Spark-2.0原理分析-shuffle过程
shuffle概览
shuffle过程概览
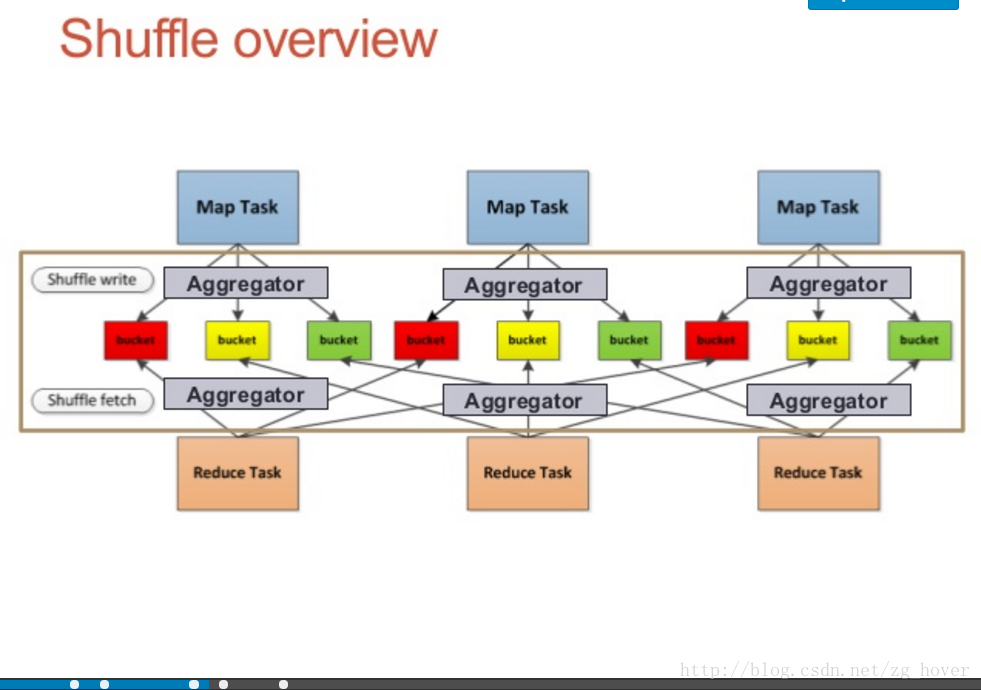
shuffle数据流概览
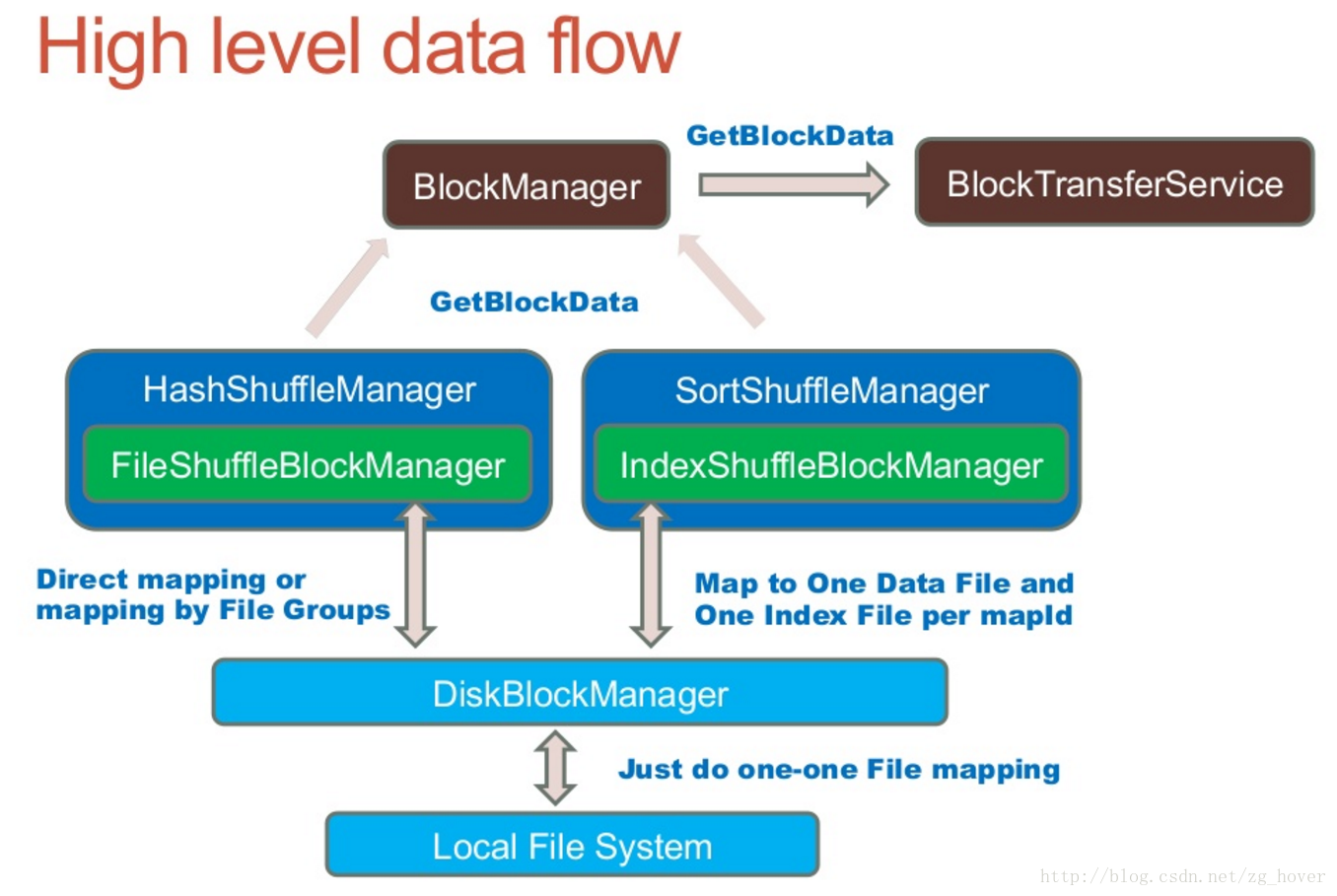
shuffle数据流
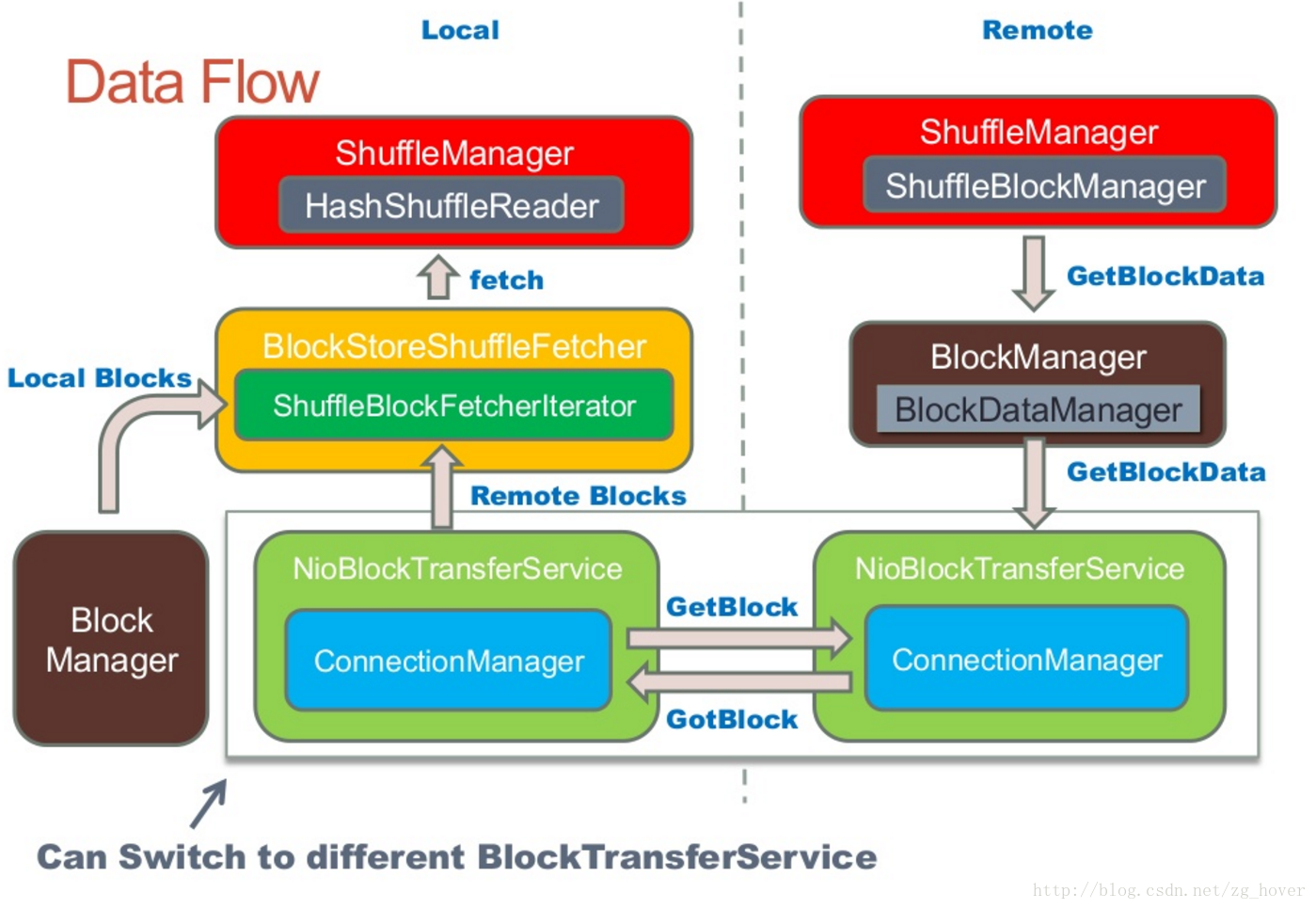
shuffle工作流程
在运行job时,spark是一个stage一个stage执行的。先把任务分成stage,在任务提交阶段会把任务形成taskset,在执行任务。
spark的DAGScheduler根据RDD的ShuffleDependency来构建Stages:
- 例如:ShuffleRDD/CoGroupedRDD有一个ShuffleDependency。
- 很多操作通过钩子函数来创建ShuffleRDD
每个ShuffleDependency会map到spark的job的一个stage,然后会导致一个shuffle过程。
为什么shuffle过程代价很大
这是由于shuffle过程可能需要完成以下过程:
- 重新进行数据分区
- 数据传输
- 数据压缩
- 磁盘I/O
shuffle的体系结构
ShuffleManager接口
shuffleManager是spark的shuffle系统的可插拔接口。ShuffleManager将会在driver和每个executor上的SparkEnv中进行创建。可以通过参数spark.shuffle.manager进行设置。
driver通过ShuffleManager来注册shuffle,并且executor通过它来读取和写入数据。
ShuffleWriter
控制shuffle数据输出逻辑。
ShuffleReader
获取shuffle过程中用于ShuffleRDD的数据。
ShuffleBlockManager
管理抽象的bucket和计算数据块之间的mapping过程。
基于sort的shuffle
sort-based的shuffle,会把输入的记录根据目标分区id(partition ids)进行排序。然后写入单个的map输出文件中。为了读取map的输出部分,Reducers获取此文件的连续区域 。当map输出的数据太大而内存无法存放时,输出的排序子集可以保存到磁盘,这些磁盘文件被合并后,生成最终的输出文件。
sort shuffle有两个不同的输出路径来产生map的输出文件:
- 序列化排序(Serialized sorting)
在使用序列化排序时,需要满足以下3个条件:- shuffle不指定聚合(aggregation)或输出排序方法。
- shuffle的序列化程序支持序列化值的重定位(KryoSerializer和Spark SQL的自定义序列化程序目前支持此操作)。
- shuffle产生小于16777216个输出分区。
- 反序列化排序(Deserialized sorting)
用来处理所有其他情况。
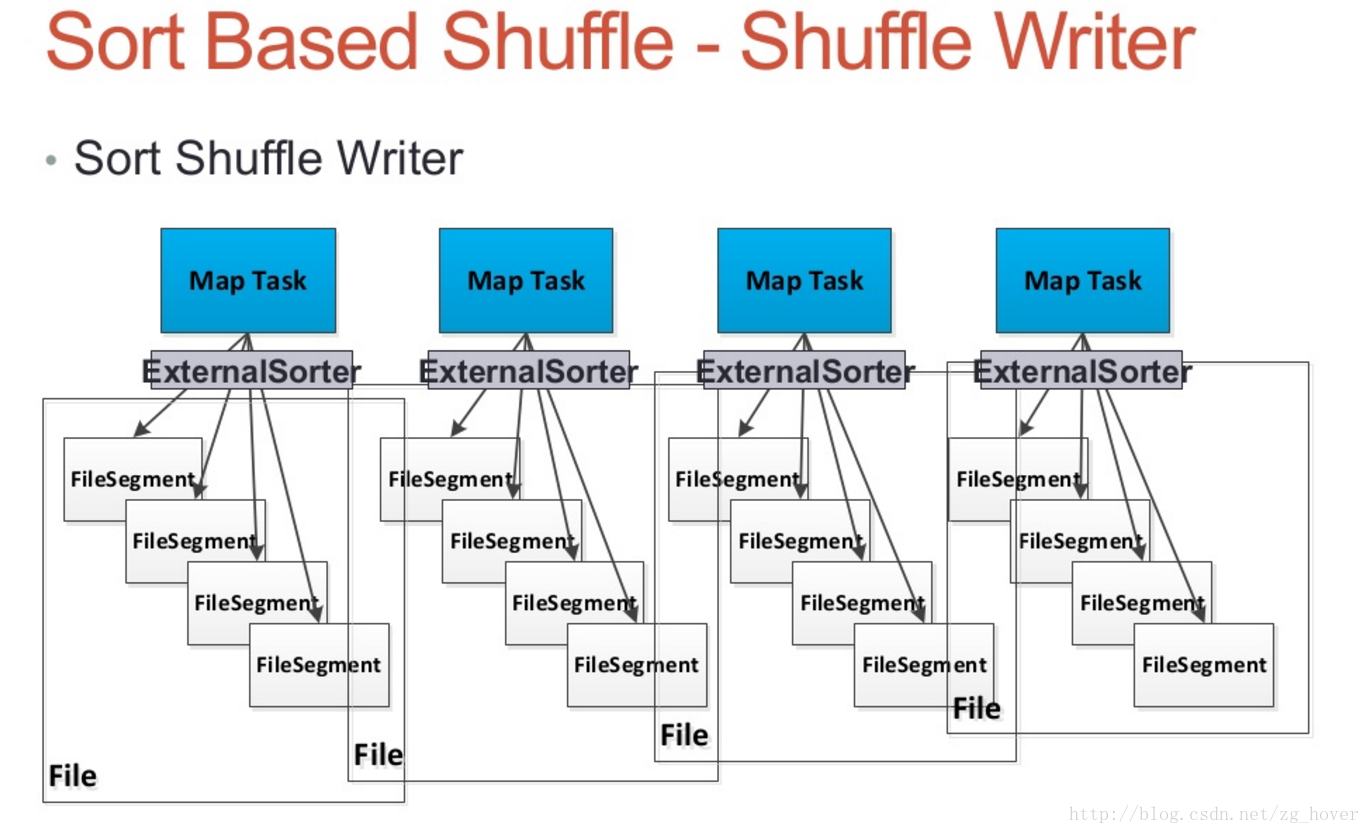
Sort Shuffle Manager
Sort Shuffle Writer
- 每个map任务都会产生一个shuffle数据文件,和一个Index文件
- 通过外部排序类ExternalSorter对数据进行排序
- 若map-side需要进行合并(combine)操作,数据将会按key和分区进行排序,若没有合并操作数据只会根据分区进行排序。
Spark-2.0原理分析-shuffle过程的更多相关文章
- Spark之Task原理分析
在Spark中,一个应用程序要想被执行,肯定要经过以下的步骤: 从这个路线得知,最终一个job是依赖于分布在集群不同节点中的task,通过并行或者并发的运行来完成真正的工作.由此可见 ...
- 小记--------spark的worker原理分析及源码分析
- Struts1.2,struts2.0原理分析
struts1原理: 1.首先我们表单提交到action 2.进入到web.xml 3.web.xml拦截*.do 4.交给ActionServlet 5.找到path属性,获得url 6.找到nam ...
- 小记--------spark内核架构原理分析
首先会将jar包上传到机器(服务器上) 1.在这台机器上会产生一个Application(也就是自己的spark程序) 2.然后通过spark-submit(shell) 提交程序 ...
- 彻底搞懂spark的shuffle过程(shuffle write)
什么时候需要 shuffle writer 假如我们有个 spark job 依赖关系如下 我们抽象出来其中的rdd和依赖关系: E <-------n------, ...
- Spark Shuffle 过程
本文参考:http://www.cnblogs.com/cenyuhai/p/3826227.html 在数据流动的整个过程中,最复杂最影响性能的环节,就是 Shuffle 过程,本文将参考大神的博客 ...
- Hadoop计算中的Shuffle过程(转)
Hadoop计算中的Shuffle过程 作者:左坚 来源:清华万博 时间:2013-07-02 15:04:44.0 Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解Ma ...
- spark的shuffle和原理分析
概述 Shuffle就是对数据进行重组,由于分布式计算的特性和要求,在实现细节上更加繁琐和复杂. 在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段 ...
- Spark的RDD原理以及2.0特性的介绍
转载自:http://www.tuicool.com/articles/7VNfyif 王联辉,曾在腾讯,Intel 等公司从事大数据相关的工作.2013 年 - 2016 年先后负责腾讯 Yarn ...
随机推荐
- Matlab 曲线拟合之polyfit与polyval函数
p=polyfit(x,y,n) [p,s]= polyfit(x,y,n) 说明:x,y为数据点,n为多项式阶数,返回p为幂次从高到低的多项式系数向量p.x必须是单调的.矩阵s用于生成预测值的误差估 ...
- WP8.1学习系列(第二十三章)——到控件的数据绑定
在本文中 先决条件 将控件绑定到单个项目 将控件绑定到对象的集合 通过使用数据模板显示控件中的项目 添加详细信息视图 转换数据以在控件中显示 相关主题 本主题介绍了如何在使用 C++.C# 或 Vis ...
- How to install Wine on Ubuntu Linux 64bit
参考地址:https://linuxconfig.org/how-to-install-wine-on-ubuntu-linux-64bit The following linux command p ...
- sencha touch JsonP 自动提示消息 masked
//公用类 Ext.define('app.util', { alternateClassName: 'util', statics: { /*为Ext.Viewport添加一个消息提示组件(需要初始 ...
- sencha touch list 选择插件,可记忆已选项,可分组全选
选择记忆功能参考:https://market.sencha.com/extensions/ext-plugin-rememberselection 插件代码: /* * 记住列表选择状态 * 如果分 ...
- yum安装pip,pip安装compose
#centos7 yum -y install epel-release yum -y install python-pip pip install --upgrade pip pip install ...
- ms转成00:00:00的时间格式化
毫秒转成 00:00:00的时间格式 比如1000毫秒转成00:00:01 /** * 格式化邀请的时间 * @param time ms */ public static formatTime(ti ...
- 23种设计模式之访问者模式(Visitor)
访问者模式是一种对象的行为性模式,用于表示一个作用于某对象结构中的各元素的操作,它使得用户可以再不改变各元素的类的前提下定义作用于这些元素的新操作.访问者模式使得增加新的操作变得很容易,但在一定程度上 ...
- 【转】单片机中volatile定义的作用详解
传送门:http://www.eeworld.com.cn/mcu/2011/0411/article_3928.html 一个定义为volatile的变量是说这变量可能会被意想不到地改变,这样,编译 ...
- Saltstack实战之无master和多master
如果不想依赖master可以设置为无master vim /etc/salt/minion 就可以通过minion来安装一个salt-master了(下来查资料做,关闭salt-minion进程因为不 ...