k-近邻(KNN) 算法预测签到位置
分类算法-k近邻算法(KNN):
定义:
如果一个样本在特征空间中的k个最相似 (即特征空间中最邻近) 的样本中的大多数属于某一个类别,则该样本也属于这个类别
来源:
KNN算法最早是由Cover和Hart提出的一种分类算法
计算距离公式:
两个样本的距离可以通过如下公式计算,又叫欧氏距离,比如说
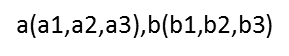
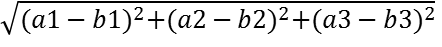
sklearn k-近邻算法API:


问题:
1. k值取多大?有什么影响?
k值取很小:容易受到异常点的影响
k值取很大:容易受最近数据太多导致比例变化
2. 性能问题
k-近邻算法的优缺点:
优点:
简单、易于理解,无需估计参数,无需训练
缺点:
懒惰算法,对测试样本分类时的计算量大,内存开销大
必须制定k值,k值选择不当则分类精度不能保证
使用场景:
小数据场景,几千~几万样本,具体场景具体业务去测试
k近邻算法实例-预测签到位置:
数据来源:
kaggle官网,链接地址:https://www.kaggle.com/c/facebook-v-predicting-check-ins/data (需官网登录后下载)
数据的处理:
1. 缩小数值范围: DataFrame.query(),因为数据量过大,所以获取部分数据
2. 处理日期数据: pd.to_datetime() 、pd.DatetimeIndex(),两个pandas库的接口
3. 增加分割的日期数据: 把源数据里面的时间戳数据转换分割后,添加为新列,day、hour等
4. 删除没用的数据: pd.drop() ,pandas库的接口
5. 将签到位置少于n个用户的数据删除,一些pandas库知识:
place_count = data.groupby('place_id').aggregate(np.count_nonzero)
tf = place_count[place_count.row_id>3].rest_index()
data = data[data['place_id'].isin(tf.place_id)]
实例流程:
1. 数据集的处理
2. 分割数据集
3. 对数据集进行表转化
4. estimator流程进行分类预测
代码实现:
import os
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler def knn_cls():
"""K-近邻算法预测用户签到的位置""" # 一、读取数据
fb_location = os.path.join(os.path.join(os.path.curdir, 'data'), 'fb_location')
data = pd.read_csv(os.path.join(fb_location, 'train.csv'))
# print(data.head(10)) # 二、处理数据
# 1.缩小数据,查询数据筛选
data = data.query('x>1.0 & x<1.25 & y>2.5 & y<2.75')
# 2.处理时间的数据
time_value = pd.to_datetime(data['time'], unit='s') # 精确到秒
# print(time_value)
# 3.把日期格式转化为字典格式
time_value = pd.DatetimeIndex(time_value)
# 4.构造一些特征
data.loc[:,'day'] = time_value.day
data.loc[:,'hour'] = time_value.hour
data.loc[:,'weekday'] = time_value.weekday
# 5.把时间戳特征删除
data.drop(['time'], axis=1, inplace=True)
# print(data)
# 6.把签到数量小于n个目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id>3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 7.取出特征值和目标值
y = data['place_id']
x = data.drop(['place_id', 'row_id'], axis=1)
# 8.进行数据的分割,训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25) # 三、特征工程(标准化)
std = StandardScaler()
# 对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test) # 这里用std.transform就不用fit去重新计算平均值标准差一类的了 # 四、进行算法流程
knn = KNeighborsClassifier(n_neighbors=9) # fit, predict, score
knn.fit(x_train, y_train) # 四、得出预测结果和准确率
y_predict = knn.predict(x_test)
print('预测的目标签到位置为:', y_predict)
print('预测的准确率: ', knn.score(x_test, y_test)) if __name__ == '__main__':
knn_cls()
k-近邻(KNN) 算法预测签到位置的更多相关文章
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- 机器学习-K近邻(KNN)算法详解
一.KNN算法描述 KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表.KNN算法属于有监督学习方式的分类算法,所谓K近 ...
- 查看neighbors大小对K近邻分类算法预测准确度和泛化能力的影响
代码: # -*- coding: utf-8 -*- """ Created on Thu Jul 12 09:36:49 2018 @author: zhen &qu ...
- [Python] 应用kNN算法预测豆瓣电影用户的性别
应用kNN算法预测豆瓣电影用户的性别 摘要 本文认为不同性别的人偏好的电影类型会有所不同,因此进行了此实验.利用较为活跃的274位豆瓣用户最近观看的100部电影,对其类型进行统计,以得到的37种电影类 ...
- TensorFlow实现knn(k近邻)算法
首先先介绍一下knn的基本原理: KNN是通过计算不同特征值之间的距离进行分类. 整体的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于 ...
- k近邻(KNN)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合内容: 1.算法概述 K近邻算法是一种基本分类和回归方法:分类时,根据其K个最近邻的训练实例的类 ...
- K近邻分类算法实现 in Python
K近邻(KNN):分类算法 * KNN是non-parametric分类器(不做分布形式的假设,直接从数据估计概率密度),是memory-based learning. * KNN不适用于高维数据(c ...
- 理解KNN算法中的k值-knn算法中的k到底指的是什么 ?
2019-11-09 20:11:26为方便自己收藏学习,转载博文from:https://blog.csdn.net/llhwx/article/details/102652798 knn算法是指对 ...
- k近邻 KNN
KNN是通过测量对象的不同特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20 ...
随机推荐
- scrapy框架之进阶
五大核心组件 - 引擎(Scrapy) 用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- Ubuntu 在VirtualBox里无法联网【已解决】
1. 在virtualBox中设置网络:设置->网络->将连接方式选定为“网络地址转换(NAT)” 点确定 2.进入Ubuntu系统中:系统设置->网络, 在弹出的对话框中选择:有线 ...
- JavaEE三大框架的整合
JavaEE三大框架的整合 ...
- CF1200B
CF1200B 解法: 贪心.当在第i列时,尽可能多的取走第i列的木块使得袋子里的木块尽可能多 CODE: #include<iostream> #include<cstdio> ...
- vue draggable 火狐拖拽搜索问题
最近在使用vuedraggable做导航时候,谷歌拖拽是没问题的,但是在火狐测试时候,拖拽时候是可以成功,但是火狐还是打开了一个新的tab,并且搜索了,一开始想着是阻止默认行为,但是在@end时间中阻 ...
- 启动Docker后台容器,测试运行Hello-world
1.使用docker run hello-world命令运行测试hello-world镜像,如下: 2.run 命令都干了什么?如下图: 3.为什么Docker比vm快?
- Flutter子组件调用父组件方法修改父组件参数
子组件调用父级组件方法的主要实现是父组件给子组件传入一个方法,然后在子组件中调用父级方法来修改父级的参数.看一下效果图 父级组件实现 在父级组件中写一个_editParentText的方法来修改组件中 ...
- arcgis python 随机取部分数据
# -*- coding: cp936 -*- import arcpy import os import ylpy import random def main(): num=ylpy.getCou ...
- fidder修改参数
进入截栏模式 inspectors,webfroms run
- MVVM的项目学习和笔记
今天在学习一个用MVVM模式写的项目,掌握一下对MVVM的理解和记的一些笔记. 下面是自己学习的项目链接: http://www.code4app.com/ios/一个MVVM架构的iOS工程/695 ...