DFS(深度优先搜索)和BFS(广度优先搜索)
深度优先搜索算法(Depth-First-Search)
深度优先搜索算法(Depth-First-Search),是搜索算法的一种。
这一过程一直进行到已发现从源节点可达的所有节点为止。
如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
深度优先搜索是图论中的经典算法,利用深度优先搜索算法可以产生目标图的相应拓扑排序表,利用拓扑排序表可以方便的解决很多相关的图论问题,如最大路径问题等等。一般用堆数据结构来辅助实现DFS算法。
DFS属于盲目搜索
深度优先遍历图算法步骤:
- 访问顶点v;
- 依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
- 若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。
实例:
DFS 在访问图中某一起始顶点 v 后,由 v 出发,访问它的任一邻接顶点 w1;再从 w1 出发,访问与 w1邻 接但还没有访问过的顶点 w2;然后再从 w2 出发,进行类似的访问,… 如此进行下去,直至到达所有的邻接顶点都被访问过的顶点 u 为止。
接着,退回一步,退到前一次刚访问过的顶点,看是否还有其它没有被访问的邻接顶点。如果有,则访问此顶点,之后再从此顶点出发,进行与前述类似的访问;如果没有,就再退回一步进行搜索。重复上述过程,直到连通图中所有顶点都被访问过为止。
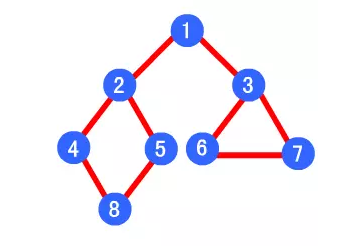
例如下图,其深度优先遍历顺序为 1->2->4->8->5->3->6->7
广度优先搜索算法(Breadth-First-Search)
广度优先搜索算法(Breadth-First-Search),是一种图形搜索算法。
简单的说,BFS是从根节点开始,沿着树(图)的宽度遍历树(图)的节点。
如果所有节点均被访问,则算法中止。
BFS同样属于盲目搜索。
一般用队列数据结构来辅助实现BFS算法。
算法步骤:
- 首先将根节点放入队列中。
- 从队列中取出第一个节点,并检验它是否为目标。如果找到目标,则结束搜寻并回传结果。否则将它所有尚未检验过的直接子节点加入队列中。
- 若队列为空,表示整张图都检查过了——亦即图中没有欲搜寻的目标。结束搜寻并回传“找不到目标”。
- 重复步骤2。
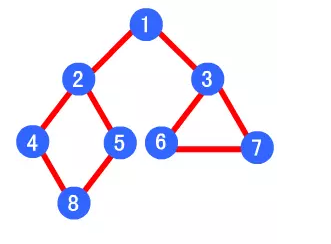
如下图,其广度优先算法的遍历顺序为:1->2->3->4->5->6->7->8
import java.util.ArrayDeque;
public class BinaryTree {
static class TreeNode{
int value;
TreeNode left;
TreeNode right;
public TreeNode(int value){
this.value=value;
}
} TreeNode root;
public BinaryTree(int[] array){
root=makeBinaryTreeByArray(array,1);
}
/**
* 采用递归的方式创建一颗二叉树
* 传入的是二叉树的数组表示法
* 构造后是二叉树的二叉链表表示法
*/
public static TreeNode makeBinaryTreeByArray(int[] array,int index){
if(index<array.length){
int value=array[index];
if(value!=0){
TreeNode t=new TreeNode(value);
array[index]=0;
t.left=makeBinaryTreeByArray(array,index*2);
t.right=makeBinaryTreeByArray(array,index*2+1);
return t;
}
}
return null;
} /**
* 深度优先遍历,相当于先根遍历
* 采用非递归实现
* 需要辅助数据结构:栈
*/
public void depthOrderTraversal(){
if(root==null){
System.out.println("empty tree");
return;
}
ArrayDeque<TreeNode> stack=new ArrayDeque<TreeNode>();
stack.push(root);
while(stack.isEmpty()==false){
TreeNode node=stack.pop();
System.out.print(node.value+" ");
if(node.right!=null){
stack.push(node.right);
}
if(node.left!=null){
stack.push(node.left);
}
}
System.out.print("\n");
}
/**
* 广度优先遍历
* 采用非递归实现
* 需要辅助数据结构:队列
*/
public void levelOrderTraversal(){
if(root==null){
System.out.println("empty tree");
return;
}
ArrayDeque<TreeNode> queue=new ArrayDeque<TreeNode>();
queue.add(root);
while(queue.isEmpty()==false){
TreeNode node=queue.remove();
System.out.print(node.value+" ");
if(node.left!=null){
queue.add(node.left);
}
if(node.right!=null){
queue.add(node.right);
}
}
System.out.print("\n");
}
/**
* 13
* / \
* 65 5
* / \ \
* 97 25 37
* / /\ /
* 22 4 28 32
*/
public static void main(String[] args) {
int[] arr={0,13,65,5,97,25,0,37,22,0,4,28,0,0,32,0};
BinaryTree tree=new BinaryTree(arr);
tree.depthOrderTraversal();
tree.levelOrderTraversal();
}
}
DFS(深度优先搜索)和BFS(广度优先搜索)的更多相关文章
- 0算法基础学算法 搜索篇第二讲 BFS广度优先搜索的思想
dfs前置知识: 递归链接:0基础算法基础学算法 第六弹 递归 - 球君 - 博客园 (cnblogs.com) dfs深度优先搜索:0基础学算法 搜索篇第一讲 深度优先搜索 - 球君 - 博客园 ( ...
- BFS广度优先搜索 poj1915
Knight Moves Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 25909 Accepted: 12244 Descri ...
- 图的遍历BFS广度优先搜索
图的遍历BFS广度优先搜索 1. 简介 BFS(Breadth First Search,广度优先搜索,又名宽度优先搜索),与深度优先算法在一个结点"死磕到底"的思维不同,广度优先 ...
- 算法竞赛——BFS广度优先搜索
BFS 广度优先搜索:一层一层的搜索(类似于树的层次遍历) BFS基本框架 基本步骤: 初始状态(起点)加到队列里 while(队列不为空) 队头弹出 扩展队头元素(邻接节点入队) 最后队为空,结束 ...
- 步步为营(十六)搜索(二)BFS 广度优先搜索
上一篇讲了DFS,那么与之相应的就是BFS.也就是 宽度优先遍历,又称广度优先搜索算法. 首先,让我们回顾一下什么是"深度": 更学术点的说法,能够看做"单位距离下,离起 ...
- 关于宽搜BFS广度优先搜索的那点事
以前一直知道深搜是一个递归栈,广搜是队列,FIFO先进先出LILO后进后出啥的.DFS是以深度作为第一关键词,即当碰到岔道口时总是先选择其中的一条岔路前进,而不管其他岔路,直到碰到死胡同时才返回岔道口 ...
- GraphMatrix::BFS广度优先搜索
查找某一结点的邻居: virtual int firstNbr(int i) { return nextNbr(i, n); } //首个邻接顶点 virtual int nextNbr(int i, ...
- [MIT6.006] 13. Breadth-First Search (BFS) 广度优先搜索
一.图 在正式进入广度优先搜索的学习前,先了解下图: 图分为有向图和无向图,由点vertices和边edges构成.图有很多应用,例如:网页爬取,社交网络,网络传播,垃圾回收,模型检查,数学推断检查和 ...
- DFS+BFS(广度优先搜索弥补深度优先搜索遍历漏洞求合格条件总数)--09--DFS+BFS--蓝桥杯剪邮票
题目描述 如下图, 有12张连在一起的12生肖的邮票.现在你要从中剪下5张来,要求必须是连着的.(仅仅连接一个角不算相连) 比如,下面两张图中,粉红色所示部分就是合格的剪取. 请你计算,一共有多少 ...
随机推荐
- XMl特殊字符转换参考
参考链接:https://blog.csdn.net/goon_star/article/details/49636505 处理SVG Text元素不能正确显示特殊字符 特殊符号 命名实体 十进制编码 ...
- maven的概念-02
1.仓库 仓库分为两类: 1) 本地仓库 ->当前电脑上的maven仓库: 本地仓库的默认目录: ${user.home}/.m2/repository ...
- 【Python之路】特别篇--多线程与多进程
并发 与 并行 的区别: 解释一:并发是在同一实体上的多个事件,并行是在不同实体上的多个事件: 解释二:并发是指两个或多个事件在同一时间间隔发生,而并行是指两个或者多个事件在同一时刻发生. 并发:就是 ...
- 日照学习提高班day4测试
A 思路: 一看到这个题,他不仅要求输出字典序最小的串,还要满足两两不重复,所以我们可以先输出ababab...什么的,最后缀上要求的k-2种字母 坑点: 当然这样想是不完全的!该题是拥有许多特殊情况 ...
- 【CUDA 基础】4.2 内存管理
title: [CUDA 基础]4.2 内存管理 categories: - CUDA - Freshman tags: - CUDA内存管理 - CUDA内存分配和释放 - CUDA内存传输 - 固 ...
- “美登杯”上海市高校大学生程序设计邀请赛 (华东理工大学) E 小花梨的数组 线段树
题意 分析 预处理出每个数的最小素因子,首先可以知道\(minprime(x*minprime(x))=minprime(x)\),我们用线段树维护区间最大值\(mx[p]\),注意这里的最大值并不是 ...
- sublime 配置sftp代码自动上传(原)
1.首先安装Package Control 使用 ctrl+`快捷键 或者 菜单项View > Show Console 来调出命令界面 然后复制粘贴下面的Python代码到命令输入框中: im ...
- [CSP-S模拟测试]:任务分配(最短路+贪心+DP)
题目传送门(内部题149) 输入格式 每个测试点第一行为四个正整数$n,b,s,m$,含义如题目所述. 接下来$m$行,每行三个非负整数$u,v,l$,表示从点$u$到点$v$有一条权值为$l$的有向 ...
- 石川es6课程---9、面向对象-基础
石川es6课程---9.面向对象-基础 一.总结 一句话总结: js老版本的面向对象和继承都不是很方便,新版的面向对象向其它语言靠拢,有了class,extends,constructor等关键字,用 ...
- excel中如何设置只打印第一页
在打印表格时,怎样设置只打印第一页呢,操作很简单,下面,小编说下操作方法. 方法/步骤 打开要打印的工作表, 再点击“文件” 弹出的页面中,在左侧这里,点击“打印” 在右边弹出与打 ...