MySQL备忘点(上)
给自己看的,所以以举例子为主了
检索数据
SELECT 检索单列 SELECT name FROM student
检索多列 SELECT no, name FROM student
检索所有列 SELECT * FROM student
检索不同行 SELECT DISTINCT name, sex FROM student distinct修饰的select下的所有列,也就是说两条数据,name和sex中只要有一列不同,就算不同行了。
限制结果 SELECT no FROM student LIMIT 5 如果搜出来的行不足限制数,那么全输出
全限定表名 SELECT student.no FROM student
排序数据
ORDER BY 按单列排序 SELECT name FROM student ORDER BY no 未被检索的列(no字段)也是可以以其排序的
按多列排序 SELECT * FROM student ORDER BY birthday, sex 只有结果集中存在birthday相同的数据时,这些数据才会再按照sex排序
排序方向 SELECT * FROM student ORDER BY birthday DESC 从大到小排序,常见的情形是价格最贵的,日期最新的。
过滤数据
WHERE 单条件 SELECT name FROM student WHERE no=10
不匹配 SELECT name FROM student WHERE no!=10
范围 SELECT name FROM student WHERE no BETWEEN 1 AND 3 头尾都包含,即1、2、3
空值 SELECT name FROM student WHERE sex IS NULL
数据过滤
AND 多条件 SELECT name FROM student WHERE name='Deolin' AND sex=1
OR 多条件 SELECT name FROM student WHERE name='Deolin' OR name='Bld' 一般AND和OR共存的情况,直接有小括号保证计算次序,而不是通过记忆去依赖优先级
IN 范围 SELECT name FROM student WHERE name IN ('Deolin', 'Bld') in和or, 优先选用in,因为速度更快,易管理,更直观
NOT 否定单个条件 SELECT name FROM student WHERE NOT name IN ('Deolin1', 'Bld1')
通配符 为了效率,不过度使用;尽量不把通配符放在开始处
LIKE % 通配符匹配 SELECT name FROM student WHERE name LIKE 'D%n' 任何字符任何次数, name是'Dn' 'Deolin'…的数据都在范围内;LIKE '%'匹配不到null
LIKE _ 通配符匹配 SELECT name FROM student WHERE name LIKE 'Deol_n' 任何字符一次,只能1次,不能多也不能少
正则表达式
REGEXP
OR匹配 REGEXP '1000|2000' 匹配1000或2000
字符匹配 REGEXP '[ab12]ton' 匹配aton或bton或1ton或2ton
范围匹配 REGEXP '[0-9]' 相当于[0123456789]
REGEXP '[3-6]' 相当于[3456]
REGEXP '[b-d]' 相当于[bcd]
转义匹配 REGEXP '\\%' 匹配字符 %
元字符匹配 REGEXP '\\f' 换页 \\f换页 \\n换行 \\r回车 \\t制表 \\v纵向制表
字符类匹配 REGEXP '[:alnum:]' 相当于[a-zA-Z0-9],而且三者都得有
REGEXP '[:alpha:]' 相当于[a-zA-Z],而且两者都得有
REGEXP '[:digit:]' 相当于[0-9]
多匹配 {n} 指定匹配次数
{n,} 指定匹配次数不小于n
{n,M} 指定匹配次数为n至M
* 0次或多次匹配
+ 相当于{1,}
? 相当于{0,1}
定位匹配 ^ $ 文本开始至文本结束 举例:REGEXP '1000|2000' 会匹配到 h1000或sd2000之类的,但是REGEXP ^'1000|2000'$只会匹配到1000和2000两个
否定匹配 [^ ] ^出现在集合(指中括号)中时,用于否定集合里的表达式
计算字段
CONCAT() 字段拼接 SELECT CONCAT('The name is '+name+'.') FROM student
RTRIM() 去除右边空格 SELECT RTRIM(name) FROM student LTRIM()左边空格,TRIM()两边空格
AS 别名 SELECT (RTRIM(name)+sex) AS name FROM student 结合函数和列与列之间的算数运算使用
函数
文本处理
LEFT() / RIGHT() 文本的左/右边字符
LENGTH() 文本长度
LOWER() / UPPER() 转换为小/大写
日期 日期比较时,尽量用DATE()包裹字段;目标值的链接符号虽然/和-都可以,但尽量和字段一致,使用-
DATE() / TIME() 取出字段的年月日/时分秒
YEAR() / MONTH() / DAY() 取出字段的年/月/日
HOUR() / MINUTE() / SECOND() 取出字段的时/分/秒
NOW() 现在的日期和时间
DAYOFWEEK() 周几
汇总数据
聚集函数 如果是select count(no) as cnt, name from student,那么虽然cnt的值是一致的,但是还是会被复制到每个行中,因为结果集被name字段“撑开”了
AVG() 聚集结果集中某列的平均值,参数是非数字也可行,但是会返回奇怪的结果,avg()忽略null值
COUNT() 用的太多了,“聚集”的作用都可以参考count count()参数是列名时,会忽略列中的null值,null值不计入总数
MAX() 聚集结果集中某列的最大值
MIN() 聚集结果集中某列的最小值 min()会忽略null值
SUM() 聚集结果集中某列的和,参数是非数字也可行,但是会返回奇怪的结果
分组数据
GROUP BY 创建分组
HAVING 过滤分组
子查询
IN (SELECT…) 子查询作为检索条件的值(的集合)
SELECT (SELECT…) 子查询作为检索项目的计算值 注意这里要全限定表名
理解分组
创建分组(GROUP BY)
简单说就是把结果集按列隐式地分组成了很多个结果集,分组是个结果集;
既然分组是个“结果集”,那么select中的聚集函数会对每个分组分别计算,
可以认为,分组的目的就是为了使用聚集函数;
group by可以跟任意数量的列名,代表结合多个列进行分组;
group by后面不能跟聚集函数;
列中的null值是一个特殊值,区别与其他的非null值;

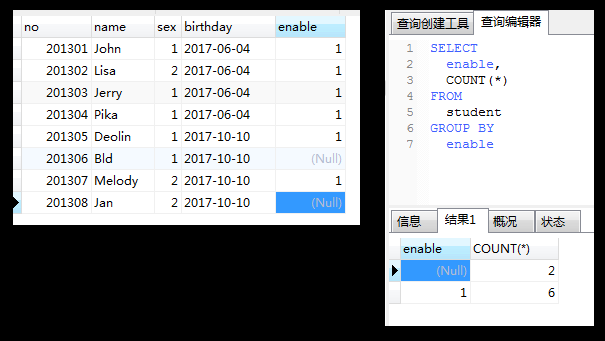
过滤分组(HAVING)
跟where非常相似,where的语法having几乎全适用;
where过滤的是整个结果集中不符合条件的每个数据,
having过滤的是整个结果集中符合条件的每个分组

MySQL备忘点(上)的更多相关文章
- MySQL备忘
Access denied for user 'root'@'localhost' >> 执行以下语句 GRANT ALL ON dbname.* TO 'root'@'localhost ...
- mysql -- 备忘
select distinct(authorid),author from forum_post where tid=1;
- MySQL备忘点(下)
联结表 创建联结 FROM 表1,表2 与内连接作用相同类似:如果失去WHERE子句,会出现笛卡尔积现象 内联结 INNER JOIN 高级联结 自联结 例子:SELECT 字段b FROM 表 WH ...
- centos 6.4 mysql rpm 离线安装【备忘】
离线状态下使用rpm的安装包进行mysql的安装,仅作备忘 准备工作: 官网下载mysql离线rpm安装包(这里就不演示了,拿现成的做演示) =================更新线 2018-01- ...
- Mysql又一次整理笔记--woods备忘
==============================SQL备忘 CRUD 查询 多表 事件等=============================== ------------------ ...
- Mysql CPU使用率长期100%的解决思路备忘
最近一台服务器的CPU使用率长期保持在100%的状态,查看进程发现是Mysql服务导致的.于是搜索各方资料,终于成功解决问题.备忘以及分享一下,希望可以帮助各位新手朋友. (服务器运行环境是Windo ...
- Nmap备忘单:从探索到漏洞利用(Part 4)
这是我们的Nmap备忘单的第四部分(Part 1. Part 2. Part 3).本文中我们将讨论更多东西关于扫描防火墙,IDS / IPS 逃逸,Web服务器渗透测试等.在此之前,我们应该了解一下 ...
- ExtJs4常用配置方法备忘
viewport布局常用属性 new Ext.Viewport({ layout: "border", renderTo: Ext.getBody(), defaults: { b ...
- MFC通过txt查找文件并进行复制-备忘
MFC基于对话框的Demo txt中每行一个23位的卡号. 文件夹中包含以卡号命名的图像文件.(fpt或者bmp文件) 要求遍历文件夹,找到txt中卡号所对应的图像文件,并复制出来. VC6.0写的. ...
随机推荐
- MySQL的explain语句分析
+----+-------------+-------+------------+------+---------------+-----+---------+------+------+------ ...
- MySQL 5.7 多源复制实践
多源复制使用场景 数据分析部门会需要各个业务部门的部分数据做数据分析,这个时候就可以用到多源复制把各个主数据库的数据复制到统一的数据库中. 在从服务器进行数据汇总,如果我们的主服务器进行了分库分表的操 ...
- JVM 介绍
JVM 介绍: JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的 ...
- AES密码算法详解(转自https://www.cnblogs.com/luop/p/4334160.html)
0 AES简介 我们知道数据加密标准(Data Encryption Standard: DES)的密钥长度是56比特,因此算法的理论安全强度是256.但二十世纪中后期正是计算机飞速发展的阶段,元器件 ...
- .NetCore如何使用ImageSharp进行图片的生成
ImageSharp是对NetCore平台扩展的一个图像处理方案,以往网上的案例多以生成文字及画出简单图形.验证码等方式进行探讨和实践. 今天我分享一下所在公司项目的实际应用案例,导出微信二维码图片, ...
- 两个重叠的div做前后翻转
当需要做一个翻转卡片式的div时候,需要两个div的大小等大例如: 画出两个等大的div后,将他们重叠 图中的两个div做了重叠,做重叠时候用的属性是 position: absolute; 并且需要 ...
- java_数据类型转换
一.自动转换 目的类型比原来的类型要大,两种数据类型是相互兼容的. byte--->short short--->int char--->int int--->long/dou ...
- Netty4实现JTT809对接
网上的使用的netty版本过老,最近自己接触到这一块,重新写了一个 服务器流程 1,判定报文起始和结束标识 ,2去掉头尾标识进行转义,3,去掉CRC码进行CRC计算,4读取报文头,(5,如果加密则解密 ...
- 【枚举】【lrj黑书】奇怪的问题(古老的智力题)
题目描述: 请回答下面的 10 个问题,你的回答应保证每题惟有你的选择是正确的. ⑴ 第一个答案是b 的问题是哪一个?(a )2 ( b ) 3 ( c ) 4 ( d ) 5 ( e ) 6⑵ 恰好 ...
- 中国大学MOOC课程信息之数据分析可视化一
版权声明:本文为博主原创文章,转载 请注明出处:https://blog.csdn.net/sc2079/article/details/82263391 9月2日更:中国大学MOOC课程信息之数据分 ...