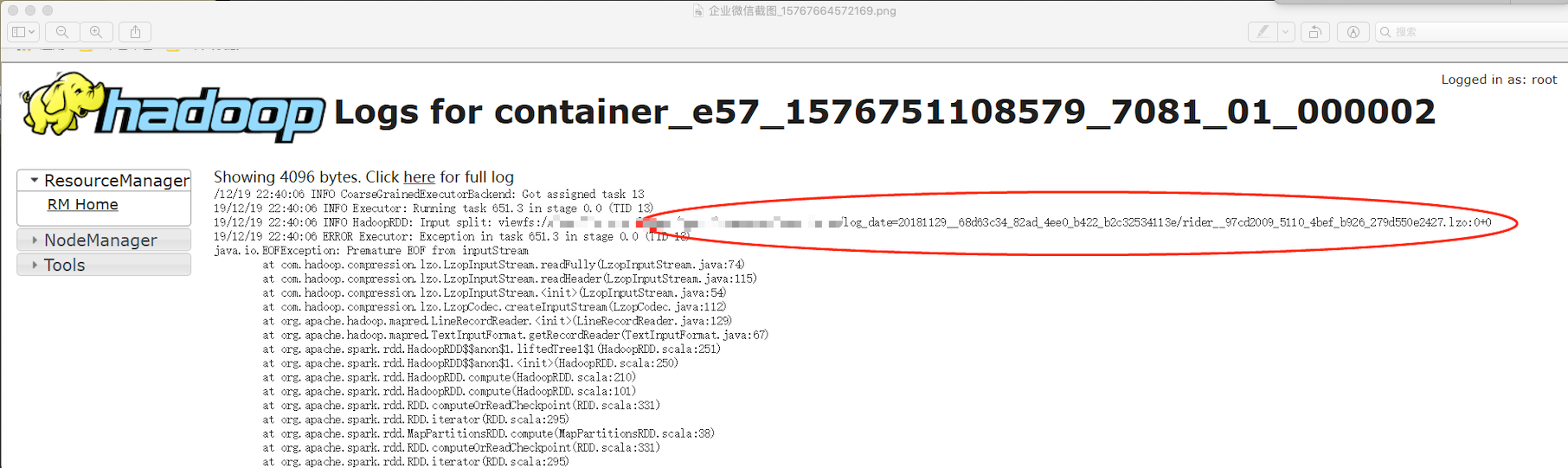
spark 执行报错 java.io.EOFException: Premature EOF from inputStream
使用spark2.4跟spark2.3 做替代公司现有的hive选项。
跑个别任务spark有以下错误
java.io.EOFException: Premature EOF from inputStream
at com.hadoop.compression.lzo.LzopInputStream.readFully(LzopInputStream.java:74)
at com.hadoop.compression.lzo.LzopInputStream.readHeader(LzopInputStream.java:115)
at com.hadoop.compression.lzo.LzopInputStream.<init>(LzopInputStream.java:54)
at com.hadoop.compression.lzo.LzopCodec.createInputStream(LzopCodec.java:112)
at org.apache.hadoop.mapred.LineRecordReader.<init>(LineRecordReader.java:129)
at org.apache.hadoop.mapred.TextInputFormat.getRecordReader(TextInputFormat.java:67)
at org.apache.spark.rdd.HadoopRDD$$anon$1.liftedTree1$1(HadoopRDD.scala:269)
at org.apache.spark.rdd.HadoopRDD$$anon$1.<init>(HadoopRDD.scala:268)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:226)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:97)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.rdd.UnionRDD.compute(UnionRDD.scala:105)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:330)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:294)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
排查原因 发现是读取0 size 大小的文件时出错
并没有发现spark官方有修复该bug
手动修改代码 过滤掉这种文件
在 HadoopRDD.scala 类相应位置修改如图即可
// We get our input bytes from thread-local Hadoop FileSystem statistics.
// If we do a coalesce, however, we are likely to compute multiple partitions in the same
// task and in the same thread, in which case we need to avoid override values written by
// previous partitions (SPARK-13071).
private def updateBytesRead(): Unit = {
getBytesReadCallback.foreach { getBytesRead =>
inputMetrics.setBytesRead(existingBytesRead + getBytesRead())
}
} private var reader: RecordReader[K, V] = null
private val inputFormat = getInputFormat(jobConf)
HadoopRDD.addLocalConfiguration(
new SimpleDateFormat("yyyyMMddHHmmss", Locale.US).format(createTime),
context.stageId, theSplit.index, context.attemptNumber, jobConf) reader =
try {
if (split.inputSplit.value.getLength != 0) { //文件大小不为零 采取读取
inputFormat.getRecordReader(split.inputSplit.value, jobConf, Reporter.NULL)
} else {
logWarning(s"Skipped the file size 0 file: ${split.inputSplit}")
finished = true //大小为0 即结束 跳过
null
}
} catch {
case e: FileNotFoundException if ignoreMissingFiles =>
logWarning(s"Skipped missing file: ${split.inputSplit}", e)
finished = true
null
// Throw FileNotFoundException even if `ignoreCorruptFiles` is true
case e: FileNotFoundException if !ignoreMissingFiles => throw e
case e: IOException if ignoreCorruptFiles =>
logWarning(s"Skipped the rest content in the corrupted file: ${split.inputSplit}", e)
finished = true
null
}
// Register an on-task-completion callback to close the input stream.
context.addTaskCompletionListener[Unit] { context =>
// Update the bytes read before closing is to make sure lingering bytesRead statistics in
// this thread get correctly added.
updateBytesRead()
closeIfNeeded()
}
spark 执行报错 java.io.EOFException: Premature EOF from inputStream的更多相关文章
- 关于spark入门报错 java.io.FileNotFoundException: File file:/home/dummy/spark_log/file1.txt does not exist
不想看废话的可以直接拉到最底看总结 废话开始: master: master主机存在文件,却报 执行spark-shell语句: ./spark-shell --master spark://ma ...
- Spark启动报错|java.io.FileNotFoundException: File does not exist: hdfs://hadoop101:9000/directory
at org.apache.spark.deploy.history.FsHistoryProvider.<init>(FsHistoryProvider.scala:) at org.a ...
- hadoop MR 任务 报错 "Error: java.io.IOException: Premature EOF from inputStream at org.apache.hadoop.io"
错误原文分析 文件操作超租期,实际上就是data stream操作过程中文件被删掉了.一般是由于Mapred多个task操作同一个文件.一个task完毕后删掉文件导致. 这个错误跟dfs.datano ...
- hbase_异常_03_java.io.EOFException: Premature EOF: no length prefix available
一.异常现象 更改了hadoop的配置文件:core-site.xml 和 mapred-site.xml 之后,重启hadoop 和 hbase 之后,发现hbase日志中抛出了如下异常: ...
- Spark报错java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Spark 读取 JSON 文件时运行报错 java.io.IOException: Could not locate executable null\bin\winutils.exe in the ...
- 关于SpringMVC项目报错:java.io.FileNotFoundException: Could not open ServletContext resource [/WEB-INF/xxxx.xml]
关于SpringMVC项目报错:java.io.FileNotFoundException: Could not open ServletContext resource [/WEB-INF/xxxx ...
- Kafka 启动报错java.io.IOException: Can't resolve address.
阿里云上 部署Kafka 启动报错java.io.IOException: Can't resolve address. 本地调试的,报错 需要在本地添加阿里云主机的 host 映射 linux ...
- 文件上传报错java.io.FileNotFoundException拒绝访问
局部代码如下: File tempFile = new File("G:/tempfileDir"+"/"+fileName); if(!tempFile.ex ...
- 完美解决JavaIO流报错 java.io.FileNotFoundException: F:\ (系统找不到指定的路径。)
完美解决JavaIO流报错 java.io.FileNotFoundException: F:\ (系统找不到指定的路径.) 错误原因 读出文件的路径需要有被拷贝的文件名,否则无法解析地址 源代码(用 ...
随机推荐
- 运算符重载之new与delete
关于new/delete,援引C++ Primer中的一段话: 某些应用程序对内存分配有特殊的要求,因此我们无法直接将标准的内存管理机制直接应用于这些程序.他们常常需要自定义内存分配的细节,比如使用关 ...
- sizeof +数组名
链接:https://www.nowcoder.com/questionTerminal/daa5422cb468473c9e6e75cc98b771de 来源:牛客网 sizeof一个数组名称的时候 ...
- 8月清北学堂培训 Day4
今天上午是赵和旭老师的讲授~ 概率与期望 dp 概率 某个事件 A 发生的可能性的大小,称之为事件 A 的概率,记作 P ( A ) . 假设某事的所有可能结果有 n 种,每种结果都是等概率,事件 A ...
- Appium Inspector定位Webview/H5页面元素
目录 操作步骤 Python操作该混合App代码 Appium在操作混合App或Android App的H5页面时, 常常需要定位H5页面中的元素, 传统方式是 翻墙 + 使用Chrome://ins ...
- 爬虫之解析库Xpath
简介 XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言. XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力.起初XPat ...
- golang中文件以及文件夹路径相关操作
获取目录中所有文件使用包: io/ioutil 使用方法: ioutil.ReadDir 读取目录 dirmane 中的所有目录和文件(不包括子目录) 返回读取到的文件的信息列表和读取过程中遇到的任何 ...
- Intellij IDEA导入JAVA项目并启动(哈哈哈,天天都有人问)
最近有很多同学,竟然不知道如何使用Intellij IDEA打开Java项目并启动 现在来讲一下,希望不要忘记了 1.打开IDEA开机页面 Maven项目 2.Maven项目是以pom文件引入各项ja ...
- List和Set 总结
一 List三个子类的区别和应用场景 Vector:底层是数组,查询快,增删慢 Arraylist:底层是数组,查询块,增删慢 LinkedList:底层是链表,查询慢,增删快 效率: Vector: ...
- <JavaScript> 匿名函数和闭包的区别
匿名函数:没有名字的函数:并没有牵扯到应用其他函数的变量问题.仅仅是没有名字. 定义方式: 1,var A = function(){ }; 2, (function (x,y){ })(2,3); ...
- 阶段5 3.微服务项目【学成在线】_day02 CMS前端开发_03-vuejs研究-vuejs基础-入门程序
本次测试我们在门户目录中创建一个html页面进行测试,正式的页面管理前端程序会单独创建工程. 在门户目录中创建vuetest目录,并且在目录下创建vue_01.html文件 <!DOCTYPE ...