Spark-2.0原理分析-shuffle过程
shuffle概览
shuffle过程概览
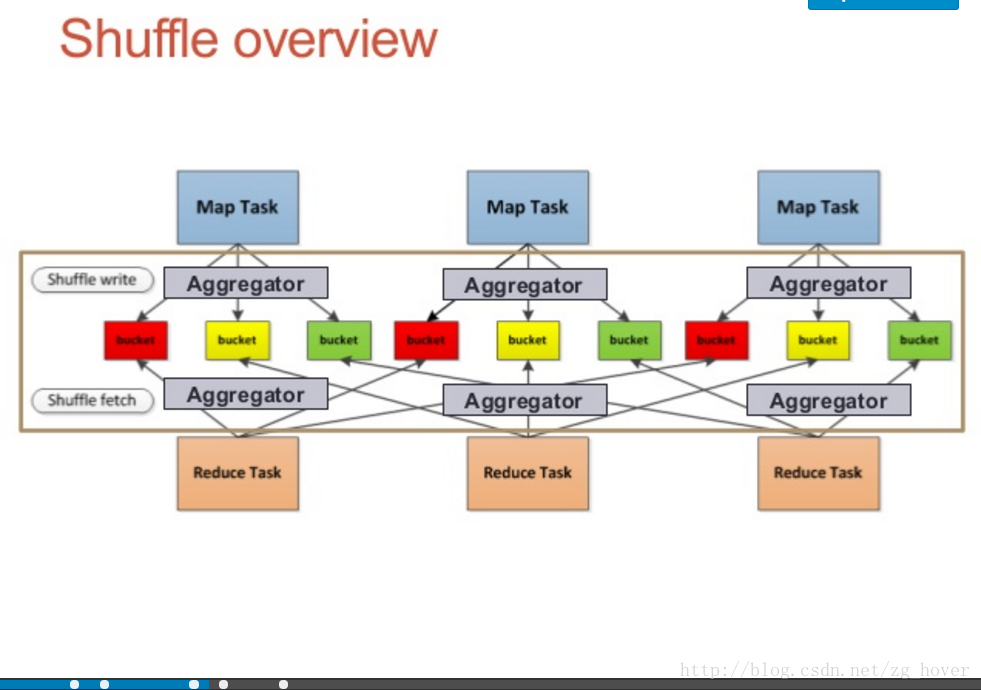
shuffle数据流概览
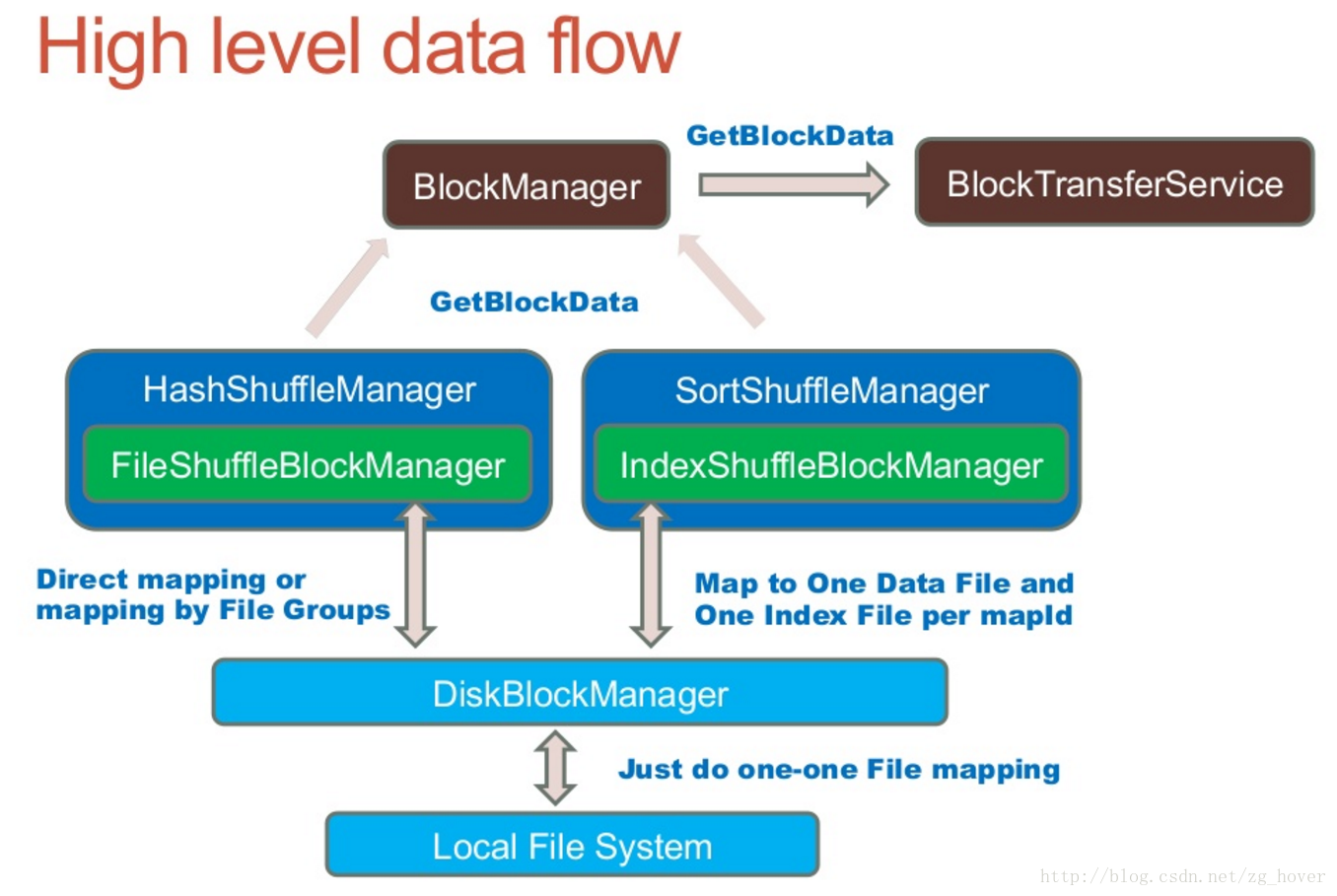
shuffle数据流
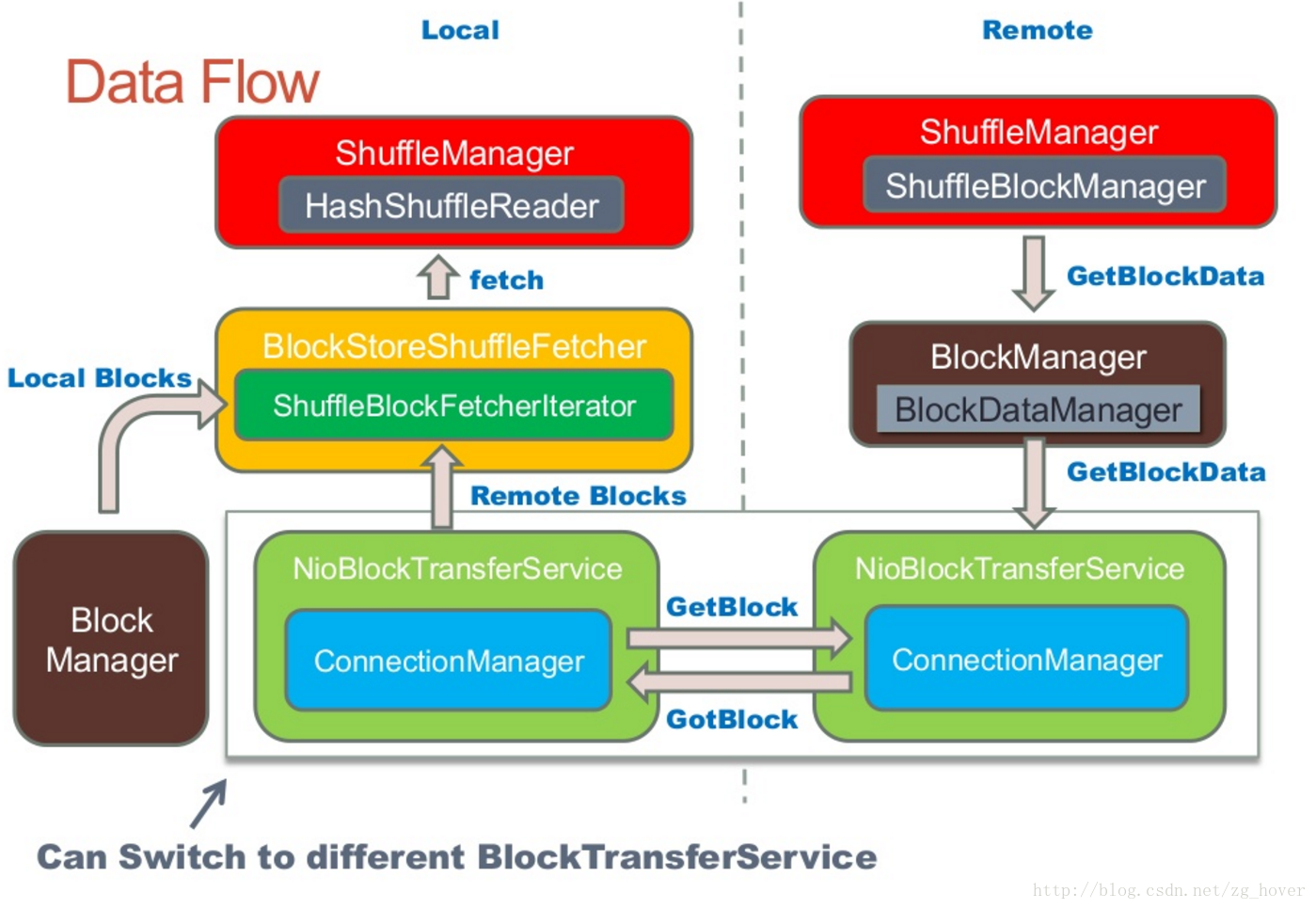
shuffle工作流程
在运行job时,spark是一个stage一个stage执行的。先把任务分成stage,在任务提交阶段会把任务形成taskset,在执行任务。
spark的DAGScheduler根据RDD的ShuffleDependency来构建Stages:
- 例如:ShuffleRDD/CoGroupedRDD有一个ShuffleDependency。
- 很多操作通过钩子函数来创建ShuffleRDD
每个ShuffleDependency会map到spark的job的一个stage,然后会导致一个shuffle过程。
为什么shuffle过程代价很大
这是由于shuffle过程可能需要完成以下过程:
- 重新进行数据分区
- 数据传输
- 数据压缩
- 磁盘I/O
shuffle的体系结构
ShuffleManager接口
shuffleManager是spark的shuffle系统的可插拔接口。ShuffleManager将会在driver和每个executor上的SparkEnv中进行创建。可以通过参数spark.shuffle.manager进行设置。
driver通过ShuffleManager来注册shuffle,并且executor通过它来读取和写入数据。
ShuffleWriter
控制shuffle数据输出逻辑。
ShuffleReader
获取shuffle过程中用于ShuffleRDD的数据。
ShuffleBlockManager
管理抽象的bucket和计算数据块之间的mapping过程。
基于sort的shuffle
sort-based的shuffle,会把输入的记录根据目标分区id(partition ids)进行排序。然后写入单个的map输出文件中。为了读取map的输出部分,Reducers获取此文件的连续区域 。当map输出的数据太大而内存无法存放时,输出的排序子集可以保存到磁盘,这些磁盘文件被合并后,生成最终的输出文件。
sort shuffle有两个不同的输出路径来产生map的输出文件:
- 序列化排序(Serialized sorting)
在使用序列化排序时,需要满足以下3个条件:- shuffle不指定聚合(aggregation)或输出排序方法。
- shuffle的序列化程序支持序列化值的重定位(KryoSerializer和Spark SQL的自定义序列化程序目前支持此操作)。
- shuffle产生小于16777216个输出分区。
- 反序列化排序(Deserialized sorting)
用来处理所有其他情况。
Sort Shuffle Manager
Sort Shuffle Writer
- 每个map任务都会产生一个shuffle数据文件,和一个Index文件
- 通过外部排序类ExternalSorter对数据进行排序
- 若map-side需要进行合并(combine)操作,数据将会按key和分区进行排序,若没有合并操作数据只会根据分区进行排序。
Spark-2.0原理分析-shuffle过程的更多相关文章
- Spark之Task原理分析
在Spark中,一个应用程序要想被执行,肯定要经过以下的步骤: 从这个路线得知,最终一个job是依赖于分布在集群不同节点中的task,通过并行或者并发的运行来完成真正的工作.由此可见 ...
- 小记--------spark的worker原理分析及源码分析
- Struts1.2,struts2.0原理分析
struts1原理: 1.首先我们表单提交到action 2.进入到web.xml 3.web.xml拦截*.do 4.交给ActionServlet 5.找到path属性,获得url 6.找到nam ...
- 小记--------spark内核架构原理分析
首先会将jar包上传到机器(服务器上) 1.在这台机器上会产生一个Application(也就是自己的spark程序) 2.然后通过spark-submit(shell) 提交程序 ...
- 彻底搞懂spark的shuffle过程(shuffle write)
什么时候需要 shuffle writer 假如我们有个 spark job 依赖关系如下 我们抽象出来其中的rdd和依赖关系: E <-------n------, ...
- Spark Shuffle 过程
本文参考:http://www.cnblogs.com/cenyuhai/p/3826227.html 在数据流动的整个过程中,最复杂最影响性能的环节,就是 Shuffle 过程,本文将参考大神的博客 ...
- Hadoop计算中的Shuffle过程(转)
Hadoop计算中的Shuffle过程 作者:左坚 来源:清华万博 时间:2013-07-02 15:04:44.0 Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解Ma ...
- spark的shuffle和原理分析
概述 Shuffle就是对数据进行重组,由于分布式计算的特性和要求,在实现细节上更加繁琐和复杂. 在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段 ...
- Spark的RDD原理以及2.0特性的介绍
转载自:http://www.tuicool.com/articles/7VNfyif 王联辉,曾在腾讯,Intel 等公司从事大数据相关的工作.2013 年 - 2016 年先后负责腾讯 Yarn ...
随机推荐
- HTML-锚点-JS跳转锚点
window.location.hash使用说明,这篇写的挺详细的 http://www.cnblogs.com/nifengs/p/5104763.html a标签的话是 name,div呢是id, ...
- 《转》Python学习(17)-python函数基础部分
http://www.cnblogs.com/BeginMan/p/3171977.html 一.什么是函数.方法.过程 推荐阅读:http://www.cnblogs.com/snandy/arch ...
- 【技术分享会】 @第三期 CSS框架 PRUE 实现自适应和响应式
Pure网址:https://purecss.cn/ 什么是响应式和自适应? .响应式:样式会随着屏幕大小改变,同一页面设备不同样式不同 .自适应:不管屏幕大小,页面的样式比例不变 响应式和自适应怎么 ...
- c++多线程——锁技巧
[转自]here 编写程序不容易,编写多线程的程序更不容易.相信编写过多线程的程序都应该有这样的一个痛苦过程,什么样的情况呢?朋友们应该看一下代码就明白了, void data_process() { ...
- LeetCode 44 Wildcard Matching(字符串匹配问题)
题目链接:https://leetcode.com/problems/wildcard-matching/?tab=Description '?' Matches any single chara ...
- 阿里云ubuntu14.4上部署gogs
以前曾经在centos上部署了gitlab,但因为买的配置比较低,实际效果并不理想,经常卡机.而且,gitlab配置相当麻烦,需要依赖很多被墙包支持.最近在用golang搞开发,顺道发现了gogs这款 ...
- 使用nginx做反代时遇到413 Request Entity Too Large的解决方法
在使用nginx做反向代理的时候,被反代的系统在上传文件的时候遇到413 错误 :Request Entity Too Large 原因是nginx限制了上传文件的大小,在nginx中可以配置最大允许 ...
- CentOS 6.4 php环境配置以及安装wordpress
1. nginx php-rpm 包升级 sudo rpm -Uvh http://download.fedoraproject.org/pub/epel/6/i386/epel-release-6- ...
- Elasticsearch笔记(一)—Elasticsearch安装配置
原文链接:https://my.oschina.net/jhao104/blog/644909 摘要: ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文 ...
- Unity3D笔记 英保通九 创建数
Unity中创建树:可以直接通过程序自动来创建树木还可以手动创建树木(本质上在我看来就是给程序自动创建的树动动”小手术“) 一.程序自动创建树木 3.1.层次视图中创建:一个平行光.摄像机.地.数并且 ...