(转)Nuts and Bolts of Applying Deep Learning

Nuts and Bolts of Applying Deep Learning
Sep 26, 2016
This weekend was very hectic (catching up on courses and studying for a statistics quiz), but I managed to squeeze in some time to watch the Bay Area Deep Learning School livestream on YouTube. For those of you wondering what that is, BADLS is a 2-day conference hosted at Stanford University, and consisting of back-to-back presentations on a variety of topics ranging from NLP, Computer Vision, Unsupervised Learning and Reinforcement Learning. Additionally, top DL software libraries were presented such as Torch, Theano and Tensorflow.
There were some super interesting talks from leading experts in the field: Hugo Larochelle from Twitter, Andrej Karpathy from OpenAI, Yoshua Bengio from the Université de Montreal, and Andrew Ng from Baidu to name a few. Of the plethora of presentations, there was one somewhat non-technical one given by Andrew that really piqued my interest.
In this blog post, I’m gonna try and give an overview of the main ideas outlined in his talk. The goal is to pause a bit and examine the ongoing trends in Deep Learning thus far, as well as gain some insight into applying DL in practice.
By the way, if you missed out on the livestreams, you can still view them at the following: Day 1 and Day 2.
Table of Contents:
- Major Deep Learning Trends
- End-to-End Deep Learning
- Bias-Variance Tradeoff
- Human-level Performance
- Personal Advice
Major Deep Learning Trends
Why do DL algorithms work so well? According to Ng, with the rise of the Internet, Mobile and IOT era, the amount of data accessible to us has greatly increased. This correlates directly to a boost in the performance of neural network models, especially the larger ones which have the capacity to absorb all this data.
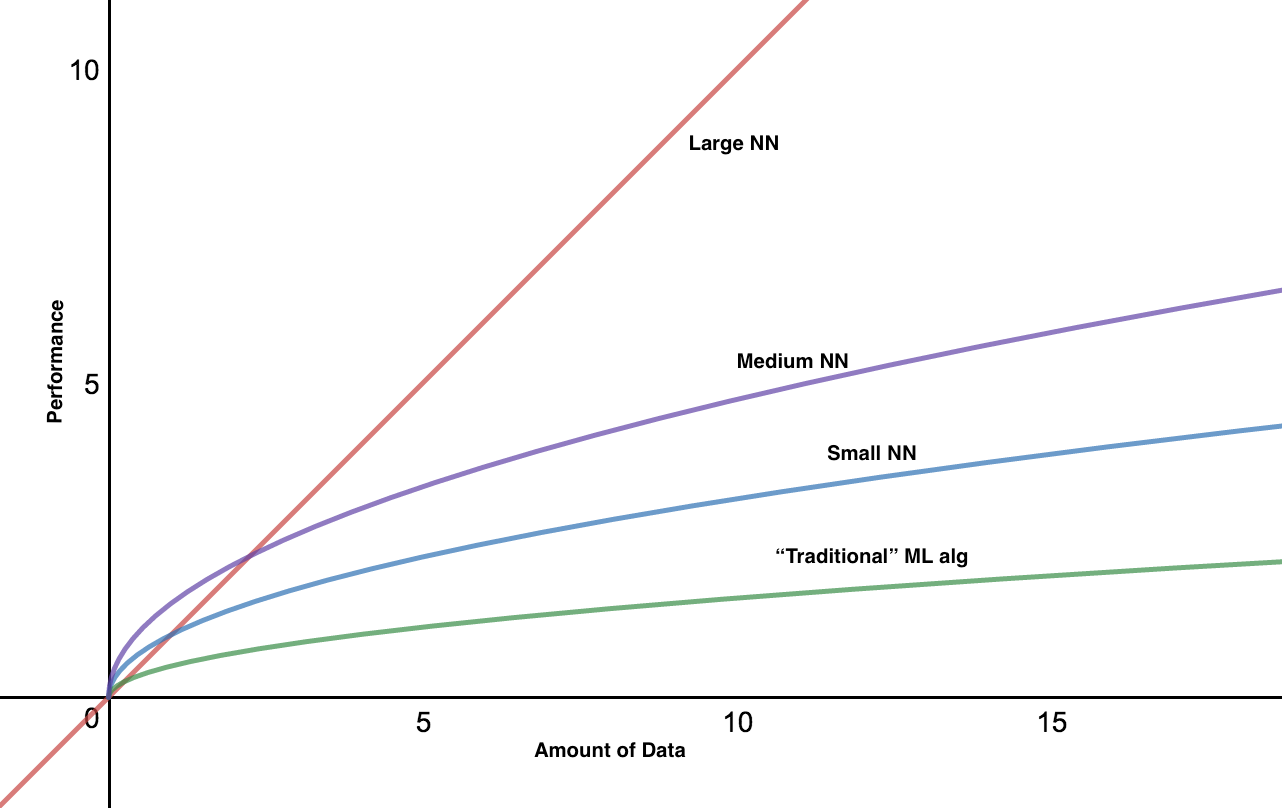
However, in the small data regime (left-hand side of the x-axis), the relative ordering of the algorithms is not that well defined and really depends on who is more motivated to engineer their features better, or refine and tune the hyperparameters of their model.
Thus this trend is more prevalent in the big data realm where hand engineering effectively gets replaced by end-to-end approaches and bigger neural nets combined with a lot of data tend to outperform all other models.
Machine Learning and HPC team. The rise of big data and the need for larger models has started to put pressure on companies to hire a Computer Systems team. This is because some of the HPC (high-performance computing) applications require highly specialized knowledge and it is difficult to find researchers and engineers with sufficient knowledge in both fields. Thus, cooperation from both teams is the key to boosting performance in AI companies.
Categorizing DL models. Work in DL can be categorized in the following 4 buckets:

Most of the value in the industry today is driven by the models in the orange blob (innovation and monetization mostly) but Andrew believes that unsupervised deep learning is a super-exciting field that has loads of potential for the future.
The rise of End-to-End DL
A major improvement in the end-to-end approach has been the fact that outputs are becoming more and more complicated. For example, rather than just outputting a simple class score such as 0 or 1, algorithms are starting to generate richer outputs: images like in the case of GAN’s, full captions with RNN’s and most recently, audio like in DeepMind’s WaveNet.
So what exactly does end-to-end training mean? Essentially, it means that AI practitioners are shying away from intermediate representations and going directly from one end (raw input) to the other end (output) Here’s an example from speech recognition.

Are there any disadvantages to this approach? End-to-end approaches are data hungry meaning they only perform well when provided with a huge dataset of labelled examples. In practice, not all applications have the luxury of large labelled datasets so other approaches which allow hand-engineered information and field expertise to be added into the model have gained the upper hand. As an example, in a self-driving car setting, going directly from the raw image to the steering direction is pretty difficult. Rather, many features such as trajectory and pedestrian location are calculated first as intermediate steps.
The main take-away from this section is that we should always be cautious of end-to-end approaches in applications where huge data is hard to come by.
Bias-Variance Tradeoff
Splitting your data. In most deep learning problems, train and test come from different distributions. For example, suppose you are working on implementing an AI powered rearview mirror and have gathered 2 chunks of data: the first, larger chunk comes from many places (could be partly bought, and partly crowdsourced) and the second, much smaller chunk is actual car data.
In this case, splitting the data into train/dev/test can be tricky. One might be tempted to carve the dev set out of the training chunk like in the first example of the diagram below. (Note that the chunk on the left corresponds to data mined from the first distribution and the one on the right to the one from the second distribution.)

This is bad because we usually want our dev and test to come from the same distribution. The reason for this is that because a part of the team will be spending a lot of time tuning the model to work well on the dev set, if the test set were to turn out very different from the dev set, then pretty much all the work would have been wasted effort.
Hence, a smarter way of splitting the above dataset would be just like the second line of the diagram. Now in practice, Andrew recommends creating dev sets from both data distributions: a train-dev and test-dev set. In this manner, any gap between the different errors can help you tackle the problem more clearly.

Flowchart for working with a model. Given what we have described above, here’s a simplified flowchart of the actions you should take when confronted with training/tuning a DL model.

The importance of data synthesis. Andrew also stressed the importance of data synthesis as part of any workflow in deep learning. While it may be painful to manually engineer training examples, the relative gain in performance you obtain once the parameters and the model fit well are huge and worth your while.
Human-level Performance
One of the very important concepts underlined in this lecture was that of human-level performance. In the basic setting, DL models tend to plateau once they have reached or surpassed human-level accuracy. While it is important to note that human-level performance doesn’t necessarily coincide with the golden bayes error rate, it can serve as a very reliable proxy which can be leveraged to determine your next move when training your model.
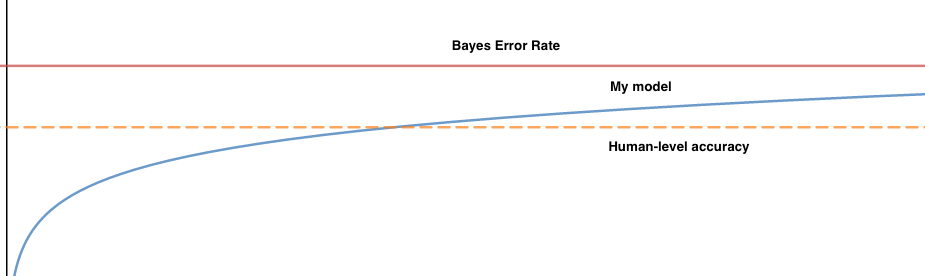
Reasons for the plateau. There could be a theoretical limit on the dataset which makes further improvement futile (i.e. a noisy subset of the data). Humans are also very good at these tasks so trying to make progress beyond that suffers from diminishing returns.
Here’s an example that can help illustrate the usefulness of human-level accuracy. Suppose you are working on an image recognition task and measure the following:
- Train error: 8%
- Dev Error: 10%
If I were to tell you that human accuracy for such a task is on the order of 1%, then this would be a blatant bias problem and you could subsequently try increasing the size of your model, train longer etc. However, if I told you that human-level accuracy was on the order of 7.5%, then this would be more of a variance problem and you’d focus your efforts on methods such as data synthesis or gathering data more similar to the test.
By the way, there’s always room for improvement. Even if you are close to human-level accuracy overall, there could be subsets of the data where you perform poorly and working on those can boost production performance greatly.
Finally, one might ask what is a good way of defining human-level accuracy. For example, in the following image diagnosis setting, ignoring the cost of obtaining data, how should one pick the criteria for human-level accuracy?
- typical human: 5%
- general doctor: 1%
- specialized doctor: 0.8%
- group of specialized doctors: 0.5%
The answer is always the best accuracy possible. This is because, as we mentioned earlier, human-level performance is a proxy for the bayes optimal error rate, so providing a more accurate upper bound to your performance can help you strategize your next move.
Personal Advice
Andrew ended the presentation with 2 ways one can improve his/her skills in the field of deep learning.
- Practice, Practice, Practice: compete in Kaggle competitions and read associated blog posts and forum discussions.
- Do the Dirty Work: read a lot of papers and try to replicate the results. Soon enough, you’ll get your own ideas and build your own models.
(转)Nuts and Bolts of Applying Deep Learning的更多相关文章
- 《Applying Deep Learning to Answer Selection: A Study And an Open Task》文章理解小结
本篇论文是2015年的IBM watson团队的. 论文地址: 这是一篇关于QA问题的一篇论文: 相关论文讲解1.https://www.jianshu.com/p/48024e9f7bb22.htt ...
- Decision Boundaries for Deep Learning and other Machine Learning classifiers
Decision Boundaries for Deep Learning and other Machine Learning classifiers H2O, one of the leading ...
- What are some good books/papers for learning deep learning?
What's the most effective way to get started with deep learning? 29 Answers Yoshua Bengio, ...
- Deep learning:四十九(RNN-RBM简单理解)
前言: 本文主要是bengio的deep learning tutorial教程主页中最后一个sample:rnn-rbm in polyphonic music. 即用RNN-RBM来model复调 ...
- (转)分布式深度学习系统构建 简介 Distributed Deep Learning
HOME ABOUT CONTACT SUBSCRIBE VIA RSS DEEP LEARNING FOR ENTERPRISE Distributed Deep Learning, Part ...
- (转)WHY DEEP LEARNING IS SUDDENLY CHANGING YOUR LIFE
Main Menu Fortune.com E-mail Tweet Facebook Linkedin Share icons By Roger Parloff Illustration ...
- Advice for applying Machine Learning
https://jmetzen.github.io/2015-01-29/ml_advice.html Advice for applying Machine Learning This post i ...
- (转) Deep Learning in a Nutshell: Core Concepts
Deep Learning in a Nutshell: Core Concepts Share: Posted on November 3, 2015by Tim Dettmers 7 Comm ...
- (转)The 9 Deep Learning Papers You Need To Know About (Understanding CNNs Part 3)
Adit Deshpande CS Undergrad at UCLA ('19) Blog About The 9 Deep Learning Papers You Need To Know Abo ...
随机推荐
- (1.2)mysql 索引概念
索引的存储分类:mysql目前提供了以下4种索引 [1]B-Tree索引:最常见的索引类型,大部分引擎都支持B树索引 [2]HASH索引:只有Memory引擎支持,使用场景简单 [3]R-Tree索引 ...
- windows平台mysql密码设置
登录mysql默认没有指定账号 查看默认账号是谁 select user(); mysql> select user();+----------------+| user() |+------- ...
- vue使用resource传参数
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- [py]django第三方分页器django-pure-pagination实战
第三方分页模块: django-pure-pagination 是基于django的pagination做的一款更好用的分页器 参考 配置django-pure-pagination模块 安装 pip ...
- sklearn_Logistic Regression
一.什么是逻辑回归? 一种名为“回归”的线性分类器,其本质是由线性回归变化而来的,一种广泛使用于分类问题中的广义回归算法 面试高危问题:Sigmoid函数的公式和性质 Sigmoid函数是一个S型的函 ...
- testng入门教程16数据驱动(把数据写在xml)
testng入门教程16数据驱动(把数据写在xml) testng入门教程16数据驱动(把数据写在xml)把数据写在xml文件里面,在xml文件右键选择runas---testng执行 下面是case ...
- 接口自动化测试框架搭建 – Java+TestNG 测试Restful service
接口自动化测试 – Java+TestNG 测试 Restful Web Service 关键词:基于Rest的Web服务,接口自动化测试,数据驱动测试,测试Restful Web Service, ...
- CXF创建webservice客户端和服务端
转 一.CXF的介绍 Apache CXF是一个开源的WebService框架,CXF大大简化了Webservice的创建,同时它继承了XFire的传统,一样可以和spring天然的进行无缝的集成.C ...
- Perl中的哈希(四)
Perl中的哈希数据结构.相比较于数组,这种数据结构对于数据查找和统计更加方便. 一个特殊的哈希,%ENV,表示当前terminal下,通过setenv设置的variable的键值. 键:环境变量名, ...
- eclipse配置汇总
1.背景色调节 general->editor->texteditor->选中background RGB: 85 90 205 2.java vm参数设置 VmAguments中 ...