关于怎么获取kafka指定位置offset消息(转)
1.在kafka中如果不设置消费的信息的话,一个消息只能被一个group.id消费一次,而新加如的group.id则会被“消费管理”记录,并指定从当前记录的消息位置开始向后消费。如果有段时间消费者关闭了,并有发送者发送消息那么下次这个消费者启动时也会接收到,但是我们如果想要从这个topic的第一条消息消费呢?
public class SimpleConsumerPerSonIndex2 {
public static void main(String[] args) throws Exception {
//Kafka consumer configuration settings
String topicName = "mypartition001";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "partitiontest112");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
//要发送自定义对象,需要指定对象的反序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "com.ys.test.SpringBoot.zktest.encode.DecodeingKafka");
KafkaConsumer<String, Object> consumer = new KafkaConsumer<String, Object>(props);
Map<TopicPartition, OffsetAndMetadata> hashMaps = new HashMap<TopicPartition, OffsetAndMetadata>();
hashMaps.put(new TopicPartition(topicName, 0), new OffsetAndMetadata(0));
consumer.commitSync(hashMaps);
consumer.subscribe(Arrays.asList(topicName));
while (true) {
ConsumerRecords<String, Object> records = consumer.poll(100);
for (ConsumerRecord<String, Object> record : records){
System.out.println(record.toString());
}
}
}
}
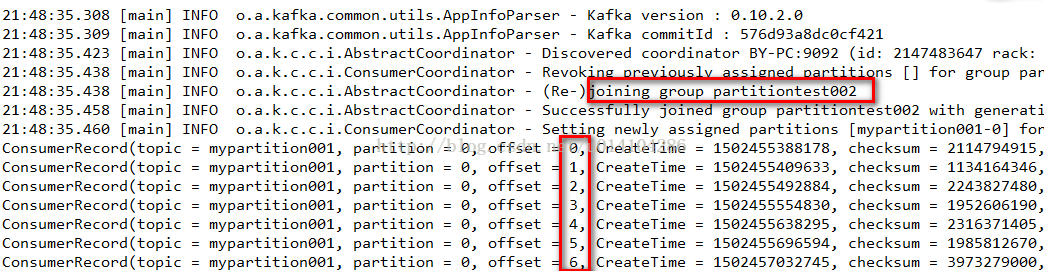
首先我们在consumer.subscribe(Arrays.asList(topicName));订阅一个topic之前要设置从这个topic的offset为0的地方获取。
注意:这样的方法要保证这个group.id是新加入,如果是以前存在的,那么会抛异常。
2.如果以前就存在的groupid想要获取指定的topic的offset为0开始之后的消息:
public class SimpleConsumerPerSonIndex2 {
public static void main(String[] args) throws Exception {
//Kafka consumer configuration settings
String topicName = "mypartition001";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "partitiontest002");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
//要发送自定义对象,需要指定对象的反序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "com.ys.test.SpringBoot.zktest.encode.DecodeingKafka");
KafkaConsumer<String, Object> consumer = new KafkaConsumer<String, Object>(props);
// consumer.subscribe(Arrays.asList(topicName));
consumer.assign(Arrays.asList(new TopicPartition(topicName, 0)));
consumer.seekToBeginning(Arrays.asList(new TopicPartition(topicName, 0)));//不改变当前offset
// consumer.seek(new TopicPartition(topicName, 0), 10);//不改变当前offset
while (true) {
ConsumerRecords<String, Object> records = consumer.poll(100);
for (ConsumerRecord<String, Object> record : records){
System.out.println(record.toString());
}
}
}
}
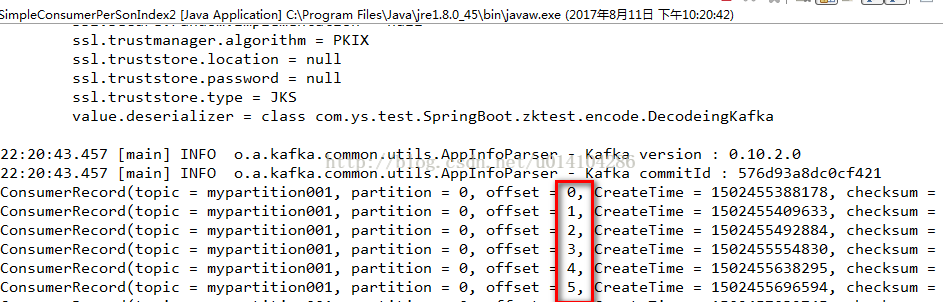
使用 consumer.assign(Arrays.asList(new TopicPartition(topicName, 0)));来分配topic和partition,
而consumer.seekToBeginning(Arrays.asList(new TopicPartition(topicName, 0)));指定从这个topic和partition的开始位置获取。
3.存在的groupid获取指定的topic任意的offset
上面的代码放开 consumer.seek(new TopicPartition(topicName, 0), 10);//不改变当前offset
并注释 consumer.seekToBeginning(Arrays.asList(new TopicPartition(topicName, 0)));//不改变当前offset;
其中consumer.seek(new TopicPartition(topicName, 0), 10)中的10是表示从这个topic的partition中的offset为10的开始获取消息。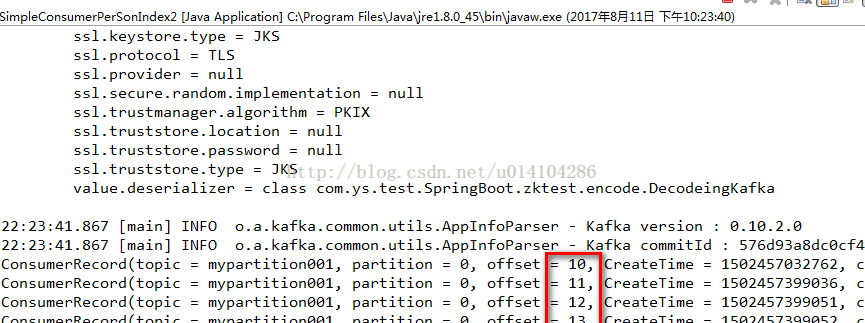
需要注意的是 consumer.assign()是不会被消费者的组管理功能管理的,他相对于是一个临时的,不会改变当前group.id的offset,比如:
在使用consumer.subscribe(Arrays.asList(topicName));时offset为20,如果通过2和3,已经获取了最新的消息offset是最新的,
在下次通过 consumer.subscribe(Arrays.asList(topicName));来获取消息时offset还是20.还是会获取20以后的消息。
其实在2、3的结果截图中我们也可以发现没有1中结果图的joining group的日志输出,表示没有加入到group中。
————————————————
版权声明:本文为CSDN博主「也是右移」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u014104286/article/details/77103541/
关于怎么获取kafka指定位置offset消息(转)的更多相关文章
- jQuery 获取元素当前位置offset()与position()
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8& ...
- 获取kafka的lag, offset, logsize的shell和python脚本
python脚本 #!/usr/bin/env python import os import re import sys group_id=sys.argv[1] pn=sys.argv[2] ka ...
- 工具篇-Spark-Streaming获取kafka数据的两种方式(转载)
转载自:https://blog.csdn.net/weixin_41615494/article/details/7952173 一.基于Receiver的方式 原理 Receiver从Kafka中 ...
- Spark-Streaming获取kafka数据的两种方式:Receiver与Direct的方式
简单理解为:Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据 Receiver 使用Kafka的高层次Consumer API来 ...
- SparkStreaming获取kafka数据的两种方式:Receiver与Direct
简介: Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以简单理解成: Receiver方式是通过zookeeper来连接kafka队列, Dire ...
- spark-streaming获取kafka数据的两种方式
简单理解为:Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据 一.Receiver方式: 使用kafka的高层次Consumer ...
- jQuery滚动条回到顶部或指定位置
jQuery滚动条回到顶部或指定位置 在很多网站,为了增强用户体验,我们会看到回到顶部的按钮,不用手动拖拽滚动条就能回到顶部,非常方便.下面就介绍用jquery实现的滚动到顶部的代码 $(functi ...
- 获取kafka最新offset-java
之前笔者曾经写过通过scala的方式获取kafka最新的offset 但是大多数的情况我们需要使用java的方式进行获取最新offset scala的方式可以参考: http://www.cnblog ...
- Flink 自定义source和sink,获取kafka的key,输出指定key
--------20190905更新------- 沙雕了,可以用 JSONKeyValueDeserializationSchema,接收ObjectNode的数据,如果有key,会放在Objec ...
随机推荐
- tcpdump移植和使用
转载于:http://blog.chinaunix.net/uid-30497107-id-5757540.html?utm_source=tuicool&utm_medium=referra ...
- 【转帖】Office的光荣历史(2)
Office的光荣历史(2) https://www.sohu.com/a/201411215_657550 2017-10-31 10:57 7.MS Office 2000 (Office 9.0 ...
- 服务器:消息18456,级别16,状态1 用户‘sa’登录失败解决方法
无法连接到服务器**: 服务器:消息18456,级别16,状态1 [Microsoft][ODBC SQL Server Driver][Sql server] 用户 'sa ...
- 小a的强迫症 题解
题面: 小a是一名强迫症患者,现在他要给一群带颜色的珠子排成一列,现在有N种颜色,其中第i种颜色的柱子有num(i)个.要求排列中第i种颜色珠子的最后一个珠子,一定要排在第i+1种颜色的最后一个珠子之 ...
- php网络请求
get请求 /** * get请求 * @param $url,请求地址 * @return bool|string */ function getRequest($url){ $headerArra ...
- (一)C++入门——指针与数组——Expression: _CrtIsValidHeapPointer(Block)
最近在入门c++,在看<c++ Primer Plus>一书.书中P106提到,删除使用New创建的数组时,是将指针重新指到第一个元素后,再进行的删除操作.代码如下: int *ptest ...
- Java中的float、double计算精度问题
java中的float.double计算存在精度问题,这不仅仅在java会出现,在其他语言中也会存在,其原因是出在IEEE 754标准上. 而java对此提供了一个用于浮点型计算的类——BigDeci ...
- T100——按xls格式批量导入数据
弹出File Browser窗口 PRIVATE FUNCTION cxrt020_open_file() DEFINE l_dir LIKE type_t.chr500 DEFINE r_succe ...
- Rust 优劣势: v.s. C++ / v.s. Go(持续更新)
Rust 发展速度比 C++ 强很多.如果去翻 open-std 的故纸堆,会发现 C++ 这边有很多人(包括标准委员会的人)提了有用的提案,但后来大多不了了之或经历了非常长的时间才进入标准. > ...
- python之paramiko 远程执行命令
有时会需要在远程的机器上执行一个命令,并获得其返回结果.对于这种情况,python 可以很容易的实现. 1 .工具 Python paramiko 1) Paramiko模块安装 在Linux的Ter ...