Kafka 之 入门
摘要: 最近研究采集层,对Kafka做了一个研究。分为入门,中级,高级步步进阶。本篇主要介绍基本概念,适用场景。
一、入门
1. 简介
Kafka is a distributed, partitioned, replicated commit log service。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。

下面这张图描述更准确。
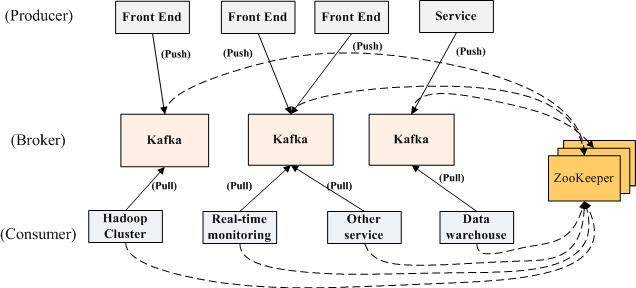
主要特性:
1)消息持久化 要从大数据中获取真正的价值,那么不能丢失任何信息。Apache Kafka设计上是时间复杂度O(1)的磁盘结构,它提供了常量时间的性能,即使是存储海量的信息(TB级)。 2)高吞吐 记住大数据,Kafka的设计是工作在标准硬件之上,支持每秒数百万的消息。 3)分布式 Kafka明确支持在Kafka服务器上的消息分区,以及在消费机器集群上的分发消费,维护每个分区的排序语义。 4)多客户端支持 Kafka系统支持与来自不同平台(如java、.NET、PHP、Ruby或Python等)的客户端相集成。 5)实时 生产者线程产生的消息对消费者线程应该立即可见,此特性对基于事件的系统(比如CEP系统)是至关重要的。
2. 概念
Topics/logs
一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。

kafka和JMS实现(activeMQ)不同的是:即使消息被消费,消息仍然不会被立即删除.日志文件将会根据broker中的配置要求,保留一定的时间之后删除;比如log文件保留2天,那么两天后,文件会被清除,无论其中的消息是否被消费.kafka通过这种简单的手段,来释放磁盘空间,以及减少消息消费之后对文件内容改动的磁盘IO开支.
对于consumer而言,它需要保存消费消息的offset,对于offset的保存和使用,有consumer来控制;当consumer正常消费消息时,offset将会"线性"的向前驱动,即消息将依次顺序被消费.事实上consumer可以使用任意顺序消费消息,它只需要将offset重置为任意值..(offset将会保存在zookeeper中,参见下文)
kafka集群几乎不需要维护任何consumer和producer状态信息,这些信息有zookeeper保存;因此producer和consumer的客户端实现非常轻量级,它们可以随意离开,而不会对集群造成额外的影响.
partitions的设计目的有多个.最根本原因是kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存;可以将一个topic切分多任意多个partitions,来消息保存/消费的效率.此外越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力.(具体原理参见下文).
Distribution
一个Topic的多个partitions,被分布在kafka集群中的多个server上;每个server(kafka实例)负责partitions中消息的读写操作;此外kafka还可以配置partitions需要备份的个数(replicas),每个partition将会被备份到多台机器上,以提高可用性.
基于replicated方案,那么就意味着需要对多个备份进行调度;每个partition都有一个server为"leader";leader负责所有的读写操作,如果leader失效,那么将会有其他follower来接管(成为新的leader);follower只是单调的和leader跟进,同步消息即可..由此可见作为leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定.
Producers
Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于"round-robin"方式或者通过其他的一些算法等.
Consumers
本质上kafka只支持Topic.每个consumer属于一个consumer group;反过来说,每个group中可以有多个consumer.发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费.
如果所有的consumer都具有相同的group,这种情况和queue模式很像;消息将会在consumers之间负载均衡.
如果所有的consumer都具有不同的group,那这就是"发布-订阅";消息将会广播给所有的消费者.
在kafka中,一个partition中的消息只会被group中的一个consumer消费;每个group中consumer消息消费互相独立;我们可以认为一个group是一个"订阅"者,一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息.kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的.事实上,从Topic角度来说,消息仍不是有序的.
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息.
Guarantees
1) 发送到partitions中的消息将会按照它接收的顺序追加到日志中
2) 对于消费者而言,它们消费消息的顺序和日志中消息顺序一致.
3) 如果Topic的"replication factor"为N,那么允许N-1个kafka实例失效.
3. 适用场景
1、Messaging
对于一些常规的消息系统,kafka是个不错的选择;partitons/replication和容错,可以使kafka具有良好的扩展性和性能优势.不过到目前为止,我们应该很清楚认识到,kafka并没有提供JMS中的"事务性""消息传输担保(消息确认机制)""消息分组"等企业级特性;kafka只能使用作为"常规"的消息系统,在一定程度上,尚未确保消息的发送与接收绝对可靠(比如,消息重发,消息发送丢失等)
2、Websit activity tracking
kafka可以作为"网站活性跟踪"的最佳工具;可以将网页/用户操作等信息发送到kafka中.并实时监控,或者离线统计分析等
3、Metrics
Kafka通常被用于可操作的监控数据。这包括从分布式应用程序来的聚合统计用来生产集中的运营数据提要。
4、Log Aggregation
kafka的特性决定它非常适合作为"日志收集中心";application可以将操作日志"批量""异步"的发送到kafka集群中,而不是保存在本地或者DB中;kafka可以批量提交消息/压缩消息等,这对producer端而言,几乎感觉不到性能的开支.此时consumer端可以使hadoop等其他系统化的存储和分析系统.
4. 命令
1. 启动Server
Kafka 依赖 ZK 服务
nohup bin/kafka-server-start.sh config/server.properties &
2. 创建Topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic page_visits
3. 查看命令
bin/kafka-topics.sh --list --zookeeper localhost:2181
4. 发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic page_visits
5. 消费消息
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic page_visits --from-beginning
6. 多 Broker 方式
bin/kafka-server-start.sh config/server-1.properties &
bin/kafka-server-start.sh config/server-2.properties &
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic visits
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic visits
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic visits
my message test1
my message test2
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic visits
7. 停止服务
pkill -9 -f config/server.properties
8. 删除无用的topic
bin/kafka-run-class.sh kafka.admin.DeleteTopicCommand --topic visits --zookeeper sjxt-hd02:2181,sjxt-hd03:2181,sjxt-hd04:2181
beta in 0.8.1
bin/kafka-topics.sh --zookeeper zk_host:port --delete --topic my_topic_nameKafka 之 入门的更多相关文章
- 【转】kafka概念入门[一]
转载的,原文:http://www.cnblogs.com/intsmaze/p/6386616.html ---------------------------------------------- ...
- docker安装kafka快速入门
docker安装kafka快速入门 1.安装zookeeper docker search zookeeperdocker pull zookeeperdocker run -d -v /home/s ...
- Kafka从入门到放弃(三) —— 详说生产者
上一篇对Kafka做了简单介绍,还没看的朋友可以点击下方链接. Kafka从入门到放弃(一) -- 初识别Kafka 消息中间件必须与生产者和消费者一起存在才有意义,这次先来聊聊Kafka的生产者. ...
- Kafka从入门到放弃(三)—— 详说消费者
之前介绍了Kafka以及生产者,包括它的一些特性和参数,这回写一下消费者. 之前没看得可以点击链接阅读. Kafka从入门到放弃(一) -- 初识Kafka Kafka从入门到放弃(二) -- 详说生 ...
- kafka从入门到了解
kafka从入门到了解 一.什么是kafka Apache Kafka是Apache软件基金会的开源的流处理平台,该平台提供了消息的订阅与发布的消息队列,一般用作系统间解耦.异步通信.削峰填谷等作用. ...
- kafka快速入门(官方文档)
第1步:下载代码 下载 1.0.0版本并解压缩. > tar -xzf kafka_2.11-1.0.0.tgz > cd kafka_2.11-1.0.0 第2步:启动服务器 Kafka ...
- Kafka【入门】就这一篇!
为获得更好的阅读体验,建议您访问原文地址:传送门 前言:在之前的文章里面已经了解到了「消息队列」是怎么样的一种存在(传送门),Kafka 作为当下流行的一种中间件,我们现在开始学习它! 一.Kafka ...
- Kafka使用入门教程
转载自http://www.linuxidc.com/Linux/2014-07/104470.htm 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自 ...
- Kafka使用入门教程 简单介绍
介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语: Kafka将消息以 ...
随机推荐
- 【教程】ubuntu下配置nvc详细教程
Preface 虽然以前在windows上远控linux都是用的FTP+CRT,不过有些时候还是不太方便,比如不能用IDE对程序进行调试,现在就来配置下VNC,过程中出了些错误,上网查询时发现很多解决 ...
- 转css中文英文换行、禁止换行、显示省略号
css中文英文换行.禁止换行.显示省略号 原创 2016年08月09日 14:20:01 word-break:break-all;只对英文起作用,以字母作为换行依据 word-wrap:brea ...
- 旧的flex
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 三者互ping,PC,虚拟机,uboot,nfs网络文件系统搭建
要想实现三者互ping,韦老师虽然专门出了视频说明,但是在自己配置过程还是出现了问题,这里记录一下解决办法,虽然我也不知道原因,但是解决了出现的问题也实现了三者互ping. 首先,我的硬件设备是PC通 ...
- DLL封装Interface(接口)(D2007+win764位)
相关资料: http://blog.csdn.net/liangpei2008/article/details/5394911 结果注意: 1.函数的传参方向必须一至. DLL实例代码: ZJQInt ...
- order by name 注入
order by name id id是一个注入点 可以利用if语句进行注入 order by name ,if(1=1,1,select 1 from information_schema.tabl ...
- [转]bigdecimal 保留小数位
原文地址:https://www.cnblogs.com/liqforstudy/p/5652517.html public class test1_format { public static vo ...
- RedHat 6 yum 使用网易源
. . . . . 刚装好了 RedHat 6 系统,但是使用 yum 的时候总是提示 nothing to do,并且什么都做不了.后来经过一番搜索才知道,红帽的 yum 在线更新是收费的,而且必须 ...
- WPF打包工具
找到一款相当不错的WPF项目的打包工具:advanced installer 工具简单易用,有破/解版,还可以把项目依赖库一起打到一个包中. 用法参考: https://www.cnblogs.com ...
- Tomcat性能优化(三) Executor配置
http://hello-nick-xu.iteye.com/blog/2113853 http://blog.chinaunix.net/uid-12115233-id-3358004.html