机器学习之支持向量机—SVM原理代码实现
支持向量机—SVM原理代码实现
本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/9596898.html
1. 解决什么问题?
最基本的应用是数据分类,特别是对于非线性不可分数据集。支持向量机不仅能对非线性可分数据集进行分类,对于非线性不可分数据集的也可以分类
(我认为这才是支持向量机的真正魅力所在,因为现实场景中,样本数据往往是线性不可分的)。
现实场景一 :样本数据大部分是线性可分的,但是只是在样本中含有少量噪声或特异点,去掉这些噪声或特异点后线性可分 => 用支持向量机的软间隔方法进行分类;
现实场景二:样本数据完全线性不可分 => 引入核函数,将低维不可分的非线性数据集转化为高维可分的数据集,用支持向量机的软间隔方法进行分类;

一定要明白一点:对分类器准确性有影响只是样本中的支持向量,因此,其他样本在计算分类器的权重矩阵时可以直接过滤掉,大大节省运行时间。
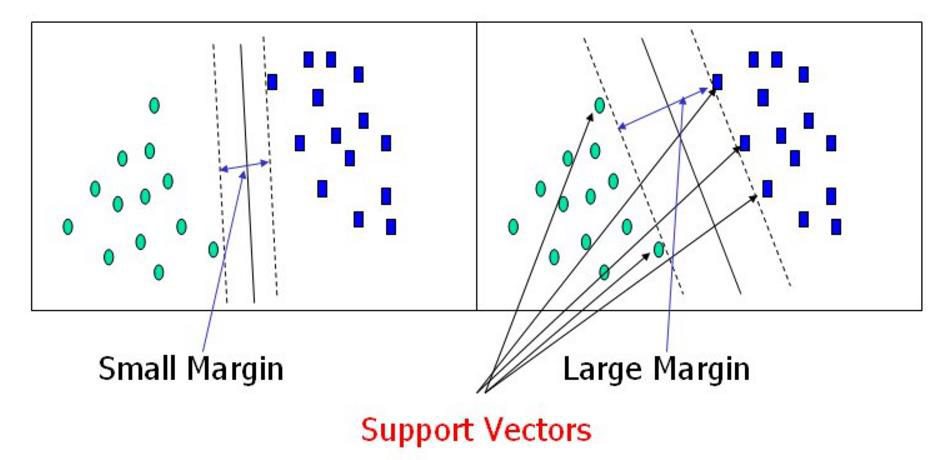
目标:获取离边界最近样本点到超平面最远距离
2. SVM的思想演化?
博客 https://www.cnblogs.com/zhizhan/p/4430253.html 关于SVM的演化说得很透彻,也很形象,这里借用一下。
2.1 硬间隔支持向量机
SVM中最关键的思想之一就是引入和定义了“间隔”这个概念。这个概念本身很简单,以二维空间为例,就是点到分类直线之间的距离。假设直线为y=wx+b,那么只要使所有正分类点到该直线的距离与所有负分类点到该直线的距离的总和达到最大,这条直线就是最优分类直线。这样,原问题就转化为一个约束优化问题,可以直接求解。这叫做硬间隔最大化,得到的SVM模型称作硬间隔支持向量机。
2.2 软间隔支持向量机
但是新问题出现了,在实际应用中,我们得到的数据并不总是完美的线性可分的,其中可能会有个别噪声点,他们错误的被分类到了其他类中。如果将这些特异的噪点去除后,可以很容易的线性可分。但是,我们对于数据集中哪些是噪声点却是不知道的,如果以之前的方法进行求解,会无法进行线性分开。是不是就没办法了呢?假设在y=x+1直线上下分为两类,若两类中各有对方的几个噪点,在人的眼中,仍然是可以将两类分开的。这是因为在人脑中是可以容忍一定的误差的,仍然使用y=x+1直线分类,可以在最小误差的情况下进行最优的分类。同样的道理,我们在SVM中引入误差的概念,将其称作“松弛变量”。通过加入松弛变量,在原距离函数中需要加入新的松弛变量带来的误差,这样,最终的优化目标函数变成了两个部分组成:距离函数和松弛变量误差。这两个部分的重要程度并不是相等的,而是需要依据具体问题而定的,因此,我们加入权重参数C,将其与目标函数中的松弛变量误差相乘,这样,就可以通过调整C来对二者的系数进行调和。如果我们能够容忍噪声,那就把C调小,让他的权重降下来,从而变得不重要;反之,我们需要很严格的噪声小的模型,则将C调大一点,权重提升上去,变得更加重要。通过对参数C的调整,可以对模型进行控制。这叫做软间隔最大化,得到的SVM称作软间隔支持向量机。
2.3 非线性支持向量机
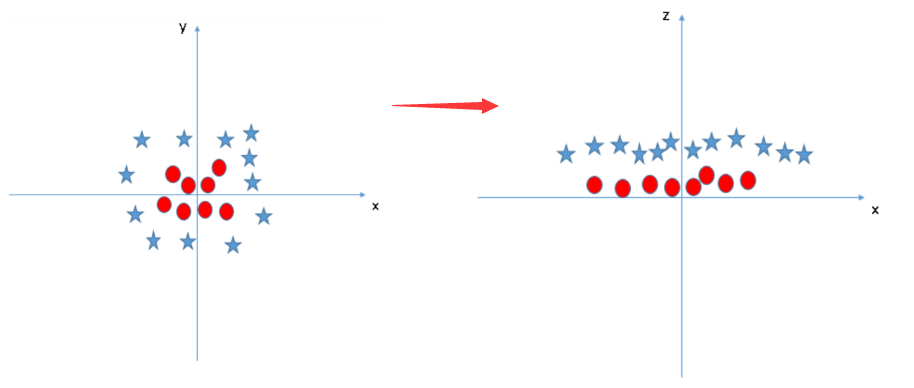
之前的硬间隔支持向量机和软间隔支持向量机都是解决线性可分数据集或近似线性可分数据集的问题的。但是如果噪点很多,甚至会造成数据变成了线性不可分的,那该怎么办?最常见的例子是在二维平面笛卡尔坐标系下,以原点(0,0)为圆心,以1为半径画圆,则圆内的点和圆外的点在二维空间中是肯定无法线性分开的。但是,学过初中几何就知道,对于圆圈内(含圆圈)的点:x^2+y^2≤1,圆圈外的则x^2+y^2>1。我们假设第三个维度:z=x^2+y^2,那么在第三维空间中,可以通过z是否大于1来判断该点是否在圆内还是圆外。这样,在二维空间中线性不可分的数据在第三维空间很容易的线性可分了。这就是非线性支持向量机。
实际中,对某个实际问题函数来寻找一个合适的空间进行映射是非常困难的,幸运的是,在计算中发现,我们需要的只是两个向量在新的映射空间中的内积结果,而映射函数到底是怎么样的其实并不需要知道。这一点不太好理解,有人会问,既然不知道映射函数,那怎么能知道映射后在新空间中的内积结果呢?答案其实是可以的。这就需要引入了核函数的概念。核函数是这样的一种函数:仍然以二维空间为例,假设对于变量x和y,将其映射到新空间的映射函数为φ,则在新空间中,二者分别对应φ(x)和φ(y),他们的内积则为<φ(x),φ(y)>。我们令函数Kernel(x,y)=<φ(x),φ(y)>=k(x,y),可以看出,函数Kernel(x,y)是一个关于x和y的函数!而与φ无关!这是一个多么好的性质!我们再也不用管φ具体是什么映射关系了,只需要最后计算Kernel(x,y)就可以得到他们在高维空间中的内积,这样就可以直接带入之前的支持向量机中计算!
核函数不是很好找到,一般是由数学家反向推导出来或拼凑出来的。现在知道的线性核函数有多项式核函数、高斯核函数等。其中,高斯核函数对应的支持向量机是高斯径向基函数(RBF),是最常用的核函数。

RBF核函数可以将维度扩展到无穷维的空间,因此,理论上讲可以满足一切映射的需求。为什么会是无穷维呢?我以前都不太明白这一点。后来老师讲到,RBF对应的是泰勒级数展开,在泰勒级数中,一个函数可以分解为无穷多个项的加和,其中,每一个项可以看做是对应的一个维度,这样,原函数就可以看做是映射到了无穷维的空间中。这样,在实际应用中,RBF是相对最好的一个选择。当然,如果有研究的话,还可以选用其他核函数,可能会在某些问题上表现更好。但是,RBF是在对问题不了解的情况下,对最广泛问题效果都很不错的核函数。因此,使用范围也最广。
3. SVM原理
3.1 目标函数
求使几何间隔最大的分离超平面
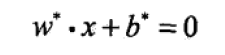
以及相应的分类决策函数
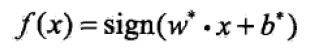
也就是求出w,b
3.2 几何间隔定义
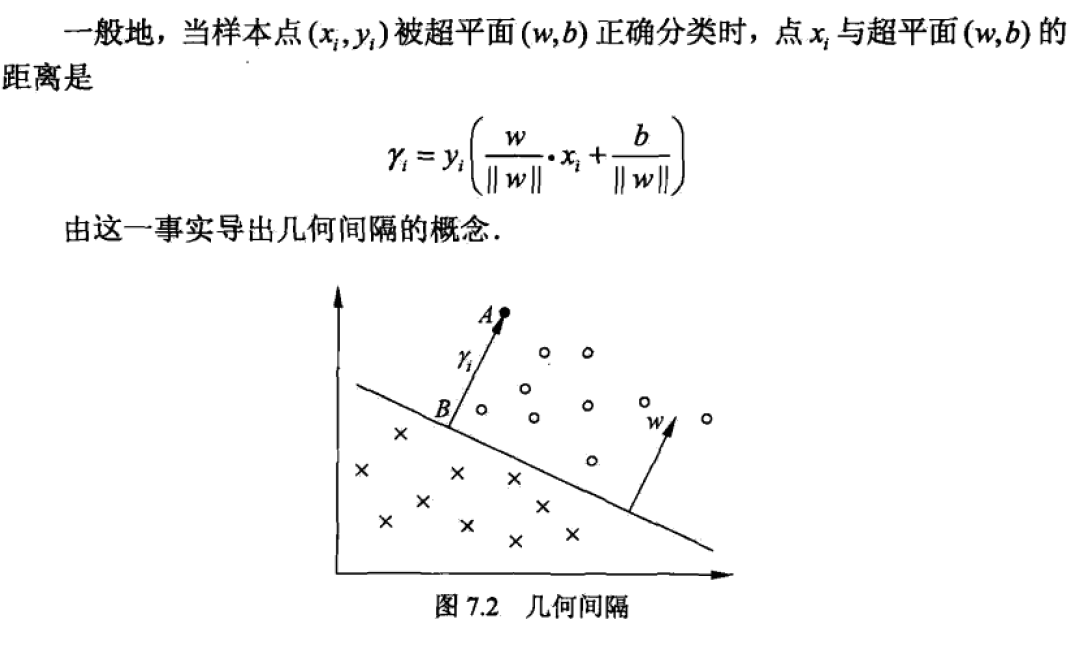
3.3 学习的对偶算法
为了求解线性可分支持向量机的最优化问题,将它作为原始最优化问题,应用拉格朗日对偶性,通过求解对偶问题得到原始问题最优解。
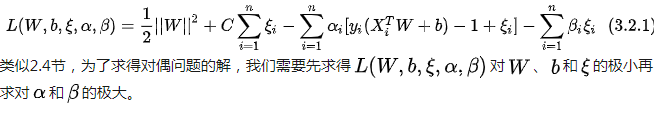
3.4 最大软间隔分类器(线性可分支持向量学习的最优化问题)
这就是线性可分支持向量机的对偶算法,这样做的优点,一是对偶问题往往更容易求解;二是自然引入核函数,进而推广到非线性分类问题。

的求解就转化为
的求解。上述公式就是对不同变量求偏导,具体推导过程见《统计学习方法》第7章 或者相关博客。
3.5 KKT条件
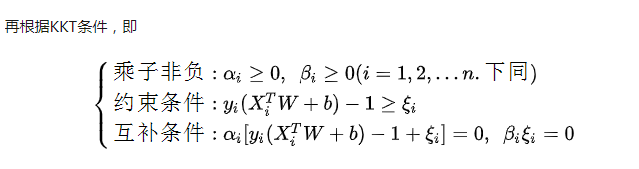
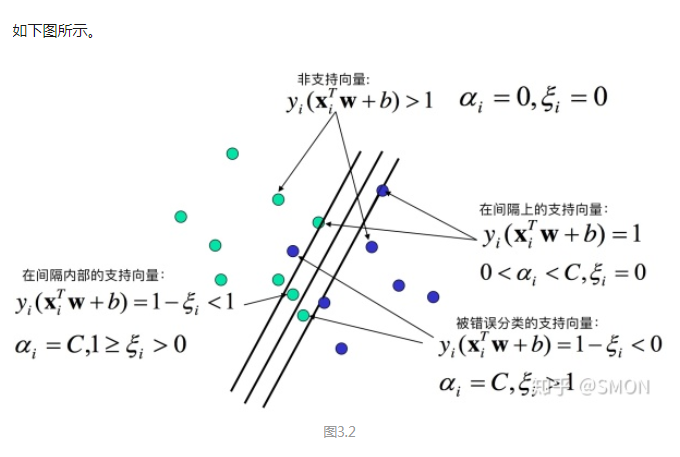
上图的总结有点小问题,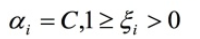 分类不能合并,正确的分类描述应该是:
分类不能合并,正确的分类描述应该是:

在超平面上或误分的样本点是不能正确分类的。
4. SMO算法(sequential minimal optimization 序列最小最优化)
高效实现支持向量机的算法是SMO算法,其基本思路是:如果所有变量的解都满足此最优化的KKT条件,那么这个最优化问题的解就得到了。因为KKT条件是该优化问题的充分必要条件。否则,
选择两个变量,固定其他变量,针对这两个变量构建一个二次规划问题,这个二次规划问题关于这两个变量的解应该更接近原始二次规划问题的解,因为这会使原始二次规划问题的目标函数值变得更小。
重要的是,这时子问题可以通过解析方法求解,这样可以大大提高整个算法的计算速度。
子问题有两个变量,一个是违反KKT条件最严重的那一个,另一个由约束条件自动确定。如此,SMO算法将原问题不断分解为子问题并对子问题求解,进而达到求解原问题的目的。
由
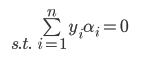
并且 推出

4.1 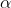 范围
范围
由
假定不固定,其他拉格朗日因子固定(也就是常量),得到
常量 ,
为变量,
为因变量,L,H的范围就是
的 范围
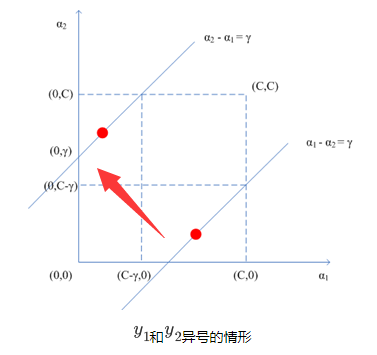

4.2 计算拉格朗日乘子  ,
,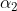
第一个 公式如下,推导过程见《统计学习方法》第7章或者相关博客。
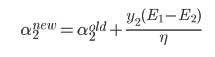

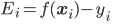
选择一个违背KKT的数据项,根据下面结论得到优化后 ,

s表示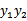 ,从而可以得到另一个优化后的
,从而可以得到另一个优化后的 ,同样也需要进行约束。
4.3 计算b1,b2
在每次完成两个变量的优化后,都要重新计算阈值b。具体推导见《统计学习方法》
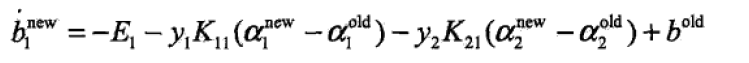
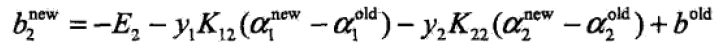
5. 代码实现
5.1 输入数据
这里使用两个原始数据文件 trainingData.txt,testData.txt。
trainingData.txt
-0.214824 0.662756 -1.000000
-0.061569 -0.091875 1.000000
0.406933 0.648055 -1.000000
0.223650 0.130142 1.000000
0.231317 0.766906 -1.000000
-0.748800 -0.531637 -1.000000
-0.557789 0.375797 -1.000000
0.207123 -0.019463 1.000000
0.286462 0.719470 -1.000000
0.195300 -0.179039 1.000000
-0.152696 -0.153030 1.000000
0.384471 0.653336 -1.000000
-0.117280 -0.153217 1.000000
-0.238076 0.000583 1.000000
-0.413576 0.145681 1.000000
0.490767 -0.680029 -1.000000
0.199894 -0.199381 1.000000
-0.356048 0.537960 -1.000000
-0.392868 -0.125261 1.000000
0.353588 -0.070617 1.000000
0.020984 0.925720 -1.000000
-0.475167 -0.346247 -1.000000
0.074952 0.042783 1.000000
0.394164 -0.058217 1.000000
0.663418 0.436525 -1.000000
0.402158 0.577744 -1.000000
-0.449349 -0.038074 1.000000
0.619080 -0.088188 -1.000000
0.268066 -0.071621 1.000000
-0.015165 0.359326 1.000000
0.539368 -0.374972 -1.000000
-0.319153 0.629673 -1.000000
0.694424 0.641180 -1.000000
0.079522 0.193198 1.000000
0.253289 -0.285861 1.000000
-0.035558 -0.010086 1.000000
-0.403483 0.474466 -1.000000
-0.034312 0.995685 -1.000000
-0.590657 0.438051 -1.000000
-0.098871 -0.023953 1.000000
-0.250001 0.141621 1.000000
-0.012998 0.525985 -1.000000
0.153738 0.491531 -1.000000
0.388215 -0.656567 -1.000000
0.049008 0.013499 1.000000
0.068286 0.392741 1.000000
0.747800 -0.066630 -1.000000
0.004621 -0.042932 1.000000
-0.701600 0.190983 -1.000000
0.055413 -0.024380 1.000000
0.035398 -0.333682 1.000000
0.211795 0.024689 1.000000
-0.045677 0.172907 1.000000
0.595222 0.209570 -1.000000
0.229465 0.250409 1.000000
-0.089293 0.068198 1.000000
0.384300 -0.176570 1.000000
0.834912 -0.110321 -1.000000
-0.307768 0.503038 -1.000000
-0.777063 -0.348066 -1.000000
0.017390 0.152441 1.000000
-0.293382 -0.139778 1.000000
-0.203272 0.286855 1.000000
0.957812 -0.152444 -1.000000
0.004609 -0.070617 1.000000
-0.755431 0.096711 -1.000000
-0.526487 0.547282 -1.000000
-0.246873 0.833713 -1.000000
0.185639 -0.066162 1.000000
0.851934 0.456603 -1.000000
-0.827912 0.117122 -1.000000
0.233512 -0.106274 1.000000
0.583671 -0.709033 -1.000000
-0.487023 0.625140 -1.000000
-0.448939 0.176725 1.000000
0.155907 -0.166371 1.000000
0.334204 0.381237 -1.000000
0.081536 -0.106212 1.000000
0.227222 0.527437 -1.000000
0.759290 0.330720 -1.000000
0.204177 -0.023516 1.000000
0.577939 0.403784 -1.000000
-0.568534 0.442948 -1.000000
-0.011520 0.021165 1.000000
0.875720 0.422476 -1.000000
0.297885 -0.632874 -1.000000
-0.015821 0.031226 1.000000
0.541359 -0.205969 -1.000000
-0.689946 -0.508674 -1.000000
-0.343049 0.841653 -1.000000
0.523902 -0.436156 -1.000000
0.249281 -0.711840 -1.000000
0.193449 0.574598 -1.000000
-0.257542 -0.753885 -1.000000
-0.021605 0.158080 1.000000
0.601559 -0.727041 -1.000000
-0.791603 0.095651 -1.000000
-0.908298 -0.053376 -1.000000
0.122020 0.850966 -1.000000
-0.725568 -0.292022 -1.000000
原始训练数据
testData.txt
3.542485 1.977398 -
3.018896 2.556416 -
7.551510 -1.580030
2.114999 -0.004466 -
8.127113 1.274372
7.108772 -0.986906
8.610639 2.046708
2.326297 0.265213 -
3.634009 1.730537 -
0.341367 -0.894998 -
3.125951 0.293251 -
2.123252 -0.783563 -
0.887835 -2.797792 -
7.139979 -2.329896
1.696414 -1.212496 -
8.117032 0.623493
8.497162 -0.266649
4.658191 3.507396 -
8.197181 1.545132
1.208047 0.213100 -
1.928486 -0.321870 -
2.175808 -0.014527 -
7.886608 0.461755
3.223038 -0.552392 -
3.628502 2.190585 -
7.407860 -0.121961
7.286357 0.251077
2.301095 -0.533988 -
-0.232542 -0.547690 -
3.457096 -0.082216 -
3.023938 -0.057392 -
8.015003 0.885325
8.991748 0.923154
7.916831 -1.781735
7.616862 -0.217958
2.450939 0.744967 -
7.270337 -2.507834
1.749721 -0.961902 -
1.803111 -0.176349 -
8.804461 3.044301
1.231257 -0.568573 -
2.074915 1.410550 -
-0.743036 -1.736103 -
3.536555 3.964960 -
8.410143 0.025606
7.382988 -0.478764
6.960661 -0.245353
8.234460 0.701868
8.168618 -0.903835
1.534187 -0.622492 -
9.229518 2.066088
7.886242 0.191813
2.893743 -1.643468 -
1.870457 -1.040420 -
5.286862 -2.358286
6.080573 0.418886
2.544314 1.714165 -
6.016004 -3.753712
0.926310 -0.564359 -
0.870296 -0.109952 -
2.369345 1.375695 -
1.363782 -0.254082 -
7.279460 -0.189572
1.896005 0.515080 -
8.102154 -0.603875
2.529893 0.662657 -
1.963874 -0.365233 -
8.132048 0.785914
8.245938 0.372366
6.543888 0.433164
-0.236713 -5.766721 -
8.112593 0.295839
9.803425 1.495167
1.497407 -0.552916 -
1.336267 -1.632889 -
9.205805 -0.586480
1.966279 -1.840439 -
8.398012 1.584918
7.239953 -1.764292
7.556201 0.241185
9.015509 0.345019
8.266085 -0.230977
8.545620 2.788799
9.295969 1.346332
2.404234 0.570278 -
2.037772 0.021919 -
1.727631 -0.453143 -
1.979395 -0.050773 -
8.092288 -1.372433
1.667645 0.239204 -
9.854303 1.365116
7.921057 -1.327587
8.500757 1.492372
1.339746 -0.291183 -
3.107511 0.758367 -
2.609525 0.902979 -
3.263585 1.367898 -
2.912122 -0.202359 -
1.731786 0.589096 -
2.387003 1.573131 -
原始测试数据
5.2 SMO算法实现
定义数据结构体optStruct,用于缓存,提高运行速度。SMO算法具体实现如下(mySVMMLiA.py)
每个方法的作用,以及每行代码的作用,我都做了详细的注解,希望对大家的理解有帮助。
# -*- coding: utf-8 -*-
"""
Created on Tue Sep 4 16:58:16 2018
支持向量机代码实现
SMO(Sequential Minimal Optimization)最小序列优化
@author: weixw
"""
import numpy as np
#核转换函数(一个特征空间映射到另一个特征空间,低维空间映射到高维空间)
#高维空间解决线性问题,低维空间解决非线性问题
#线性内核 = 原始数据矩阵(100*2)与原始数据第一行矩阵转秩乘积(2*1) =>(100*1)
#非线性内核公式:k(x,y) = exp(-||x - y||**2/2*(e**2))
#1.原始数据每一行与原始数据第一行作差,
#2.平方
def kernelTrans(dataMat, rowDataMat, kTup):
m,n=np.shape(dataMat)
#初始化核矩阵 m*1
K = np.mat(np.zeros((m,1)))
if kTup[0] == 'lin': #线性核
K = dataMat*rowDataMat.T
elif kTup[0] == 'rbf':#非线性核
for j in range(m):
#xi - xj
deltaRow = dataMat[j,:] - rowDataMat
K[j] = deltaRow*deltaRow.T
#1*m m*1 => 1*1
K = np.exp(K/(-2*kTup[1]**2))
else: raise NameError('Houston We Have a Problem -- That Kernel is not recognized')
return K #定义数据结构体,用于缓存,提高运行速度
class optStruct:
def __init__(self, dataSet, labelSet, C, toler, kTup):
self.dataMat = np.mat(dataSet) #原始数据,转换成m*n矩阵
self.labelMat = np.mat(labelSet).T #标签数据 m*1矩阵
self.C = C #惩罚参数,C越大,容忍噪声度小,需要优化;反之,容忍噪声度高,不需要优化;
#所有的拉格朗日乘子都被限制在了以C为边长的矩形里
self.toler = toler #容忍度
self.m = np.shape(self.dataMat)[0] #原始数据行长度
self.alphas = np.mat(np.zeros((self.m,1))) # alpha系数,m*1矩阵
self.b = 0 #偏置
self.eCache = np.mat(np.zeros((self.m,2))) # 保存原始数据每行的预测值
self.K = np.mat(np.zeros((self.m,self.m))) # 核转换矩阵 m*m
for i in range(self.m):
self.K[:,i] = kernelTrans(self.dataMat, self.dataMat[i,:], kTup) #计算原始数据第k项对应的预测误差 1*m m*1 =>1*1
#oS:结构数据
#k: 原始数据行索引
def calEk(oS, k):
#f(x) = w*x + b
fXk = float(np.multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek #在alpha有改变都要更新缓存
def updateEk(oS, k):
Ek = calEk(oS, k)
oS.eCache[k] = [1, Ek] #第一次通过selectJrand()随机选取j,之后选取与i对应预测误差最大的j(步长最大)
def selectJ(i, oS, Ei):
#初始化
maxK = -1 #误差最大时对应索引
maxDeltaE = 0 #最大误差
Ej = 0 # j索引对应预测误差
#保存每一行的预测误差值 1相对于初始化为0的更改
oS.eCache[i] = [1,Ei]
#获取数据缓存结构中非0的索引列表(先将矩阵第0列转化为数组)
validEcacheList = np.nonzero(oS.eCache[:,0].A)[0]
#遍历索引列表,寻找最大误差对应索引
if len(validEcacheList) > 1:
for k in validEcacheList:
if k == i:
continue
Ek = calEk(oS, k)
deltaE = abs(Ei - Ek)
if(deltaE > maxDeltaE):
maxK = k
maxDeltaE = deltaE
Ej = Ek
return maxK, Ej
else:
#随机选取一个不等于i的j
j = selectJrand(i, oS.m)
Ej = calEk(oS, j)
return j,Ej #随机选取一个不等于i的索引
def selectJrand(i, m):
j = i
while (j == i):
j = int(np.random.uniform(0, m))
return j #alpha范围剪辑
def clipAlpha(aj, L, H):
if aj > H:
aj = H
if aj < L:
aj = L
return aj #从文件获取特征数据,标签数据
def loadDataSet(fileName):
dataSet = []; labelSet = []
fr = open(fileName)
for line in fr.readlines():
#分割
lineArr = line.strip().split('\t')
dataSet.append([float(lineArr[0]), float(lineArr[1])])
labelSet.append(float(lineArr[2]))
return dataSet, labelSet #计算 w 权重系数
def calWs(alphas, dataSet, labelSet):
dataMat = np.mat(dataSet)
#1*100 => 100*1
labelMat = np.mat(labelSet).T
m, n = np.shape(dataMat)
w = np.zeros((n, 1))
for i in range(m):
w += np.multiply(alphas[i]*labelMat[i], dataMat[i,:].T)
return w
#计算原始数据每一行alpha,b,保存到数据结构中,有变化及时更新
def innerL(i, oS):
#计算预测误差
Ei = calEk(oS, i)
#选择第一个alpha,违背KKT条件2
#正间隔,负间隔
if ((oS.labelMat[i] * Ei < -oS.toler) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i] * Ei > oS.toler) and (oS.alphas[i] > 0)):
#第一次随机选取不等于i的数据项,其后根据误差最大选取数据项
j, Ej = selectJ(i, oS, Ei)
#初始化,开辟新的内存
alphaIold = oS.alphas[i].copy()
alphaJold = oS.alphas[j].copy()
#通过 a1y1 + a2y2 = 常量
# 0 <= a1,a2 <= C 求出L,H
if oS.labelMat[i] != oS.labelMat[j]:
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L == H :
print ("L == H")
return 0
#内核分母 K11 + K22 - 2K12
eta = oS.K[i, i] + oS.K[j, j] - 2.0*oS.K[i, j]
if eta <= 0:
print ("eta <= 0")
return 0
#计算第一个alpha j
oS.alphas[j] += oS.labelMat[j]*(Ei - Ej)/eta
#修正alpha j的范围
oS.alphas[j] = clipAlpha(oS.alphas[j], L, H)
#alpha有改变,就需要更新缓存数据
updateEk(oS, j)
#如果优化后的alpha 与之前的alpha变化很小,则舍弃,并重新选择数据项的alpha
if (abs(oS.alphas[j] - alphaJold) < 0.00001):
print ("j not moving enough, abandon it.")
return 0
#计算alpha对的另一个alpha i
# ai_new*yi + aj_new*yj = 常量
# ai_old*yi + ai_old*yj = 常量
# 作差=> ai = ai_old + yi*yj*(aj_old - aj_new)
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])
#alpha有改变,就需要更新缓存数据
updateEk(oS, i)
#计算b1,b2
# y(x) = w*x + b => b = y(x) - w*x
# w = aiyixi(i= 1->N求和)
#b1_new = y1_new - (a1_new*y1*k11 + a2_new*y2*k21 + ai*yi*ki1(i = 3 ->N求和 常量))
#b1_old = y1_old - (a1_old*y1*k11 + a2_old*y2*k21 + ai*yi*ki1(i = 3 ->N求和 常量))
#作差=> b1_new = b1_old + (y1_new - y1_old) - y1*k11*(a1_new - a1_old) - y2*k21*(a2_new - a2_old)
# => b1_new = b1_old + Ei - yi*(ai_new - ai_old)*kii - yj*(aj_new - aj_old)*kij
#同样可推得 b2_new = b2_old + Ej - yi*(ai_new - ai_old)*kij - yj*(aj_new - aj_old)*kjj
bi = oS.b - Ei - oS.labelMat[i]*(oS.alphas[i] - alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j] - alphaJold)*oS.K[i,j]
bj = oS.b - Ej - oS.labelMat[i]*(oS.alphas[i] - alphaIold)*oS.K[i,j] - oS.labelMat[j]*(oS.alphas[j] - alphaJold)*oS.K[j,j]
#首选alpha i,相对alpha j 更准确
if (0 < oS.alphas[i]) and (oS.alphas[i] < oS.C):
oS.b = bi
elif (0 < oS.alphas[j]) and (oS.alphas[j] < oS.C):
oS.b = bj
else:
oS.b = (bi + bj)/2.0
return 1
else:
return 0 #完整SMO核心算法,包含线性核核非线性核,返回alpha,b
#dataSet 原始特征数据
#labelSet 标签数据
#C 凸二次规划参数
#toler 容忍度
#maxInter 循环次数
#kTup 指定核方式
#程序逻辑:
#第一次全部遍历,遍历后根据alpha对是否有修改判断,
#如果alpha对没有修改,外循环终止;如果alpha对有修改,则继续遍历属于支持向量的数据。
#直至外循环次数达到maxIter
#相比简单SMO算法,运行速度更快,原因是:
#1.不是每一次都全量遍历原始数据,第一次遍历原始数据,
#如果alpha有优化,就遍历支持向量数据,直至alpha没有优化,然后再转全量遍历,这是如果alpha没有优化,循环结束;
#2.外循环不需要达到maxInter次数就终止;
def smoP(dataSet, labelSet, C, toler, maxInter, kTup = ('lin', 0)):
#初始化结构体类,获取实例
oS = optStruct(dataSet, labelSet, C, toler, kTup)
iter = 0
#全量遍历标志
entireSet = True
#alpha对是否优化标志
alphaPairsChanged = 0
#外循环 终止条件:1.达到最大次数 或者 2.alpha对没有优化
while (iter < maxInter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
#全量遍历 ,遍历每一行数据 alpha对有修改,alphaPairsChanged累加
if entireSet:
for i in range(oS.m):
alphaPairsChanged += innerL(i, oS)
print ("fullSet, iter: %d i:%d, pairs changed %d" %(iter, i, alphaPairsChanged))
iter += 1
else:
#获取(0,C)范围内数据索引列表,也就是只遍历属于支持向量的数据
nonBounds = np.nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBounds:
alphaPairsChanged += innerL(i, oS)
print ("non-bound, iter: %d i:%d, pairs changed %d" %(iter, i, alphaPairsChanged))
iter += 1
#全量遍历->支持向量遍历
if entireSet:
entireSet = False
#支持向量遍历->全量遍历
elif alphaPairsChanged == 0:
entireSet = True
print ("iteation number: %d"% iter)
print ("entireSet :%s"% entireSet)
print ("alphaPairsChanged :%d"% alphaPairsChanged)
return oS.b,oS.alphas #绘制支持向量
def drawDataMap(dataArr,labelArr,b,alphas):
import matplotlib.pyplot as plt
#alphas.A>0 获取大于0的索引列表,只有>0的alpha才对分类起作用
svInd=np.nonzero(alphas.A>0)[0]
#分类数据点
classified_pts = {'+1':[],'-1':[]}
for point,label in zip(dataArr,labelArr):
if label == 1.0:
classified_pts['+1'].append(point)
else:
classified_pts['-1'].append(point)
fig = plt.figure()
ax = fig.add_subplot(111)
#绘制数据点
for label,pts in classified_pts.items():
pts = np.array(pts)
ax.scatter(pts[:, 0], pts[:, 1], label = label)
#绘制分割线
w = calWs(alphas, dataArr, labelArr)
#函数形式:max( x ,key=lambda a : b ) # x可以是任何数值,可以有多个x值
#先把x值带入lambda函数转换成b值,然后再将b值进行比较
x1, _=max(dataArr, key=lambda x:x[0])
x2, _=min(dataArr, key=lambda x:x[0])
a1, a2 = w
y1, y2 = (-b - a1*x1)/a2, (-b - a1*x2)/a2
#矩阵转化为数组.A
ax.plot([x1, x2],[y1.A[0][0], y2.A[0][0]]) #绘制支持向量
for i in svInd:
x, y= dataArr[i]
ax.scatter([x], [y], s=150, c ='none', alpha=0.7, linewidth=1.5, edgecolor = '#AB3319')
plt.show() #alpha>0对应的数据才是支持向量,过滤不是支持向量的数据
sVs= np.mat(dataArr)[svInd] #get matrix of only support vectors
print ("there are %d Support Vectors.\n" % np.shape(sVs)[0]) #训练结果
def getTrainingDataResult(dataSet, labelSet, b, alphas, k1=1.3):
datMat = np.mat(dataSet)
#100*1
labelMat = np.mat(labelSet).T
#alphas.A>0 获取大于0的索引列表,只有>0的alpha才对分类起作用
svInd=np.nonzero(alphas.A>0)[0]
sVs=datMat[svInd]
labelSV = labelMat[svInd];
m,n = np.shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
# y(x) = w*x + b => b = y(x) - w*x
# w = aiyixi(i= 1->N求和)
predict = kernelEval.T * np.multiply(labelSV, alphas[svInd]) + b
if np.sign(predict)!=np.sign(labelSet[i]): errorCount += 1
print ("the training error rate is: %f" % (float(errorCount)/m)) def getTestDataResult(dataSet, labelSet, b, alphas, k1=1.3):
datMat = np.mat(dataSet)
#100*1
labelMat = np.mat(labelSet).T
#alphas.A>0 获取大于0的索引列表,只有>0的alpha才对分类起作用
svInd=np.nonzero(alphas.A>0)[0]
sVs=datMat[svInd]
labelSV = labelMat[svInd];
m,n = np.shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
# y(x) = w*x + b => b = y(x) - w*x
# w = aiyixi(i= 1->N求和)
predict=kernelEval.T * np.multiply(labelSV,alphas[svInd]) + b
if np.sign(predict)!=np.sign(labelSet[i]): errorCount += 1
print ("the test error rate is: %f" % (float(errorCount)/m))
SMO算法实现
5.3 测试代码(testMySVMMLiA.py)
# -*- coding: utf-8 -*-
"""
Created on Wed Sep 5 15:22:26 2018 @author: weixw
""" import mySVMMLiA as sm #通过训练数据计算 b, alphas
dataArr,labelArr = sm.loadDataSet('trainingData.txt')
b, alphas = sm.smoP(dataArr, labelArr, 200, 0.0001, 10000, ('rbf', 0.10))
sm.drawDataMap(dataArr,labelArr,b,alphas)
sm.getTrainingDataResult(dataArr, labelArr, b, alphas, 0.10)
dataArr1,labelArr1 = sm.loadDataSet('testData.txt')
#测试结果
sm.getTestDataResult(dataArr1, labelArr1, b, alphas, 0.10)
测试代码
通过训练数据计算出 b, 权重矩阵,从而分类超平面和决策分类函数就明确了,然后测试数据以决策分类函数进行预测。
这里采用高斯核RBF。
5.4 运行结果

“j not moving enough, abandon it” 表示数据项对应的 和
非常接近,不需要优化;
“fullSet” 表示全量数据遍历;
“non-bound” 表示非边界遍历,也就是只遍历属于支持向量的数据项。
另外我将支持向量的数据项绘制出来了,这样更直观。
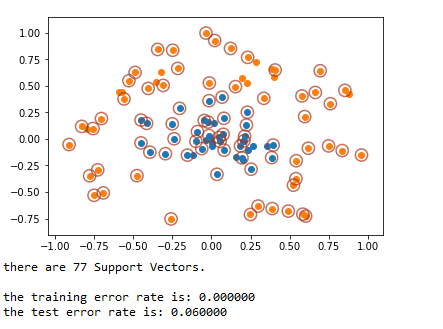
可以看出,有77个支持向量,训练差错率是0,测试差错率6%。
6. 参考文献
《统计学习方法》第 七 章
《机器学习实战》第 六 章
《从零推导支持向量机》
博客:https://www.cnblogs.com/bentuwuying/p/6444516.html
博客:http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html
博客:https://www.cnblogs.com/zhizhan/p/4430253.html
博客:https://www.cnblogs.com/xxrxxr/p/7538430.html
不要让懒惰占据你的大脑,不要让妥协拖垮了你的人生。青春就是一张票,能不能赶上时代的快车,你的步伐就掌握在你的脚下。
机器学习之支持向量机—SVM原理代码实现的更多相关文章
- 机器学习算法 - 支持向量机SVM
在上两节中,我们讲解了机器学习的决策树和k-近邻算法,本节我们讲解另外一种分类算法:支持向量机SVM. SVM是迄今为止最好使用的分类器之一,它可以不加修改即可直接使用,从而得到低错误率的结果. [案 ...
- 【机器学习】支持向量机SVM
关于支持向量机SVM,这里也只是简单地作个要点梳理,尤其是要注意的是SVM的SMO优化算法.核函数的选择以及参数调整.在此不作过多阐述,单从应用层面来讲,重点在于如何使用libsvm,但对其原理算法要 ...
- python机器学习之支持向量机SVM
支持向量机SVM(Support Vector Machine) 关注公众号"轻松学编程"了解更多. [关键词]支持向量,最大几何间隔,拉格朗日乘子法 一.支持向量机的原理 Sup ...
- 机器学习(四):通俗理解支持向量机SVM及代码实践
上一篇文章我们介绍了使用逻辑回归来处理分类问题,本文我们讲一个更强大的分类模型.本文依旧侧重代码实践,你会发现我们解决问题的手段越来越丰富,问题处理起来越来越简单. 支持向量机(Support Vec ...
- 支持向量机SVM原理_python sklearn建模乳腺癌细胞分类器(推荐AAA)
项目合作联系QQ:231469242 sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?cours ...
- 机器学习(十一) 支持向量机 SVM(上)
一.什么是支撑向量机SVM (Support Vector Machine) SVM(Support Vector Machine)指的是支持向量机,是常见的一种判别方法.在机器学习领域,是一个有监督 ...
- 机器学习:支持向量机(SVM)
SVM,称为支持向量机,曾经一度是应用最广泛的模型,它有很好的数学基础和理论基础,但是它的数学基础却比以前讲过的那些学习模型复杂很多,我一直认为它是最难推导,比神经网络的BP算法还要难懂,要想完全懂这 ...
- 机器学习-5 支持向量机SVM
一.概念和背景 SVM:Support Vector Machine 支持向量机. 最早是由Vladimir N. Vapnik和Alexey Ya. Chervonenkis在1963年提出的. 目 ...
- 支持向量机(SVM)原理详解
SVM简介 支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机:SVM还包括核技巧, ...
随机推荐
- golang 1.8 优雅关闭
// main.go package main import ( "fmt" "log" "net/http" "os" ...
- BZOJ_3831_[Poi2014]Little Bird_单调队列优化DP
BZOJ_3831_[Poi2014]Little Bird_单调队列优化DP Description 有一排n棵树,第i棵树的高度是Di. MHY要从第一棵树到第n棵树去找他的妹子玩. 如果MHY在 ...
- 【英国毕业原版】-《博尔顿大学毕业证书》Bolton一模一样原件
☞博尔顿大学毕业证书[微/Q:2544033233◆WeChat:CC6669834]UC毕业证书/联系人Alice[查看点击百度快照查看][留信网学历认证&博士&硕士&海归& ...
- 记一次产品需求:图片等比缩放和CSS自适应布局16:9
前言 前阵子,产品跑过来问我现有的模板中没有图片模板,需要添加一个图片模板:然而,他要求图片在展示区最好能够实现随着窗口的变化而自动按图片比例等比缩放,并且居中展示图片.我当时想着,抛开技术实现层面, ...
- 【官网翻译】性能篇(四)为电池寿命做优化——使用Battery Historian分析电源使用情况
前言 本文翻译自“为电池寿命做优化”系列文档中的其中一篇,用于介绍如何使用Battery Historian分析电源使用情况. 中国版官网原文地址为:https://developer.android ...
- 如何在ASP.NET Core中自定义Azure Storage File Provider
文章标题:如何在ASP.NET Core中自定义Azure Storage File Provider 作者:Lamond Lu 地址:https://www.cnblogs.com/lwqlun/p ...
- [PHP] debug_backtrace()可以获取到代码的调用路径追踪
查看代码的时候,看到有使用这个函数,测试一下 1.debug_backtrace()可以获取到代码的调用追踪,以数组形式返回 2.debug_print_backtrace() — 打印一条回溯,直接 ...
- Java设置PDF有序、无序列表
文档中的设置有序或无序列表是一种反应内容上下级关系或者内容相同属性的方式,与单纯的文字叙述相比,它能有效增强文档内容的条理性,突出重点.因此,本文将分享通过Java编程在PDF文档中设置有序或无序列表 ...
- 配置rsync+inotify实时同步
与上一篇同步做 配置rsync+inotify实时同步 1:调整inotify内核参数 在linux内核中,默认的inotify机制提供三个调控参数:max_queue_events.max_user ...
- 一个能快速写出实体类的Api文档管理工具
今天各种MVC框架满天飞,大大降低了编码的难度,写实体类就没有办法回避的一件事了,花大把的时间去做一些重复而且繁琐的工作,实在不是一个优秀程序员的作风,所以多次查找和尝试后,找到一个工具类网站——Ap ...