insert:7
get:22
对比可以看到,数组的插入和随机访问效率都要比ArrayList高,但是一般建议优先使用列表,只有在优先考虑效率的时候才考虑使用数组,因为
- 数组是协变的不能使用泛型
- 数组是具体化的,只有在运行时才知道元素的类型
七、总结
在看数组的时候,因为class是动态创建的,所以看了很久,但是根据数组的特性,基本可以认为数组的域和方法,类似于:
class A<T> implements Cloneable, java.io.Serializable {
public final int length = X;
public T[] clone() {
try {
return (T[]) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError(e.getMessage());
}
}
}
JDK源码分析(2)之 Array 相关的更多相关文章
- JDK源码分析(三)—— LinkedList
参考文档 JDK源码分析(4)之 LinkedList 相关
- JDK源码分析(一)—— String
dir 参考文档 JDK源码分析(1)之 String 相关
- 【JDK】JDK源码分析-HashMap(1)
概述 HashMap 是 Java 开发中最常用的容器类之一,也是面试的常客.它其实就是前文「数据结构与算法笔记(二)」中「散列表」的实现,处理散列冲突用的是“链表法”,并且在 JDK 1.8 做了优 ...
- 【JDK】JDK源码分析-TreeMap(2)
前文「JDK源码分析-TreeMap(1)」分析了 TreeMap 的一些方法,本文分析其中的增删方法.这也是红黑树插入和删除节点的操作,由于相对复杂,因此单独进行分析. 插入操作 该操作其实就是红黑 ...
- 【JDK】JDK源码分析-Vector
概述 上文「JDK源码分析-ArrayList」主要分析了 ArrayList 的实现原理.本文分析 List 接口的另一个实现类:Vector. Vector 的内部实现与 ArrayList 类似 ...
- 【JDK】JDK源码分析-ArrayList
概述 ArrayList 是 List 接口的一个实现类,也是 Java 中最常用的容器实现类之一,可以把它理解为「可变数组」. 我们知道,Java 中的数组初始化时需要指定长度,而且指定后不能改变. ...
- 【JDK】JDK源码分析-List, Iterator, ListIterator
List 是最常用的容器之一.之前提到过,分析源码时,优先分析接口的源码,因此这里先从 List 接口分析.List 方法列表如下: 由于上文「JDK源码分析-Collection」已对 Collec ...
- 【JDK】JDK源码分析-AbstractQueuedSynchronizer(2)
概述 前文「JDK源码分析-AbstractQueuedSynchronizer(1)」初步分析了 AQS,其中提到了 Node 节点的「独占模式」和「共享模式」,其实 AQS 也主要是围绕对这两种模 ...
- 【JDK】JDK源码分析-AbstractQueuedSynchronizer(3)
概述 前文「JDK源码分析-AbstractQueuedSynchronizer(2)」分析了 AQS 在独占模式下获取资源的流程,本文分析共享模式下的相关操作. 其实二者的操作大部分是类似的,理解了 ...
- 【JDK】JDK源码分析-ReentrantLock
概述 在 JDK 1.5 以前,锁的实现只能用 synchronized 关键字:1.5 开始提供了 ReentrantLock,它是 API 层面的锁.先看下 ReentrantLock 的类签名以 ...
随机推荐
- 【英国毕业原版】-《伯明翰城市大学毕业证书》BCU一模一样原件
☞伯明翰城市大学毕业证书[微/Q:865121257◆WeChat:CC6669834]UC毕业证书/联系人Alice[查看点击百度快照查看][留信网学历认证&博士&硕士&海归 ...
- Keras框架简介
Keras是基于Theano的一个深度学习框架,它的设计参考了Torch,用Python语言编写,是一个高度模块化的神经网络库,支持GPU和CPU.使用文档在这:http://keras.io/,中文 ...
- Typora + Mathpix Snip,相见恨晚的神器
word 文档虽然很好,但当我需要输入一大堆公式的时候,word 公式让我疯狂. Why markdown?首先,GitHub 上都在用,那我也得会吧,不然 README.md 怎么写:其次,mark ...
- 实战经验丨CTF中文件包含的技巧总结
站在巨人的肩头才会看见更远的世界,这是一篇技术牛人对CTF比赛中文件包含的内容总结,主要是对一些包含点的原理和特征进行归纳分析,并结合实际的例子来讲解如何绕过,全面细致,通俗易懂,掌握这个新技能定会让 ...
- :Android网络编程--XML之解析方式:SAX
任何放置在资源(res)目录下的内容可以通过应用程序的R类访问,这是被Android编译过的,而任何放置在资产(assets)目录下的内容会保持它的原始文件格式,为了读取它们,必须使用AssetMan ...
- elasticsearch6.6.2在Centos6.9的安装
JDK8 做个记录,以防以后忘记能够查看. 1.elastic是java编写的,先搭建运行环境,6.6.2版本必须要jdk8以上版本才可运行,先官网下载jdk,上传服务器 https://www.or ...
- Vue 进阶之路(二)
之前的文章我们初识了 vue,对其原理,数据绑定和方法进行了简单的演示,本篇将对 vue 插值表达式,v-text,v-html 进行讲解. <!DOCTYPE html> <htm ...
- Ubuntu命令用法详解——curl命令
简介: cURL(CommandLine Uniform Resource Locator)是一个利用URL语法在命令行下工作的文件传输工具,1997年首次发行.它支持文件上传和下载,所以是综合传输工 ...
- python——绘制二元高斯分布的三维图像,
在对数据进行可视化的过程中,可能经常需要对数据进行三维绘图,在python中进行三维绘图其实是比较简单的,下面我们将给出一个二元高斯分布的三维图像案例,并且给出相关函数的参数. 通常,我们绘制三维图像 ...
- asp.net core 系列之webapi集成EFCore的简单操作教程
因为官网asp.net core webapi教程部分,给出的是使用内存中的数据即 UseInMemoryDatabase 的方式, 这里记录一下,使用SQL Server数据库的方式即 UseSql ...