ElasticSearch本地调测环境构建
ElasicSearch版本:6.0.0:https://github.com/elastic/elasticsearch.git
1:安装JVM(JVM1.8以上)
2:安装gradle(3.3以上)
下载:gradle下载地址:http://services.gradle.org/distributions/,下载4.3版本。(本人第一次安装的是4.4.5,结果到后面执行gradle idea指令的时候,下载不到gradle-logger-4.4.5的包,阿里的maven或者jcenter都没有,最新的归档的只有4.3)
环境变量:配置GRADLE_HOME到你的gradle根目录当中,然后把%GRADLE_HOME%/bin加到PATH的环境变量。
检查:进入cmd控制台,执行gradle -V,会输出Groovy,JVM等的版本,说明安装OK
3:下载elasticsearch源码:
下载ElasticSearch代码:https://github.com/elastic/elasticsearch,(本人下载的是6.0.0版本):
4:配置软件包仓库源地址(如果忍受得了下载的网速,此步骤可选。此步骤因为需要从包仓库jcenter或者apache的maven库下载依赖额所有jar,会很漫长,耗费了40分钟,使用国内的仓库源,只需要5分钟即可)
- 在C:\Users\用户\.gradle下建立init.gradle文件
- 编辑文件内容如下:
allprojects{
repositories {
def REPOSITORY_URL = 'http://maven.aliyun.com/nexus/content/groups/public/'
all { ArtifactRepository repo ->
if(repo instanceof MavenArtifactRepository){
def url = repo.url.toString()
if (url.startsWith('https://repo.maven.org/maven2') || url.startsWith('https://jcenter.bintray.com/')) {
project.logger.lifecycle "Repository ${repo.url} replaced by $REPOSITORY_URL."
remove repo
}
}
}
maven {
url REPOSITORY_URL
}
}
}
- 编辑${elasticsearch源码根目录}\distribution\build.gradle文件,红色部分替换为如下。
buildscript {
repositories {
maven {
url "http://maven.aliyun.com/nexus/content/groups/public/"
}
}
dependencies {
classpath 'com.netflix.nebula:gradle-ospackage-plugin:3.4.0'
}
}
5:执行gradle idea
cmd控制台进入elasticsearch源码根目录,执行gradle idea。(idea导入源码前,必须进行此步骤,否则会报错)

6:ElasticSearch工程导入IDEA
IDEA导入工程,导入的时候需要设置gradle_home,配置为gradle的安装根目录。勾选Offline work(否则会连到官网私服下载,会超级慢)和Use local gradle distribution。
7:编译
在IDEA中view->tool windows->gradle点击,在gradle project视图栏目里找到core工程,点击build编译,也可以选择jar,编译后会在core\build\distributions\下生成elasticsearch的jar包。

8:启动
Elasticsearch的启动类:org.elasticsearch.bootstrap.Elasticsearch,右键运行。
错误一:
Error:Unable to make the module: core_main, related gradle configuration was not
执行
解决方式:刷新gradle工程
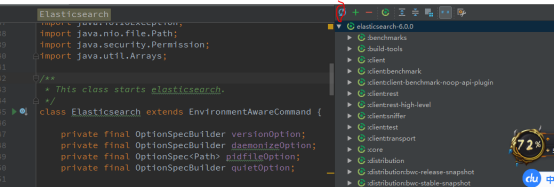
问题二:启动报错
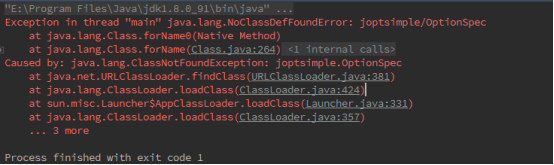
解决方式:
搞了半天是IDEA和gradle的兼容性bug问题:
https://stackoverflow.com/questions/42587487/noclassdeffounderror-after-intellij-idea-upgrade
编译无问题,运行时找不到依赖的类。
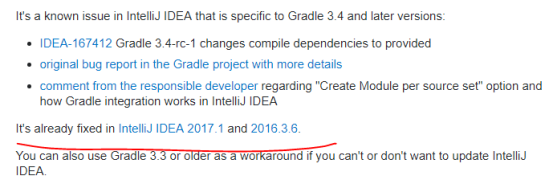
根据所说,此bug在IDEA的新版本解决了,but我的IDEA版本是:2016.3.4
官网下载IDEA 2017.2.5版本:
https://www.jetbrains.com/idea/download/previous.html?fromIDE=
新版本安装后,此问题解决。
问题三:启动包es.path.conf未设置。
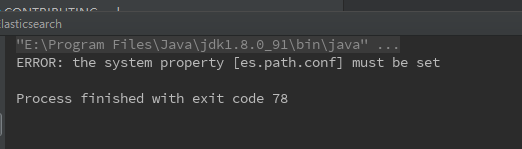
查看源码的启动脚本:
distribution\src\main\resources\bin\下elasticsearch.sh中:
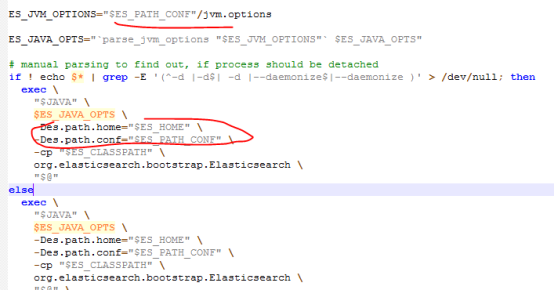
所需的配置文件在源码的位置:
G:\github-java\elasticsearch-6.0.0\distribution\src\main\resources\config。故而设置两个JVM环境变量即可:
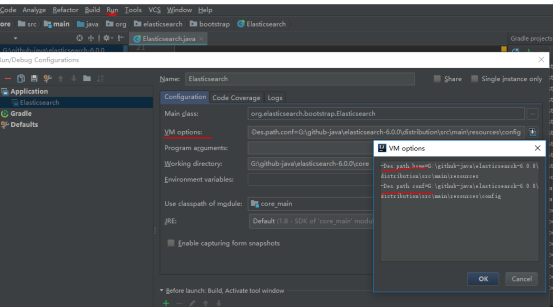
再次启动此问题解决。
问题四:access denied ("javax.management.MBeanTrustPermission" "register")
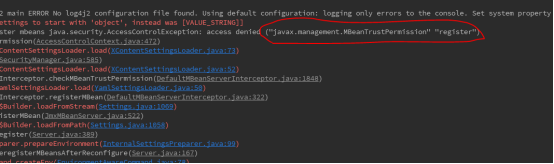
解决方式:设置JVM环境变量如下:-Dlog4j2.disable.jmx=true
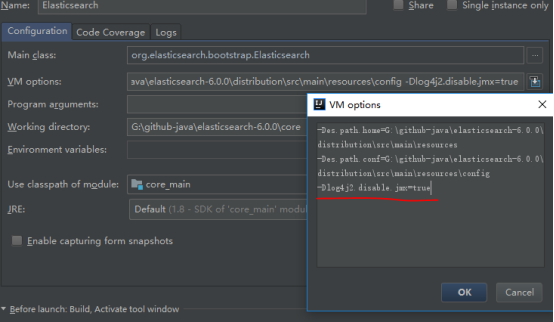
问题五:加载不到plugin。
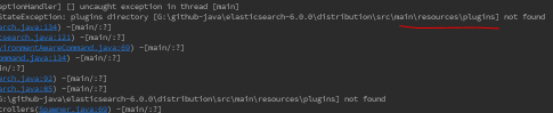
解决方式:参照发行版,发行版目录下有空的plugins目录,在G:\github-java\elasticsearch-6.0.0\distribution\src\main\resources下也建立空的plugins目录。
问题六:Unsupported transport.type
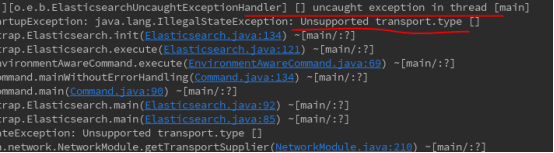
解决方式:将发行版mudules目录下内容拷贝过来。
问题七:空指针异常:

跟踪源码,发现如下原因:ES中对于modules中对于jar包名称包含elasticsearch-rest-client.jar包的,在编译的时候,因为本地编译默认是snapshot的,所以会追加snapshot,这样的化版本号变为了6.0.0-snapshot,而modules中是从发行版拷贝过来的,结合代码上追加的codebase,变为了codebase.elasticsearch-rest-client-6.0.0.jar,这样index版本号就出错了。

解决方式:修改org.elasticsearch.Build 74行,
// isSnapshot = true; by angie_hawk7
isSnapshot = false;
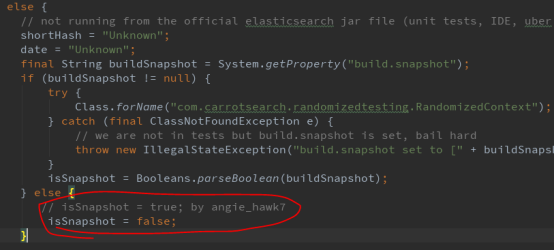
(也可以设置jvm环境变量:build.snapshot)
再次启动OK:
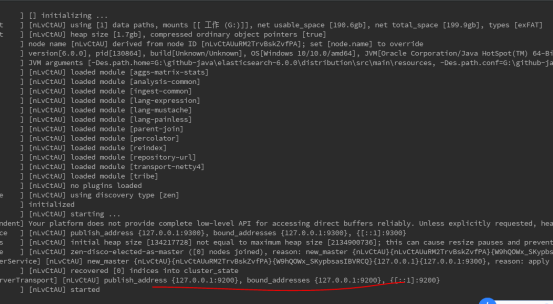
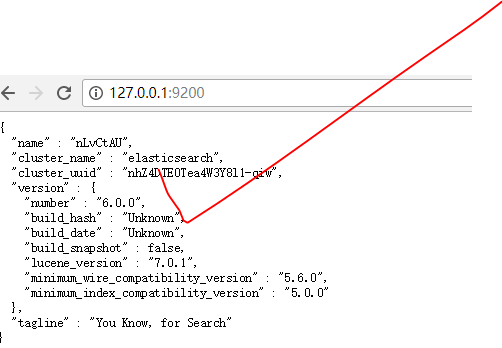
10:测试
ElasticSearch本地调测环境构建的更多相关文章
- Elasticsearch本地环境安装和常用操作
本篇文章首发于我的头条号Elasticsearch本地环境安装和常用操作,欢迎关注我的头条号和微信公众号"大数据技术和人工智能"(微信搜索bigdata_ai_tech)获取更多干 ...
- 【经验分享】如何搭建本地MQTT服务器(Windows ),并进行上下行调测
网上查了很多资料,实际动手的时候踩了很多坑,现在把我的经验分享给大家: 一.安装和启动 使用EMQTT,下载完直接到bin目录下执行emqttd start就可以了,简单方便 下载地址:https:/ ...
- Elasticsearch搜索调优权威指南 (1/3)
本文首发于 vivo互联网技术 微信公众号 https://mp.weixin.qq.com/s/qwkZKLb_ghmlwrqMkqlb7Q英文原文:https://qbox.io/blog/ela ...
- 04_Windows平台Spark开发环境构建
Spark的开发环境,可以基于IDEA+Scala插件,最终将打包得到的jar文件放入Linux服务器上的Spark上运行 如果是Python的小伙伴,可以在Windows上部署spark+hadoo ...
- 物联网打工人必备:LiteOS Studio图形化调测能力
摘要:本文会给大家介绍下LiteOS Studio的调测的几个知识点,包括: 调测配置,监视变量,反汇编代码同步展示,数值进制切换,跨平台编译调测,Qemu模拟器调测,多核调测,远程设备调测等. 掌握 ...
- 关于Android真机调测Profiler
U3D中的Profile也是可以直接在链接安卓设备运行游戏下查看的,导出真机链接U3D的Profile看数据,这样能更好的测试具体原因. 大概看了下官方的做法,看了几张帖子顺带把做法记录下来. ...
- Hyperledger Fabric 1.0 从零开始(二)——环境构建(公网)
1:环境构建 在本文中用到的宿主机环境是Centos ,版本为Centos.x86_647.2,通过Docker 容器来运行Fabric的节点,版本为v1.0.因此,启动Fabric网络中的节点需要先 ...
- docker-swarm建立本地集成开发环境
在k8s出现之后,docker-swarm使用的人越来越少,但在本地集成开发环境的搭建上,使用它还是比较轻量级的,它比docker-compose最大的好处就是容器之间的共享和服务的治理,你不需要li ...
- 使用python requests模块搭建http load压测环境
网上开源的压力测试工具超级的多,但是总有一些功能不是很符合自己预期的,于是自己动手搭建了一个简单的http load的压测环境 1.首先从最简单的http环境着手,当你在浏览器上输入了http://w ...
随机推荐
- 5、使用Libgdx设计一个简单的游戏------雨滴
(原文:http://www.libgdx.cn/topic/49/5-%E4%BD%BF%E7%94%A8libgdx%E8%AE%BE%E8%AE%A1%E4%B8%80%E4%B8%AA%E7% ...
- (NO.00001)iOS游戏SpeedBoy Lite成形记(六)
为了能让玩家可以在比赛结束时清楚看到每位选手的成绩,我们需要在GameScene场景的track对象中添加一些新的元素. 在SpriteBuilder中打开GameScene.ccb,创建1个标签对象 ...
- OPEN A PO ORDER OR SO ORDER
OPEN PO ORDER fnd_function.Execute(Function_Name => 'PO_POXPOEPO', Open_Flag => 'Y', Session_F ...
- C语言之鞍点的查找
鞍点(Saddle point)在微分方程中,沿着某一方向是稳定的,另一条方向是不稳定的奇点,叫做鞍点.在泛函中,既不是极大值点也不是极小值点的临界点,叫做鞍点.在矩阵中,一个数在所在行中是最大值,在 ...
- LeetCode之“动态规划”:Unique Binary Search Trees && Unique Binary Search Trees II
1. Unique Binary Search Trees 题目链接 题目要求: Given n, how many structurally unique BST's (binary search ...
- 史上最全Android Studio快捷键 -2016-02-28
- 用xml来编写动画
我们可以使用代码来编写所有的动画功能,这也是最常用的一种做法.不过,过去的补间动画除了使用代码编写之外也是可以使用XML编写的,因此属性动画也提供了这一功能,即通过XML来完成和代码一样的属性动画功能 ...
- Linux下进程通信方式(简要概述)
http://blog.sina.com.cn/s/blog_65c209580100u0ee.html (1)管道(Pipe):管道可用于具有亲缘关系进程间的通信,允许一个进程和另一个与它有共同祖先 ...
- SharePoint 2007 列表页定制--4个默认页定制
以"简单的领导简介"为例,欢迎大家指正 背景:项目中需要有领导简介的模块,就开始制作领导简介,本来很简单,有一个列表就可以,然后在前台展示出来,但是客户看到我们的效果,尤其输入领导 ...
- 关于C语言程序条件编译的简单使用方法
#include <stdio.h> #include <stdlib.h> #define Mode //如果定义了Mode,那么就执行这个函数 #ifdef Mode vo ...