[整理]Centos6.5 + hadoop2.6.4环境搭建
搭建Hadoop集群环境(3台机器)
1 准备环境
1.1 安装系统,并配置网络使3台机器互联互通,且SSH可直连(无需密码、保存私钥)
1.1.1 安装系统
安装Centos 6.5系统
安装过程略
1.1.2 配置网络
设置三台机器的iP分别为
|
IP |
主机名称 |
|
10.132.41.116 |
Hadoop.slave2 |
|
10.132.41.117 |
Hadoop.slave1 |
|
10.132.41.118 |
Hadoop.master |
修改计算机名称
Vi /etc/sysconfig/network
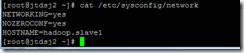
以上修改需要重启生效。可同时立即生效,增加执行以下命令:
Sudo hostname hadoop.slave1
1.1.3 SSH配置
a).首先在hadoop.master机器上用root(hadoop用户)登录,先生成ssh密钥文件,执行
ssh-keygen -t rsa
过程中,回车3次,提示以下内容表示成功
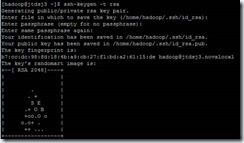
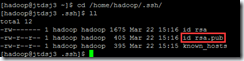
查看公钥文件是否生成:/home/hadoop/.ssh
b).执行命令将密钥文件共享给其他机器
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@10.132.41.117
第一次执行需要输入hadoop的密码。
输出一下内容表示执行成功。
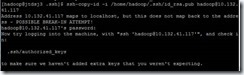
c).执行命令测试是否建立互信成功
使用ssh直接连接服务器,确认是否免密码登录。
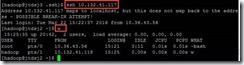
ssh 10.132.41.117
登录后输入任意命令确认是否登录成功。
w
1.2 安装JDK,并配置环境变量
1.2.1 安装JDK
先执行rpm查询命令确认是否已安装了JDK其他版本
rpm –qa | grep jdk
返回不为空,且版本不对可执行以下命令,将当前版本卸载掉
rpm –c 软件包名称
下载JDK文件并上传到服务器(rpm),执行
rpm –ivh 软件包名称
1.2.2 配置环境变量
使用vi进入/etc/profile文件,在最后追加以下内容:
# set java environment
export JAVA_HOME=/usr/java/jdk1..0_31 # export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
之后执行以下命令,重启配置文件。
source /etc/profile
1.2.3 测试环境
执行命令确认安装是否正常。
[root@hadoop hadoop]# java -version
java version "1.7.0_80"
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) -Bit Server VM (build 24.80-b11, mixed mode)
2 安装Hadoop
需要将所有的机器(master和slave)都需要安装hadoop,操作都一样,下面以master为示例。
2.1 下载
登录hadoop官网,下载对应版本。本示例使用了最新版2.6.4版本。
http://hadoop.apache.org/releases.html
下载后的文件hadoop-2.6.4.tar.gz,使用SFTP工具上传到hadoop.master机器上。
2.2 安装
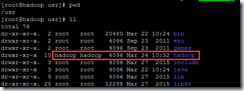
用root用户登录hadoop.master机器,将上传上来的hadoop-2.6.4.tar.gz文件拷贝至/usr下。
执行“tar zxf hadoop-2.6.4.tar.gz hadoop”,将hadoop解压到/usr/hadoop目录下。
执行以下命令,将hadoop文件夹的归属用户和组修改到hadoop用户下。
chown –R hadoop:dadoop hadoop
配置后如下:
2.3 配置环境变量
使用vi进入/etc/profile文件,在最后追加以下内容:
# set hadoop environment
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$ HADOOP _HOME/bin
之后执行以下命令,重启配置文件。
source /etc/profile
执行以下命令,确认配置生效。
[root@hadoop hadoop]# hadoop version
Hadoop 2.6.
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 5082c73637530b0b7e115f9625ed7fac69f937e6
Compiled by jenkins on --12T09:45Z
Compiled with protoc 2.5.
From source with checksum 8dee2286ecdbbbc930a6c87b65cbc010
This command was run using /usr/hadoop/share/hadoop/common/hadoop-common-2.6..jar
3 配置Hadoop
3.1 配置master
Hadoop涉及3个配置文件etc/hadoop/core-site.xml,etc/hadoop/hdfs-site.xml,etc/hadoop/mared-site.xml文件。
注:
以下配置中的hadoop.master均可以使用master的ip来替代。
所有的配置文件在2.x已经调整到$HADOOP_HOME/etc/hadoop下。
默认不存在“mapred-site.xml”文件,需要复制mapred-site.xml.template。
3.1.1 配置core-site.xml
<configuration> <property>
<name>fs.default.name</name>
<value>hdfs://hadoop.master:9000</value>
<final>true</final>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
</property> <property>
<name>ds.default.name</name>
<value>hdfs://hadoop.master:54310</value>
<final>true</final>
</property>
</configuration>
3.1.2 配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/dfs/name</value>
<final>true</final>
</property> <property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/dfs/data</value>
<final>true</final>
</property> <property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
3.1.3 配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop.master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop.master:19888</value>
</property>
</configuration>
3.1.4 配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property> <property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop.master</value>
</property> <property>
<name>yarn.resourcemanager.address</name>
<value>hadoop.master:8032</value>
</property> <property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop.master:8030</value>
</property> <property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop.master:8031</value>
</property> <property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop.master:8033</value>
</property> <property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop.master:8088</value>
</property>
</configuration>
3.1.5 配置masters和slaves文件
分别将master的信息和所有slave机器的信息写入到masters和slaves文件中。

注:slaves文件中的数量必须大于hdfs-site.xml文件中的“dfs.replication”配置,否则namenode无法启动。
另外,masters是根据网上教程手动生成的,然后配置貌似没起到作用。
3.2 配置slave
配置slave有2种方式:1.将hadoop的安装包上传到slave机器重新配置;2.将master上的配置复制到slave机器上。本示例采用了第2种方法,即全盘复制master上的配置。
3.2.1 安装JDK和配置环境变量
操作同master,此处略。
3.2.2 配置hosts
操作同master,此处略。
3.2.3 复制master上的hadoop
首先用hadoop用户(ssh已互信)执行以下命令,将hadoop复制到slave机器上。
scp /usr/hadoop hadoop@hadoop.slave1:/home/hadoop
用root用户登录hadoop.slave1,并执行以下命令,将hadoop移至/usr目录下。
mv /home/hadoop/hadoop /usr/
修改hadoop的拥有着。
chown –R hadoop:hadoop hadoop
注:需要在环境配置时添加好hadoop用户及用户组。
3.3 关闭防火墙
[hadoop@hadoop ~]$ su root
Password:
[root@hadoop hadoop]# service iptables stop
[root@hadoop hadoop]# chkconfig iptables off
4 启动和验证
4.1 初始化Namenode
在Master上用hadoop用户,执行以下命令初始化Namenode。
hadoop namenode -format
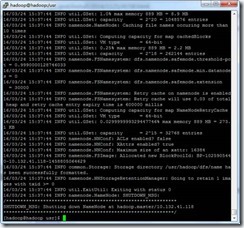
注:第2次以后初始化,过程中会提示是否删除已初始化内容,输入Y即可。
4.2 启动集群
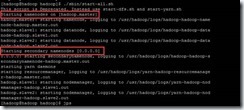
4.3 验证
4.3.1 Master验证Namenode启动
在Master上用hadoop用户执行jps,显示以下内容,即启动成功。
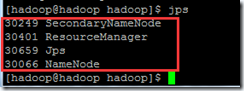
如果缺少进程,可以到“$HADOOP_HOME/logs”下查看日志,确认启动失败的原因。
4.3.2 Slave验证Datanode启动
在Slave上分别用hadoop用户执行jps,显示以下内容,即启动成功。
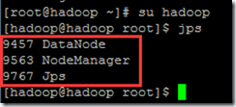
如果缺少进程,可以到“$HADOOP_HOME/logs”下查看日志,确认启动失败的原因。
注:2.X以后没有Jobtracker和Tasktracker进程了。
5 问题FAQ
5.1 启动时报“WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable”
【问题现象】:启动时出现警告“WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable”
【问题分析】:通过错误提示得知,部分文件由32位平台编译,本机是64位centos,因此报错。
【解决措施】:通过网友提供的一个编译文件,下载并替换$HADOOP_HOME/lib/native目录下文件,即可解决此警告。
博客地址:http://www.secdoctor.com/html/yyjs/31101.html
文件的下载地址:http://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.6.0.tar
5.2 Master报“”,Namenode启动失败
【问题现象】:通过执行jps,发现master上没有namenode进程,查看log日志发现,有以下错误
FATAL org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
java.net.BindException: Problem binding to [hadoop.master:9000] java.net.BindException: Cannot assign requested address; For more details see: http://wiki.apache.org/hadoop/BindException
【问题分析】:由于申请的云虚拟机,外部连接的IP为10开头的大网IP,通过ifconfig查看本机IP发现并非多网卡,而是做了IP映射,即配置的IP在本地无法访问到,导致JVM出现BindException。
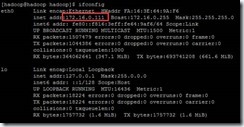
【解决措施】:通过使用虚拟机本机IP(172开头)在集群中的所有机器中相互ping,如果都能ping通,则可以直接使用本机IP做配置(本例即是)。修改/etc/hosts文件中的hostname映射IP并复制到集群中所有的机器,ssh互信重做,在master上重新格式化namenode后启动即可。
5.3 Slave报“All specified directories are failed to load.”,Datanode启动失败
【问题现象】:通过执行jps,发现slave上没有datanode进程,查看log日志发现,有以下错误信息:
WARN org.apache.hadoop.hdfs.server.common.Storage: java.io.IOException: Incompatible clusterIDs in /usr/hadoop/dfs/data: namenode clusterID = CID-1a1fabff-166c-4c0a-9bd3-b726f217cc87; datanode clusterID = CID-65c03263-c30a-4592-8019-f6b356061418
2016-03-28 17:07:09,416 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to hadoop.master/172.16.0.111:9000. Exiting.
java.io.IOException: All specified directories are failed to load.
【问题分析】:由于变动了IP和重新初始化namenode,master的clusterID已经变化,slave连接master失败。需要更新clusterID为最新的值即可。
【解决措施】:修改data/current目录下的VERSION文件中clusterID为namenode的ID,并重启。
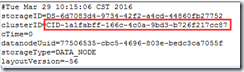
注:data目录的配置在hdfs-site.xml文件中的“dfs.datanode.data.dir”配置项。
6 附件
6.1 本示例中的配置文件
[整理]Centos6.5 + hadoop2.6.4环境搭建的更多相关文章
- hadoop2集群环境搭建
在查询了很多资料以后,发现国内外没有一篇关于hadoop2集群环境搭建的详细步骤的文章. 所以,我想把我知道的分享给大家,方便大家交流. 以下是本文的大纲: 1. 在windows7 下面安装虚拟机2 ...
- CENTOS6.4上KVM虚拟机环境搭建
CENTOS6.4上KVM虚拟机环境搭建 关键词: KVM,虚拟机,windows7, VNC, 桥接网络,br0, SCSI, IDE 环境: host: CENTOS6.4 guest: ...
- 深度学习环境搭建常用网址、conda/pip命令行整理(pytorch、paddlepaddle等环境搭建)
前言:最近研究深度学习,安装了好多环境,记录一下,方便后续查阅. 1. Anaconda软件安装 1.1 Anaconda Anaconda是一个用于科学计算的Python发行版,支持Linux.Ma ...
- Ubuntu16.04+hadoop2.7.3环境搭建
转载请注明源出处:http://www.cnblogs.com/lighten/p/6106891.html 最近开始学习大数据相关的知识,最著名的就是开源的hadoop平台了.这里记录一下目前最新版 ...
- [Revit]Autodesk Revit 二次开发整理(资料、准备工作和环境搭建)
1 前言 Revit被Autodesk收购之后,整理和开放了一大部分API,供开发者实现自己的功能和程序,总体来说API的功能比较完善,毕竟市面上已经出现了各式各样的插件. 本人也是初学者,在Revi ...
- Centos6.5和Centos7 php环境搭建如何实现呢
首先我们先查看下centos的版本信息 代码如下: #适用于所有的linux lsb_release -a#或者cat /etc/redhat-release#又或者rpm -q centos-rel ...
- VMware 安装centOS6.4虚拟机以及基础环境搭建
- Centos-6.5 + python3 + mysql5.6 环境搭建
注意:Centos6.5 是刚装好的系统 yum install lrzsz (ftp上传和下载) yum install -y gcc yum install -y gcc gcc-c++ ...
- hadoop2.2分布式环境搭建
hadoop2.2的分布式环境需要配置的参数更多.但是需要安装的系统软件和单节点环境是一样的. 运行hadoop在非安全环境 hadoop的配置文件有两类: 1:只读的默认配置文件: core-def ...
随机推荐
- easyUI下拉列表三级联动
首先是先想好数据库的搭建,通过地区id,地区名称,上级地区id就可以实现,所有省市区的数据 例如: DAO层 service层 Servlet 页面 <!DOCTYPE html> < ...
- Python实战:下载鬼灵报告有声小说
在家无聊,想看看小说,不过看的眼睛痛,就想着下个有声小说来听听.但风上找到的都是要一集一集下,还得重命名,122集啊,点到什么时候. 写个批处理下载的脚本.记录下过程. 一.老套路了,找到下载URL. ...
- metasploit模块字典爆破tomcat
祭出神器MSF 再用auxiliary/scanner/http/tomcat_mgr_login 这个辅助模块爆破下弱口令 这里就用模块自带的字典吧 然后简单配置下.RUN 需要自己定义字典的话 ...
- Docker对普通开发者的用处(转)
有些开发者可能还是不明白 Docker 对自己到底有多大的用处,因此翻译 Docker 个人用例 这篇文章中来介绍 Docker 在普通开发者开发过程中的用例. Docker 如今赢得了许多关注,很多 ...
- Elasticsearch 运维实战之1 -- 集群规划
规划一个可用于生产环境的elasticsearch集群. 集群节点划分 整个集群的节点分为以下三种主要类型 Master nodes -- 负责维护集群状态,不保存index数据, 硬件要求: 一般性 ...
- 使用C#模拟键盘输入、鼠标移动和点击、设置光标位置及控制应用程序的显示
1.模拟键盘输入(SendKeys) 功能:将一个或多个按键消息发送到活动窗口,就如同在键盘上进行输入一样. 语法:SendKeys.Send(string keys);SendKeys.SendWa ...
- python计算apache总内存
#!/usr/bin/env python import os from subprocess import Popen, PIPE def getPid(): p=Popen(['pidof','h ...
- C# String 前面不足位数补零的方法
int i=10;方法1:Console.WriteLine(i.ToString("D5"));方法2:Console.WriteLine(i.ToString().PadLef ...
- 模拟jquery的$()选择器的实现
<html> <head> </head> <body> <div id="div1">div1</div> ...
- 20145220&20145209&20145309信息安全系统设计基础实验报告(3)
20145220&20145209&20145309信息安全系统设计基础实验报告(3) 实验报告链接: http://www.cnblogs.com/zym0728/p/6132243 ...