day04_XPATH提取数据
1、XML简介
1.1、定义
可扩展标记语言(EXtensible Markup Language)
1.2、特点
- 一种标记语言,很类似 HTML
- XML 的标签需要我们自行定义
- 被设计为具有自我描述性的半结构化数据
1.3、作用
- 设计宗旨是用来传输数据
- 可以作为一些应用的配置文件
1.4、xml和html的区别
- 语法要求不同
- xml的语法要求更严格
- html不区分大小写
- html的语法不严格,如果上下文清楚地显示出段落或者标签在何处结束,他可以省略尾标签。但是xml不能省略任何标签。
- 作用不同
- xml主要用来传输数据
- html主要用来显示数据
- 标记不同
- xml没有固定的标记
- html的标签都是有特殊含义的,不能自定义
2、XML节点关系
2.1、父(Parent)
每个元素以及属性都有一个父。
下面是一个简单的XML例子中,book 元素是 title、author、year 以及 price 元素的父:
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
2.2、子(Children)
元素节点可有零个、一个或多个子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
2.3、同胞(Sibling)
拥有相同的父的节点
在下面的例子中,title、author、year 以及 price 元素都是同胞:
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
2.4、先辈(Ancestor)
某节点的父、父的父,等等。
在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素:
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
2.5、后代(Descendant)
某个节点的子,子的子,等等。
在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素:
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
3、XPATH
3.1、什么是XPath
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
3.2、选取节点
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
下面列出了最常用的路径表达式:
| 表达式 | 描述 |
|---|---|
nodename |
选取此节点的所有子节点。 |
/ |
从根节点选取。 |
// |
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
. |
选取当前节点。 |
.. |
选取当前节点的父节点。 |
@ |
选取属性。 |
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
3.3、谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()❤️] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
3.4、选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| html/node()/meta/@* | 选择html下面任意节点下的meta节点的所有属性 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
3.5、选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
3.6、XPath的运算符
下面列出了可用在 XPath 表达式中的运算符:
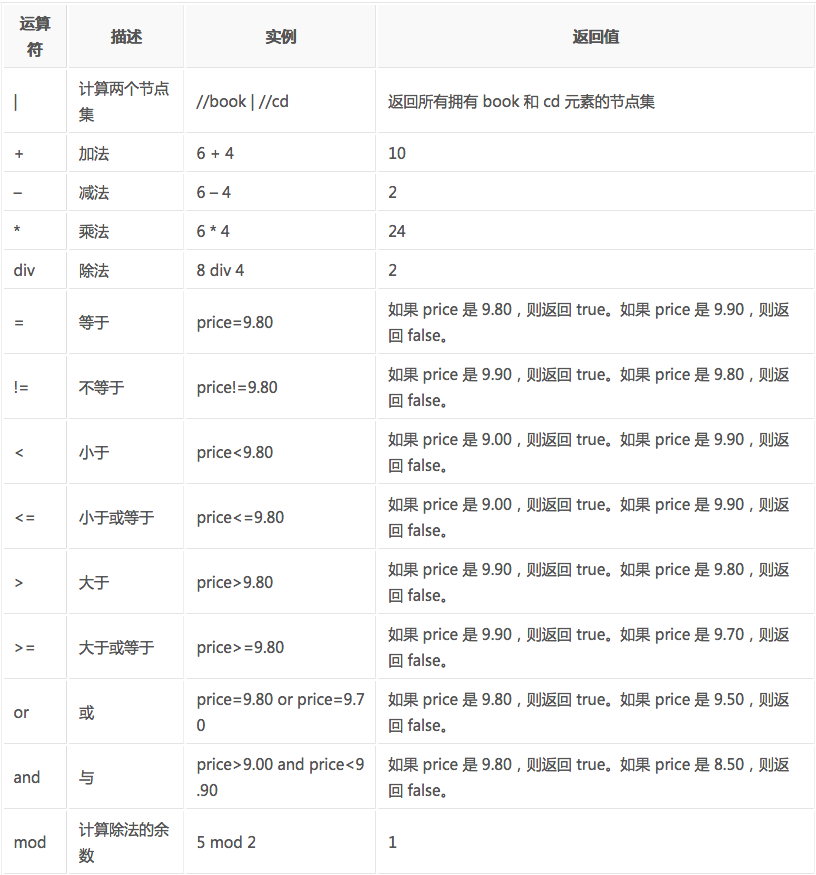
这些就是XPath的语法内容,在运用到Python抓取时要先转换为xml。
4、lxml模块
4.1、lxml简介与安装
xml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
lxml python 官方文档:http://lxml.de/index.html
需要安装C语言库,可使用 pip 安装:
pip install lxml(或通过wheel方式安装)
4.2、初步使用
# 使用 lxml 的 etree 库
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a> # ...
</ul>
</div>
'''
# 将字符串解析成HTML文档(Element对象)
tree = etree.HTML(text)
# print(tree)
# 将Element对象转成字符串
html_str = etree.tostring(tree, pretty_print=True).decode('utf-8')
print(html_str)
输出结果:
<html>
<body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a># ...
</li></ul>
</div>
</body>
</html>
xml 可以自动修正 html 代码,例子里不仅补全了 li 标签,还添加了 body,html 标签。
4.3、文件读取
除了直接读取字符串,lxml还支持从文件里读取内容。我们新建一个hello.html文件:
<!-- hello.html -->
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
再利用 etree.parse() 方法来读取文件。
from lxml import etree
# 读取外部文件 test01.html
tree = etree.parse('./test01.html')
html_str = etree.tostring(tree, pretty_print=True).decode('utf-8')
print(html_str)
输出结果与之前相同:
<!-- test01.html -->
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
4.4、XPath实例测试
1、获取所有的 <li> 标签
from lxml import etree
html = etree.parse('./test01.html')
print(type(html)) # 显示etree.parse() 返回类型
lis = html.xpath('//li')
print(lis) # 打印<li>标签的元素集合
print(len(lis))
print(type(lis))
print(type(lis[0]))
输出结果:
<class 'lxml.etree._ElementTree'>
[<Element li at 0x3c81ec8>, <Element li at 0x3c81fc8>, <Element li at 0x3c99048>, <Element li at 0x3c99088>, <Element li at 0x3c990c8>]
5
<class 'list'>
<class 'lxml.etree._Element'>
2、获取<li> 标签的所有 class属性
from lxml import etree
html = etree.parse('./test01.html')
result = html.xpath('//li/@class')
print result
运行结果
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
3、 获取<li>标签下href 为 link1.html 的 <a> 标签
from lxml import etree
html = etree.parse('./test01.html')
result = html.xpath('//li/a[@href="link1.html"]')
print result
运行结果
[<Element a at 0x10ffaae18>]
4、 获取<li>标签下所有的 <span> 标签
from lxml import etree
html = etree.parse('./test01.html')
#result = html.xpath('//li/span')
#注意这么写是不对的:
#因为 / 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠
result = html.xpath('//li//span')
print result
运行结果
[<Element span at 0x10d698e18>]
5、 获取<li>标签下<a>标签里的所有的 class
from lxml import etree
html = etree.parse('./test01.html')
result = html.xpath('//li/a//@class')
print result
运行结果
['blod']
6、 获取最后一个 <li> 的 <a> 的 href
from lxml import etree
html = etree.parse('./test01.html')
result = html.xpath('//li[last()]/a/@href')
# 谓语 [last()] 可以找到最后一个元素
print result
运行结果
['link5.html']
7、获取倒数第二个<li>中<a>元素的内容
from lxml import etree
html = etree.parse('./test01.html')
result = html.xpath('//li[last()-1]/a')
# text 方法可以获取元素内容
print result[0].text
运行结果
fourth item
8、获取 class 值为 bold 的标签名
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//*[@class="bold"]')
# tag方法可以获取标签名
print result[0].tag
运行结果
span
5、正则与lxml综合应用案例
day04_XPATH提取数据的更多相关文章
- [数据科学] 从csv, xls文件中提取数据
在python语言中,用丰富的函数库来从文件中提取数据,这篇博客讲解怎么从csv, xls文件中得到想要的数据. 点击下载数据文件http://seanlahman.com/files/databas ...
- 曲线提取数据Engauge Digitizer
可导出CSV格式数据 其它参考: http://blog.sina.com.cn/s/blog_4ae65b4d0100z8cg.html 其它曲线提取数据的软件还有: GetData.Windig ...
- 提取数据用strpos函数比较,预期和实际不符问题解决
在我提取数据时,数据是一串字符串,第一个数据和要比较的字符是相等的可是却是相反的结果 . 测试if(0==false)结果如图 执行结果 说明0和false相等.我的程序开始是这样的 第一个数据是正确 ...
- 提取数据表保存为XML文件
//连接数据库 SqlConnection con = new SqlConnection("server=****;database=****;uid=sa;pwd=********&qu ...
- 从数据库提取数据通过jstl显示在jsp页面上
从数据库提取数据通过jstl显示在jsp页面上 1.ConnectDB.java连接数据库,把数据转换成list public class ConnectDB { private final stat ...
- 处理文本,提取数据的脚本-主要就是用sed
处理文本,提取数据的脚本 #! /bin/sh | sed 's/)<\/small><\/td><td>/\n/g' # 用换行符替换 # 删除带有分号的行 # ...
- 002 requests的使用方法以及xpath和beautifulsoup4提取数据
1.直接使用url,没用headers的请求 import requests url = 'http://www.baidu.com' # requests请求用get方法 response = re ...
- matlab从曲线图提取数据
同学用肉体一顿饭让我帮他做下这个DDL 样图是一张非常扭曲的三虚线图他甚至想OCR识别x轴y轴坐标单位 上谷歌查了查,对于曲线图提取数据基本上是手动在曲线上取几个点,然后由这个几个点开始遍历领域点,判 ...
- scrapy框架Selector提取数据
从页面中提取数据的核心技术是HTTP文本解析,在python中常用的模块处理: BeautifulSoup 非常流行的解析库,API简单,但解析的速度慢. lxml 是一套使用c语言编写的xml解析 ...
随机推荐
- 1632:【 例 2】[NOIP2012]同余方程
#include<bits/stdc++.h> #define ll long long using namespace std; void Exgcd(ll a,ll b,ll & ...
- 1628:X-factor Chain
1628:X-factor Chain 时间限制: 1000 ms 内存限制: 524288 KB提交数: 122 通过数: 68 [题目描述] 原题来自 POJ 3421 输 ...
- Js 之移动端图片上传插件mbUploadify
一.下载 https://pan.baidu.com/s/1NEL4tkHoK4ydqdMi_hgWcw 提取码:vx7e 二.Demo示例 <div class="weui_uplo ...
- 一个XP SP3调用0地址蓝屏BUG
0x00 蓝屏的堆栈 在XP SP3上跑POC之后,一段时间之后会出现蓝屏,蓝屏的堆栈如下,可以看出是ACKData里面CALL了一个0指针导致的蓝屏 0x01 蓝屏原因 1 ETW(Event Tr ...
- Axure实现提示文本单击显示后自动消失的效果
Axure实现提示文本单击显示后自动消失的效果 方法/步骤 如图所示,框出的部分为提示文本(已经命名为tooltip),希望达到的效果是默认加载时不显示,点击帮助图标后显示,且2秒后自动消失. ...
- 黑马vue---46、vue使用过渡类名实现动画
黑马vue---46.vue使用过渡类名实现动画 一.总结 一句话总结: vue动画的过渡类名的时间点中没有设置样式的话就是默认的样式 使用 transition 元素,把 需要被动画控制的元素,包裹 ...
- flask的post,get请求及获取不同格式的参数
flask的post,get请求及获取不同格式的参数 1 获取不同格式参数 1.0 获取json参数 Demo from flask import Flask, request, jsonify ap ...
- Robot Framework 学习资源汇总
学习网站 http://robotframework.org/ http://www.testtao.cn/?cat=43 https://www.jianshu.com/c/483e8ffcbc79 ...
- 二进制安装k8s-单个master节点、两个node--修改版--有个错误:好多地方确少APISERVER
centos7.4安装k8s-.11版本,二进制 安装 配置系统相关参数 如下操作在所有节点操作 # 临时禁用selinux # 永久关闭 修改/etc/sysconfig/selinux文件设置 s ...
- Spring Security(3):配置与自动配置的介绍及源码分析
基于注解的配置(Java Configuration)从Spring Security 3.2开始就已经支持,本篇基于Spring boot注解的配置进行讲解,如果需要基于XML配置(Security ...