关于怎么获取kafka指定位置offset消息(转)
1.在kafka中如果不设置消费的信息的话,一个消息只能被一个group.id消费一次,而新加如的group.id则会被“消费管理”记录,并指定从当前记录的消息位置开始向后消费。如果有段时间消费者关闭了,并有发送者发送消息那么下次这个消费者启动时也会接收到,但是我们如果想要从这个topic的第一条消息消费呢?
public class SimpleConsumerPerSonIndex2 {
public static void main(String[] args) throws Exception {
//Kafka consumer configuration settings
String topicName = "mypartition001";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "partitiontest112");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
//要发送自定义对象,需要指定对象的反序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "com.ys.test.SpringBoot.zktest.encode.DecodeingKafka");
KafkaConsumer<String, Object> consumer = new KafkaConsumer<String, Object>(props);
Map<TopicPartition, OffsetAndMetadata> hashMaps = new HashMap<TopicPartition, OffsetAndMetadata>();
hashMaps.put(new TopicPartition(topicName, 0), new OffsetAndMetadata(0));
consumer.commitSync(hashMaps);
consumer.subscribe(Arrays.asList(topicName));
while (true) {
ConsumerRecords<String, Object> records = consumer.poll(100);
for (ConsumerRecord<String, Object> record : records){
System.out.println(record.toString());
}
}
}
}
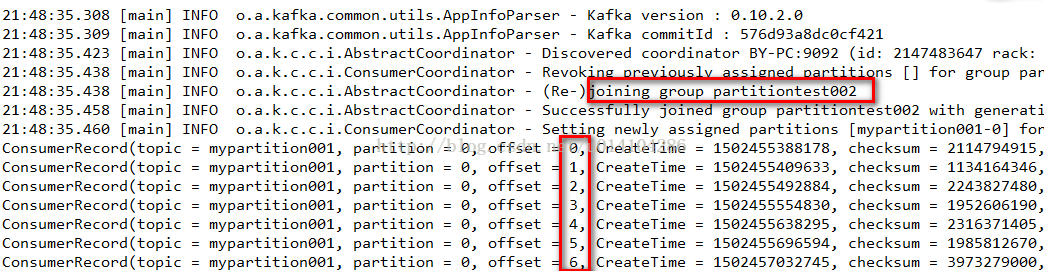
首先我们在consumer.subscribe(Arrays.asList(topicName));订阅一个topic之前要设置从这个topic的offset为0的地方获取。
注意:这样的方法要保证这个group.id是新加入,如果是以前存在的,那么会抛异常。
2.如果以前就存在的groupid想要获取指定的topic的offset为0开始之后的消息:
public class SimpleConsumerPerSonIndex2 {
public static void main(String[] args) throws Exception {
//Kafka consumer configuration settings
String topicName = "mypartition001";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "partitiontest002");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
//要发送自定义对象,需要指定对象的反序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "com.ys.test.SpringBoot.zktest.encode.DecodeingKafka");
KafkaConsumer<String, Object> consumer = new KafkaConsumer<String, Object>(props);
// consumer.subscribe(Arrays.asList(topicName));
consumer.assign(Arrays.asList(new TopicPartition(topicName, 0)));
consumer.seekToBeginning(Arrays.asList(new TopicPartition(topicName, 0)));//不改变当前offset
// consumer.seek(new TopicPartition(topicName, 0), 10);//不改变当前offset
while (true) {
ConsumerRecords<String, Object> records = consumer.poll(100);
for (ConsumerRecord<String, Object> record : records){
System.out.println(record.toString());
}
}
}
}
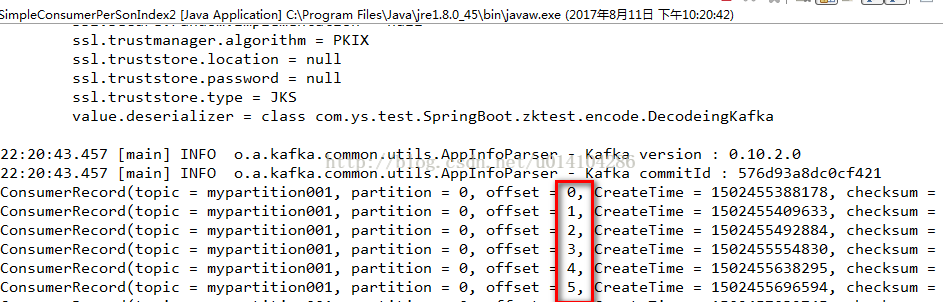
使用 consumer.assign(Arrays.asList(new TopicPartition(topicName, 0)));来分配topic和partition,
而consumer.seekToBeginning(Arrays.asList(new TopicPartition(topicName, 0)));指定从这个topic和partition的开始位置获取。
3.存在的groupid获取指定的topic任意的offset
上面的代码放开 consumer.seek(new TopicPartition(topicName, 0), 10);//不改变当前offset
并注释 consumer.seekToBeginning(Arrays.asList(new TopicPartition(topicName, 0)));//不改变当前offset;
其中consumer.seek(new TopicPartition(topicName, 0), 10)中的10是表示从这个topic的partition中的offset为10的开始获取消息。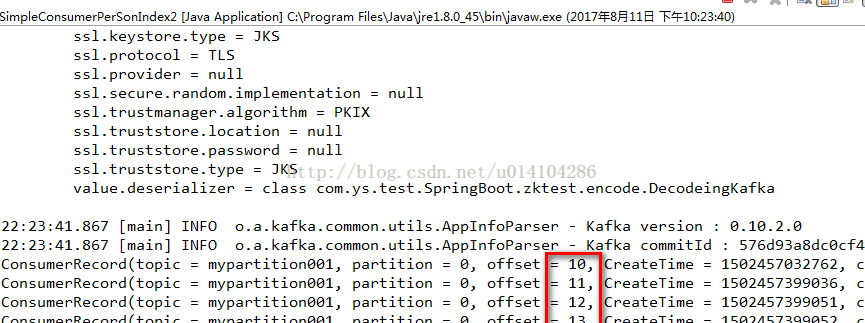
需要注意的是 consumer.assign()是不会被消费者的组管理功能管理的,他相对于是一个临时的,不会改变当前group.id的offset,比如:
在使用consumer.subscribe(Arrays.asList(topicName));时offset为20,如果通过2和3,已经获取了最新的消息offset是最新的,
在下次通过 consumer.subscribe(Arrays.asList(topicName));来获取消息时offset还是20.还是会获取20以后的消息。
其实在2、3的结果截图中我们也可以发现没有1中结果图的joining group的日志输出,表示没有加入到group中。
————————————————
版权声明:本文为CSDN博主「也是右移」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u014104286/article/details/77103541/
关于怎么获取kafka指定位置offset消息(转)的更多相关文章
- jQuery 获取元素当前位置offset()与position()
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8& ...
- 获取kafka的lag, offset, logsize的shell和python脚本
python脚本 #!/usr/bin/env python import os import re import sys group_id=sys.argv[1] pn=sys.argv[2] ka ...
- 工具篇-Spark-Streaming获取kafka数据的两种方式(转载)
转载自:https://blog.csdn.net/weixin_41615494/article/details/7952173 一.基于Receiver的方式 原理 Receiver从Kafka中 ...
- Spark-Streaming获取kafka数据的两种方式:Receiver与Direct的方式
简单理解为:Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据 Receiver 使用Kafka的高层次Consumer API来 ...
- SparkStreaming获取kafka数据的两种方式:Receiver与Direct
简介: Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以简单理解成: Receiver方式是通过zookeeper来连接kafka队列, Dire ...
- spark-streaming获取kafka数据的两种方式
简单理解为:Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据 一.Receiver方式: 使用kafka的高层次Consumer ...
- jQuery滚动条回到顶部或指定位置
jQuery滚动条回到顶部或指定位置 在很多网站,为了增强用户体验,我们会看到回到顶部的按钮,不用手动拖拽滚动条就能回到顶部,非常方便.下面就介绍用jquery实现的滚动到顶部的代码 $(functi ...
- 获取kafka最新offset-java
之前笔者曾经写过通过scala的方式获取kafka最新的offset 但是大多数的情况我们需要使用java的方式进行获取最新offset scala的方式可以参考: http://www.cnblog ...
- Flink 自定义source和sink,获取kafka的key,输出指定key
--------20190905更新------- 沙雕了,可以用 JSONKeyValueDeserializationSchema,接收ObjectNode的数据,如果有key,会放在Objec ...
随机推荐
- VMware HorizonView虚拟化桌面TLS问题处理
问题描述 公司虚拟化桌面环境内,进出口事业部同事在使用"中国贸易单一窗口"登录系统时,其系统本地控件无法启动WSS服务,端口显示使用61231,并反复提示安装控件. 排查过程 首先 ...
- 【Python】【demo实验25】【练习实例】
原题: 有一分数序列:2/1,3/2,5/3,8/5,13/8,21/13...求出这个数列的前20项之和. 我的源码: #!/usr/bin/python # encoding=utf-8 # -* ...
- 查找担保圈-step5-比较各组之间的成员,对组的包含性进行查询,具体见程序的注释-版本2
USE [test] GO /****** Object: StoredProcedure [dbo].[p03_get_groupno_e2] Script Date: 2019/7/8 15:01 ...
- Zookeeper 配置和原理探究
一 Zookeeper是什么? 服务集群对外提供服务的过程中,有很多的配置需要随时更新,服务间需要协调工作,那么这些信息如何推送到各个节点?并且保证信息的一致性和可靠性?我们知道分布式协调服务很难正确 ...
- nginx自定义log_format以及输出自定义http头
官方文档地址: http://nginx.org/en/docs/http/ngx_http_log_module.html 一.log_format默认格式 首先Nginx默认的log_format ...
- 从入门到自闭之Python--Django Rest_Framework
核心思想: 缩减编写api接口的代码 Django REST framework是一个建立在Django基础之上的Web 应用开发框架,可以快速的开发REST API接口应用.在REST framew ...
- django进阶版1
目录 字段中choice参数 MTV与MVC模型 AJAX(*********) Ajax普通请求 Ajax传json格式化数据 Ajax传文件 序列化组件 Ajax+sweetalert 字段中ch ...
- Boot-crm管理系统开发教程(三)
(ps:前两章我们已经把管理员登录和查看用户的功能实现了,那么今天我们将要实现:添加用户,删除用户,和修改用户功能) 由于Cusomer的POJO类型已经写好了,所以这次我们之前从CustomerCo ...
- js变量浅拷贝 深拷贝
js的变量分为简单数据类型和复杂数据类型(即引用类型). 简单数据类型在内存中占据着固定大小的空间,被保存在栈内存中,在简单数据类型中,当一个变量指向另一个变量时,只是创建了值的副本,两个变量只是占用 ...
- 【js】面向对象学习资料
1.面向对象模式: https://m.jb51.net/article/74549.htm 2.面向对象基础篇 http://www.cnblogs.com/chiangchou/p/js-oop1 ...